Play with a live Neptune project -> Take a tour 📈

Implementing Customer Segmentation Using Machine Learning [Beginners Guide]
These days, you can personalize everything. There’s no one-size-fits-all approach. But, for business, this is actually a great thing. It creates a lot of space for healthy competition and opportunities for companies to get creative about how they acquire and retain customers.
One of the fundamental steps towards better personalization is customer segmentation. This is where personalization starts, and proper segmentation will help you make decisions regarding new features, new products, pricing, marketing strategies, even things like in-app recommendations.
But, doing segmentation manually can be exhausting. Why not employ machine learning to do it for us? In this article, I’ll tell you how to do just that.
What is customer segmentation
Customer segmentation simply means grouping your customers according to various characteristics (for example grouping customers by age).
It’s a way for organizations to understand their customers. Knowing the differences between customer groups, it’s easier to make strategic decisions regarding product growth and marketing.
The opportunities to segment are endless and depend mainly on how much customer data you have at your use. Starting from the basic criteria, like gender, hobby, or age, it goes all the way to things like “time spent of website X” or “time since user opened our app”.
There are different methodologies for customer segmentation, and they depend on four types of parameters:
- geographic,
- demographic,
- behavioral,
- psychological.
Geographic customer segmentation is very simple, it’s all about the user’s location. This can be implemented in various ways. You can group by country, state, city, or zip code.
Demographic segmentation is related to the structure, size, and movements of customers over space and time. Many companies use gender differences to create and market products. Parental status is another important feature. You can obtain data like this from customer surveys.
Behavioral customer segmentation is based on past observed behaviors of customers that can be used to predict future actions. For example, brands that customers purchase, or moments when they buy the most. The behavioral aspect of customer segmentation not only tries to understand reasons for purchase but also how those reasons change throughout the year.
Psychological segmentation of customers generally deals with things like personality traits, attitudes, or beliefs. This data is obtained using customer surveys, and it can be used to gauge customer sentiment.
Advantages of customer segmentation
Implementing customer segmentation leads to plenty of new business opportunities. You can do a lot of optimization in:
- budgeting,
- product design,
- promotion,
- marketing,
- customer satisfaction.
Let’s discuss these benefits in more depth.
Nobody likes to invest in campaigns that don’t generate any new customers. Most companies don’t have huge marketing budgets, so that money has to be spent right. Segmentation enables you to target customers with the highest potential value first, so you get the most out of your marketing budget.
- Product design
Customer segmentation helps you understand what your users need. You can identify the most active users/customers, and optimize your application/offer towards their needs.
Properly implemented customer segmentation helps you plan special offers and deals. Frequent deals have become a staple of e-commerce and commercial software in the past few years. If you reach a customer with just the right offer, at the right time, there’s a huge chance they’re going to buy. Customer segmentation will help you tailor your special offers perfectly.
The marketing strategy can be directly improved with segmentation because you can plan personalized marketing campaigns for different customer segments, using the channels that they use the most.
- Customer satisfaction
By studying different customer groups, you learn what they value the most about your company. This information will help you create personalized products and services that perfectly fit your customers’ preferences.
In the next section, we’re going to discuss why machine learning for customer segmentation.
Machine Learning for customer segmentation
Machine learning methodologies are a great tool for analyzing customer data and finding insights and patterns. Artificially intelligent models are powerful tools for decision-makers. They can precisely identify customer segments, which is much harder to do manually or with conventional analytical methods.
There are many machine learning algorithms, each suitable for a specific type of problem. One very common machine learning algorithm that’s suitable for customer segmentation problems is the k-means clustering algorithm . There are other clustering algorithms as well such as DBSCAN, Agglomerative Clustering, and BIRCH, etc.
Why would you implement machine learning for customer segmentation?
Manual customer segmentation is time-consuming. It takes months, even years to analyze piles of data and find patterns manually. Also if done heuristically, it may not have the accuracy to be useful as expected.
Customer segmentation used to be done manually and wasn’t too precise. You’d manually create and populating different data tables, and analyze the data like a detective with a looking glass. Now, it’s much better (and relatively easy thanks to rapid progress in ML) to just use machine learning, which can free up your time to focus on more demanding problems that require creativity to solve.
Ease of retraining
Customer Segmentation is not a “develop once and use forever” type of project. Data is ever-changing, trends oscillate, everything keeps changing after your model is deployed. Usually, more labeled data becomes available after development, and it’s a great resource for improving the overall performance of your model.
There are many ways to update customer segmentation models, but here are the two main approaches:
- Use the old model as the starting point and retrain it.
- Keep the existing model and combine its output with a new model.
Better scaling
Machine learning models deployed in production support scalability, thanks to cloud infrastructure. These models are quite flexible for future changes and feedback. For example, consider a company that has 10000 customers today, and they’ve implemented a customer segmentation model. After a year, if the company has 1 million customers, then ideally we don’t need to create a separate project to handle this increased data. Machine Learning models have the inherent capability to handle more data and scale in production.
Higher accuracy
The value of an optimal number of clusters for given customer data is easy to find using machine learning methods like the elbow method. Not only the optimal number of clusters but also the performance of the model is far better when we use machine learning.
F1 Score vs ROC AUC vs Accuracy vs PR AUC: Which Evaluation Metric Should You Choose?
Exploring customer dataset and its features
Let’s analyze a customer dataset . Our dataset has 24,000 data points and four features. The features are:
- Customer ID – This is the id of a customer for a particular business.
- Products Purchased – This feature represents the number of products purchased by a customer in a year.
- Complaints – This column value indicates the number of complaints made by the customer in the last year
- Money Spent – This column value indicates the amount of money paid by the customer over the last year.

In the upcoming section, we’ll pre-process this dataset.
Pre-processing the dataset
Before feeding the data to the k-means clustering algorithm, we need to pre-process the dataset. Let’s implement the necessary pre-processing for the customer dataset.

Moving on, we’ll implement our k-means clustering algorithm in Python.
Might be useful
A Comprehensive Guide to Data Preprocessing
Implementing K-means clustering in Python
K-Means clustering is an efficient machine learning algorithm to solve data clustering problems. It’s an unsupervised algorithm that’s quite suitable for solving customer segmentation problems. Before we move on, let’s quickly explore two key concepts
Unsupervised Learning
Unsupervised machine learning is quite different from supervised machine learning. It’s a special kind of machine learning algorithm that discovers patterns in the dataset from unlabelled data.
Unsupervised machine learning algorithms can group data points based on similar attributes in the dataset. One of the main types of unsupervised models is clustering models.
Note that, supervised learning helps us produce an output from the previous experience.
Clustering algorithms
A clustering machine learning algorithm is an unsupervised machine learning algorithm. It’s used for discovering natural groupings or patterns in the dataset. It’s worth noting that clustering algorithms just interpret the input data and find natural clusters in it.
Some of the most popular clustering algorithms are:
- K-Means Clustering
- Agglomerative Hierarchical Clustering
- Expectation-Maximization (EM) Clustering
- Density-Based Spatial Clustering
- Mean-Shift Clustering
In the following section, we’re going to analyze the customer segmentation problem using the k-means clustering algorithm and machine learning. However, before that, let’s quickly discuss why we’re using the k-means clustering algorithm.
Why use K-means clustering for customer segmentation?
Unlike supervised learning algorithms, K-means clustering is an unsupervised machine learning algorithm. This algorithm is used when we have unlabelled data. Unlabelled data means input data without categories or groups provided. Our customer segmentation data is like this for this problem.
The algorithm discovers groups (cluster) in the data, where the number of clusters is represented by the K value. The algorithm acts iteratively to assign each input data to one of K clusters, as per the features provided. All of this makes k-means quite suitable for the customer segmentation problem.
Given a set of data points are grouped as per feature similarity. The output of the K-means clustering algorithm is:
- The centroids values for K clusters,
- Labels for each input data point.
At the end of implementation, we’re going to get output such as a group of clusters along with which customer belongs to which cluster.
First, we need to implement the required Python libraries as shown in the table below.
We’ve imported the pandas, NumPy sklearn, plotly and matplotlib libraries. Pandas and NumPy are used for data wrangling and manipulation, sklearn is used for modelling, and plotly along with matplotlib will be used to plot graphs and images.
After importing the library, our next step is to load the data in the pandas data frame. For this, we’re going to use the read_csv method of pandas.

After loading the data, we need to define the K- means model. This is done with the help of the KMeans class that we imported from sklearn, as shown in the code below.
After defining the model, we want to train is using a training dataset. This is implemented with the use of the fit method, as shown in the code below.
Note that we’re passing three features to the fit method, namely products_purchased, complains, and money_spent.
Though we have trained a K-means model up to these points, we haven’t found the optimal number of clusters required in this case of customer segmentation. Finding the optimal number of clusters, for the given dataset is important for producing a high-performant k-means clustering model.
In the upcoming section, we’re going to find the optimal number of clusters of the given dataset and then re-train the k-means clustering model with these optimal values of k. This will produce our final model.
Finding the optimal number of clusters
Finding the optimal number of clusters is one of the key tasks when implementing a k-means clustering algorithm. It’s worth noting that a k-means clustering model might converge for any value of K, but at the same time, not all values of K will produce the best model.
For some datasets, data visualization can help understand the optimal number of clusters, but this doesn’t apply to all datasets. We have a few methods, such as the elbow method, gap statistic method, and average silhouette method, to assess the optimal number of clusters for a given dataset. We’ll discuss them one by one.
- The elbow method finds the value of the optimal number of clusters using the total within-cluster sum of square values. This represents how spread-apart the generated clusters are from one another. In this case, the K-means algorithm is evaluated for several values of k, and the within-cluster sum of square values is calculated for each value of k. After this, we plot the K versus the sum of square values. After analyzing this graph, the number of clusters is selected, so that adding a new cluster doesn’t change the values of the sum of square values significantly.
- Average silhouette method is a measure of how well each data point fits its corresponding cluster. This method evaluates the quality of clustering. As a general rule, a high average silhouette width denotes better clustering output.
- Gap statistic method is a measure of the value of gap statistics. Gap statistics is the difference between the total intracluster changes for various values of k compared to their expected values. This calculation is done using the null reference distribution of data points. The optimal number of clusters is the value that maximizes the value of gap statistics.
We’re going to use the elbow method. The K-means clustering algorithm clusters data by separating given data points in k groups of equal variances. This effectively minimizes a parameter named inertia. Inertia is nothing but within-cluster sum-of-squares distances in this case.
When we use the elbow method, we gradually increase the number of clusters from 2 until we reach the number of clusters where adding more clusters won’t cause a significant drop in the values of inertia.
The stage at this number of clusters is called the elbow of the clustering model. We’ll see that in our case it’s K =5.
For implementing the elbow method, the below function named “try_different_clusters” is created first. It takes two values as input:
- K (number of clusters),
- data (input data).
The method try_different_clusters is called using the below code, where we pass the values of K from 1 to 12 and calculate the inertia for each value of k.
Using the below code, we plot the value of K (on the x-axis) against corresponding values of inertia on the Y-axis.
We can generate the below plot using the above code. The elbow of the code is at K=5. We have chosen 5 as if we increase the number of clusters to more than 5, there is very small change in the inertia or sum of the squared distance.

Optimal value of K = 5
The stage at which the number of clusters is optimal is called the elbow of the clustering model. For example, in the below image, the elbow is at five clusters (K =5). Adding more than 5 clusters will cause the creation of an inefficient or less performant clustering model.
As discussed before, we need to train the k-means clustering model again with the optimal number of clusters found.
Note that we’re using the fit_predict method to train the model.
In the next section, we’re going to discuss how to visualize customer segmentation clusters in three dimensions.
Visualizing customer segments
In this section, we’ll be implementing some code using plotly express. This way we’ll visualize the clusters in three dimensions, formed by our k-means algorithm. Plotly express is a library based on plotly that works on several types of datasets and generates highly-styled plots.
First, let’s add a new column named ‘clusters’ to the existing customer data dataset. This column will be able to tell which customer belongs to what cluster.
Note that we’re using NumPy expm1 methods here. NumPy expm1 function returns the exponential value of minus one for each element given inside a NumPy array as output. Therefore, the np.expm1 method accepts arr_name and out arguments and then returns the array as outputs.
After adding the new column, named clusters, the customer data dataset will look as below.

Finally, we’re going to use the below code to visualize the five clusters created. This is done using plotly with the express library.
Plotly is a Python library used for graphing, statistics, plotting, and analytics. This can be used along with Python, R, Julia, and other programming languages. Plotly is a free and open-source library.
Want to organize your experimentation process? Check how you can have interactive Plotly charts stored in the same place as the rest of your model metadata (metrics, parameters, weights, and more).
Plotly Express is a high-level interface over Plotly, that works on several types of datasets and generates highly-styled plots.
The plotly.express class has functions that can produce entire figures in one go. Generally, it’s referred to as px. It’s worth noting plotly express is the built-in module of the plotly library. This is the starting point of creating the most common plots as recommended. Note that each plotly express function creates graph objects internally and returns plotly.graph_objects.
A graph created by a single method call using plotly express can be also created using graph objects only. However, in that case, it takes around 5 to 100 times as much code.
As the 2D scatter plot , px.scatter plots individual data in a two-dimensional space, and the 3D method px.scatter_3d plots individual data in a three-dimensional space.

Visualization of clusters of data points is very important. Various edges of the graph provide a quick view of the complex input data set.
It’s not wise to serve all customers with the same product model, email, text message campaign, or ad. Customers have different needs. A one-size-for-all approach to business will generally result in less engagement, lower-click through rates, and ultimately fewer sales. Customer segmentation is the cure for this problem.
Finding an optimal number of unique customer groups will help you understand how your customers differ, and help you give them exactly what they want. Customer segmentation improves customer experience and boosts company revenue. That’s why segmentation is a must if you want to surpass your competitors and get more customers. Doing it with machine learning is definitely the right way to go.
If you made it this far, thanks for reading!
Was the article useful?
More about implementing customer segmentation using machine learning [beginners guide], check out our product resources and related articles below:, customizing llm output: post-processing techniques, deep learning optimization algorithms, track and visualize information from your pipelines: neptune.ai + zenml integration, product updates september ’23: scatter plots, airflow integration, and more, explore more content topics:, manage your model metadata in a single place.
Join 50,000+ ML Engineers & Data Scientists using Neptune to easily log, compare, register, and share ML metadata.
Customer Segmentation Using Machine Learning and Clustering
In another use case, we applied the RFM (Recency, Frequency, Monetary) approach to customer segmentation and showed how to interactively visualize and explore customer segments as well as use Guided Insights to identify customer segments of high value.
In this use case, we will take a more advanced approach that utilizes machine learning and a technique called clustering.
In this Use Case
What is clustering in machine learning, preparing the data, training the machine learning model, reviewing the machine learning model, scoring new data.
We will use an unsupervised machine learning clustering model that analyzes and groups a set of points in such a way that the distance between the points in a cluster is small (within the cluster distance) and the distance between points from other clusters is large (inter-cluster distance). There are multiple types of unsupervised algorithms (E.g.: hierarchical, probabilistic, overlapping) of which K-Means clustering is the most popular approach. Using Tellius, we are going to train a Bisecting K-Means model, which is a modification to the traditional K-Means algorithm where a number of clusters is defined apriori and the regular K-Means algorithm with k=2 runs to bisect the data until the desired number of segments is reached.
We are going to use the same data we used to perform the RFM segmentation described in the other use using RFM. Except this time, we can keep most of the continuous variables to be used as the input in the model. We also enrich the dataset by creating new features using the Tellius built-in SQL editor:
We created features such as total number of furniture orders, number of high priority orders, number of orders shipped via first class shipping, etc. The resulted data contained a record per customer ID with 22 features that served as the input into the clustering algorithm.
Tellius offers a robust machine learning layer which is built on Apache spark using Spark ML open-source library, where users can train, assess, and apply predictive models. The platform offers two approaches for training a model. One is called AutoML, where user selects a target variable and relies on Tellius to select the appropriate algorithm, perform feature transformation, fine-tune the parameters. The other is called Point-n-Click, which offers users more control over model selection and hyperparameter tuning approach. We are going to utilize Point & Click approach to build our model.
Step 1. Select the Clustering category of algorithms.
Step 2. Select the input features
Step 3. Select the Bisecting K-Means algorithm and provide the model parameters, such as number of iterations, seed value, number of clusters, and minimum cluster size.
Clicking on the Next button kicks off the model training job.
After the model is finished training, Tellius surfaces all the model information, such as the final list of input features, algorithm documentation , and model parameters.
Tellius also displays the top three features by variance in the evaluation section:
Using the model and the dataset it was trained on, the marketing team can easily build content in the visualization layer in Tellius to assess the quality of customer segments created by the model, identify segments of customers that have the highest growth potential, and share the content with the rest of peers or executives inside the organization. An example of such content may look like this:
The marketing analytics team can interact with each chart in the Vizpad, drill into each customer segment all the way to individual customer records if necessary, output charts into native Microsoft PowerPoint graphs, and create a slide deck for C-level leaders in a matter of minutes.
After the clustering model is trained and is ready to be implemented in production, we need to be able to apply the model on new data (i.e. scoring) and assign a segment label to each customer record unseen by the model. Tellius offers a few ways of applying the model to the new data. One way is through the Tellius interface using point and click functionality. More technical users may prefer to utilize Tellius’ prediction API to access a trained model using Python or CURL script. Let’s take a closer look how to access the Bisecting K-Means model described in the previous section via API and score a dataset containing new customer data.
The Tellius platform contains detailed documentation on the API with clear examples for each step.
Step 1. Run the Tellius module using a Python IDE of your choice. Note: The script below can be accessed from the Tellius platform.
Step 2. Authenticate into the environment by providing the clientID and clientSecret configured. Note: the ID and the Secret are typically configured by a user with admin capabilities.
Step 3. Obtain model ID and assign the ID to a variable.
Step 4. Bring the model object into IDE using the model ID obtained in the previous step.
Step 5. Specify input parameters into the Tellius predict_file function, such as the type of file, the header info, as well as the scoring file location. In this case, we are using Customer_Segmentation_Scoring.csv file stored in my Google Drive.
Step 6. Fetch the object with predicted data.
Step 7. Transform the scored data from JSON into a Pandas data frame and output into a csv file for sharing or further analysis.
Since Tellius uses Apache Spark distributed architecture, users can enjoy superb performance when it comes to training any type of machine learning model. Point-and-click predictive model training offers time savings when it comes to training a model, feature selection, and feature transformation. The Tellius predict API offers flexibility of using the platform as the scoring engine by producing the model prediction results in a form that can be easily integrated into your current infrastructure, third party tools, or web applications.
In this article we provided an overview of how a marketing team can utilize Tellius’s augmented analytics platform to perform customer segmentation analysis utilizing two different approaches, a traditional RFM approach as well as a Bisecting K-Means clustering predictive model. We showcased:
- Tellius’ ETL layer for easy transformation, cleaning, and enriching data through point and click, SQL, and Python script.
- Tellius Predict where we developed the clustering model in order to group the customer base into segments and identify the ones with the highest growth potential and the highest customer lifetime value.
- Tellius API to apply and score ML models on data and integrate results within 3 rd party web applications.
Tellius is useful for a variety of other eCommerce & Retail applications or download our Guide to AI-Driven Analytics for eCommerce . Take Tellius for a free 14 day spin (no credit card necessary) today!
See Tellius in Action
Customer segmentation using rfm.
Apply the RFM (Recency, Frequency, Monetary) approach to identify high value customer segments with Guided Insights
Live Insights: Automated Analytics for Cloud Data Warehouses
Live Insights are fast, automated insights run inside cloud data warehouses that greatly expedite the discovery of trend drivers, cohorts, and anomalies from terabytes of unaggregated data.
Bridging Insights Gap With AI-Driven Decision Intelligence eBook
Download this e-book to Learn how AI-Driven Decision Intelligence Bridges the Insights Gap in Your Organization
How to Perform Customer Segmentation in Python – Machine Learning Tutorial

Before I get into what this post is all about, I'd like to share the motivation that prompted me to write it.
I'm writing this article because I recall the first time I learned about customer segmentation or clustering. I didn't fully grasp what I was doing back then.
All I remembered was dumping all the features into KMeans and voilà – I'd developed a customer segmentation. I didn't understand the model's attributes for each segment.
So that for that reason, I'm sharing my knowledge of how I've come to grasp customer segmentation so hopefully you can gain from it.
In this tutorial, you will learn how to build an effective customer segmentation as well as how to perform effective Exploratory Data Analysis (EDA). These are the ingredients that will make your customer segmentation result delicious to eat 😋. Without further ado let's get started.
What is Customer Segmentation?
We've been talking about customer segmentation since the beginning of the article – but you might not know what it means.
Note that it is important to try and understand this theoretical part before we move into coding part of the tutorial. This foundation will help you build the segmentation model effectively.
Ok, back to defining what segmentation is:
Segmentation means grouping entities together based on similar properties. Entities could be customers, products, and so on.
For example customer segmentation , in particular, means grouping customers together based on similar features or properties.
Now there's one thing to note is when grouping customers based on properties: the properties you choose to group the customers must be relevant to the criteria based on which you want to group them.
For example, assume you want to categorize customers depending on what they buy. In this scenario, the customer's gender attribute may not be optimal or relevant for segmentation.
Knowing how to select appropriate attributes for customer segmentation is crucial.
Let's look at the different types of Customer Segmentation:
- Demographic Segmentation.
- Behavioral Segmentation.
- Geographic Segmentation.
- Psychographic Segmentation.
- Technographic Segmentation.
- Needs-based Segmentation.
- Value-based Segmentation.
The most typical types of consumer segmentation you will work on when performing segmentation revolve around Demographic and Behavioral segmentation.
Demographic Segmentation is the process of grouping customers based on their demography – that is, grouping customers based on their age, income, education, marital status, and so on.
Behavioral Segmentation means grouping customer based on their behavior. For example how frequently they purchase as a group, the total amount they spend on a goods, when they last bought a product, and so on.
To learn more about other types of Customer Segmentation, you can read this article .
Criteria for Customer Segmentation
When grouping customers, you should select relevant features that are tailored to what you want to segment them on. But in some circumstances, combining features from several types of customers segmentation to generate another type of segmentation makes sense.
For example, you can combine features from demographic and behavioral segmentation to create a new segmentation. That is precisely what you will learn in this article – we will build a customer segmentation using demographic features and behavioral features.
Now enough talking – let's get down to business.
Understanding the Business Problem.
The business problem is to segment customers based on their personalities (demographic) and the amount they spend on products (behavioral). This will help the company gain a better understanding of their customers' personalities and habits.
Tools We'll Use for this Project
Of course we're using Python to build our project – but these are the tools and libraries that we will also be using to help us out.
- Jupyter environment (Jupyter Lab or Jupyter notebook) – for experimenting with our project.
- Pandas – for loading data as a dataframe and wrangling the data.
- Numpy and Scipy – for performing some basic mathematical computations.
- Scikit-Learn – for building our Customer Segmentation Model.
- Seaborn, Matplotlib and Plotly Express – for data visualization.
If you don't have some or any of these libraries, you can check out their official documentations online to see how to install them.
Dataset We'll Use for this Project
The dataset we'll use in this project comes from Kaggle. You can go here to download it.
Here's a little information about the dataset:
To put it simply, the dataset contains the demographics of customers and their behavior as it relates to the company. The features of the dataset are:

Customer Personality Analysis Features
To get the most out of this tutorial, you can download the entire Jupyter notebook beforehand so you can follow along easily. You can go here to fork the repo.
Exploratory Data Analysis (EDA)
As you might know, EDA is the key to performing well as a data analyst or data scientist. It gives you first-hand information about the whole dataset, and it helps you understand all the relationships between the features in your dataset.
We will perform the three phases of EDA in this tutorial which are:
- Univariate Analysis.
- Bivariate Analysis.
Multivariate Analysis
Firstly we need to import all the necessary libraries we will use in this project. We also need to load the dataset into a dataframe so we can see all the features that are present in it.
To begin, there are many features in the dataset – but because we want to focus on customer demographics and behavior, we will only perform EDA on features related to those categories.
Keep in mind that the EDA conducted in this article is simply a subset of the one in the Jupyter Notebook. I did it this way to keep the article from becoming too buggy. To find the entire EDA in the notebook, fork the repo by clicking this link .
Age, income, marital status, education, total children, and amount spent on products are the attributes that belong to this category.
First, since the segmentation is based on the total amount customers have spent, we'll add the amount spent on the product:
After that's done we can now begin our EDA. An effective EDA always has three stages, as I mentioned above. Again, they are as follows:
- Univariate Analysis
- Multivariate Analysis.
Univariate analysis
Univariate analysis entails evaluating a single feature in order to get insights about it. So, the initial step in performing EDA is to undertake univariate analysis, which includes evaluating descriptive or summary statistics about the feature.
For example you might check a feature distribution, proportion of a feature, and so on.
In our case, we will check the distribution of customer's ages in the dataset. We can do that by typing the following:

We can see from the above summary that most of the customers belong in the age range of 40-60 .
Bivariate Analysis
After you've performed univariate analysis on all your feature of interest, the next step is to perform bivariate analysis. This involves comparing two attributes at the same time.
Bivariate analysis entails determining the correlation between two features, for example.
In our case, some of the bivariate analysis we'll perform in the project include observing the average total spent across different client age groups, determining a correlation between customer income and total amount spent, and so on, as shown below.
For example, in our case we want to check the relationship between a Customer's Income and TotalAmountSpent . We can do that by typing the following:

We can see from the above analysis that as the Income increases so does the TotalAmountSpent . So from the analysis we can postulate that Income is one of key factor that determines how much a customer might spend.
After you've completed univariate (analysis of single feature) and bivariate (analysis of two features) analysis, the last phase of EDA is to perform Multivariate Analysis.
Multivariate Analysis consists of understanding the relationship between two or more variables.
In our project, one of the multivariate analysis we'll do is to understand the relationship between Income , TotalAmountSpent , and Customer's Education .

We can see from the analysis that customers with an Undergraduate education level generally spend less than other customers with higher levels of education. This is because undergraduate customers typically earn less than other customers, which affects their spending habits.
How to Build the Segmentation Model
After we've finished our analysis, the next step is to create the model that will segment the customers. KMeans is the model we'll use. It is a popular segmentation model that is also quite effective.
The KMeans model is an unsupervised machine learning model that works by simply splitting N observations into K numbers of clusters. The observations are grouped into these clusters based on how close they are to the mean of that cluster, which is commonly referred to as centroids.
When you fit the features into the model and specify the number of clusters or segments you want, KMeans will output the cluster label to which each observation in the feature belongs.
Let's talk about the features you might want to fit into a KMeans model. There are no limits to the number of features you can use to build a Customer segmentation model – but in my opinion, fewer's better. This is because you will be able to grasp and interpret the outcomes of each segment more easily and clearly with fewer features.
In our scenario, we will first construct the KMeans model with two features and then build the final model with three features. But, before we get started, let's go over the KMeans assumptions, which are as follows:
- The features must be numerical.
- The features you're fitting into KMeans must be normally distributed. This is because KMeans (since it calculates average distance) is affected by outliers (values that deviate a lot from the others). As a result, any skewed feature must be changed in order to be normally distributed. Fortunately, we can use Numpy's logarithm transformation package np.log()
- The features must also be of the same scale. For this, we'll use the Scikit-learn StandardScaler() module.
We'll design our KMeans model now that we've grasped the main concept. So, for our first model, we'll use the Income and TotalAmountSpent features.
To begin, because the Income feature has missing values, we will fill it with the median number.
After that, we'll assign the features we want to work with, Income and TotalAmountSpent , to a variable called data .
Once that's done we will transform features and save the result into a variable called data_log .
Then we will scale the result using Scikit-learn StandardScaler() :
Once that's done we can then build the model. So the KMeans model requires two parameters. The first is random_state and the second one is n_clusters where:
- n_clusters represents the number of clusters or segments to be derived from KMeans .
- random_state : is required for reproducible results.
So, in a business setting, you might know the number of clusters you want to segment customers into ahead of time. But if not, you will need to experiment with different numbers of clusters to find the optimal one.
Since we're not in a business setting, we will experiment with different numbers of clusters.
The elbow method is the strategy we'll use to select the best cluster. It works simply by plotting the error from each cluster and looking for a spot that forms an elbow on the plot. As a result, the ideal cluster is the one that produces that elbow.
Here's the code that will help us achieve that:

Let's summarize what the above code does. We specified the number of clusters to experiment with, which is in the range(1, 11) . Then we fit the features on those clusters and added the error to the list we created before above.
Following that, we plot the error for each cluster. The diagram shows that the cluster that creates the elbow is three. So three clusters is the best value for our model. As a result, we will build the KMeans model utilizing three clusters.
Now we've built our model. The next thing will be to assign the cluster label for each observation. So we will assign the label to the original feature we didn't processed. That is, where we assigned Income and TotalAmountSpent to the variable data
How to Interpret the Cluster Result
Now that we've built the model, the next thing will be to interpret the result from each cluster.
There are numerous way you can summarize the results of your cluster depending on what you want to achieve. The most common summary is using central tendency which includes mean, median, and mode.
For our case we will make use of median. We're using median because the original features have outliers and the mean is very sensitive to outliers.
So we will aggregate the cluster labels and find the median for Income and TotalAmountSpent . We can make use of Pandas groupby method for that.

We can see that there is a trend within the clusters:
- Cluster 0 translates to customers who earn less and spend less.
- Cluster 1 represent customers that earn more and spend more.
- Cluster 2 represents customers that earn moderate and spend moderate.
We can also visualize the relationship by entering the following code:

Now in the same way we built the formal model, we will build the KMeans model using 3 features (the elbow method also depicts that 3 clusters is the optimal one).

We can see from the above summary that:
- Cluster 0 depicts young customers that earn a lot and also spend a lot.
- Cluster 1 translates to older customers that earn a lot and also spend a lot.
- Cluster 2 depicts young customers that earn less and also spend less.
We can also visualize our result by typing the following code:

In this tutorial, you learnt how to build a customer segmentation model. There are a lot of features we didn't touch on in this article. But I suggest that you experiment with it and create customer segmentation models using different features.
I hope you learn more from doing that. Thank you for reading the article. Happy Coding!
The link to the full code can be found below. And here's an article on K-Means Clustering if you want to learn more .
I'm an ardent data scientist who loves breaking and fixing up stuff related to data, and clearly taking care of the data to give me insights as to what it is portraying.
If you read this far, thank the author to show them you care. Say Thanks
Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started
6 customer segmentation case studies show big results

Customer Segmentation
Customer segmentation is the practice of putting customers into groups that are similar in specific ways. The goal is to tailor marketing to best meet individual needs. As a result, it improves customer satisfaction with customer satisfaction surveys , revenue, and profitability.
There are four types of customer segmentation: Demographic, Psychographic Geographic, and Behavioral. With the rise of machine learning , artificial in t elligence , personalization , and split testing , changes in customer segmentation can occur quicker with a significant impact.
Here are 6 customer segmentation case studies that show big results.
Airbnb uses machine learning to gain insights from user reviews. Then, they use this behavioral data and preference to pair hosts and guests. With A/B testing, they discover how website changes affect consumer behavior. They are able to adjust and personalize the content that users see when browsing the website.
BabyCenter (Johnson & Johnson)
For BabyCenter , Johnson & Johnson uses a Facebook Messenger App to suggest personalized advice. Through a series of questions and answers, they make targeted recommendations based on the input it receives from the user,
They look at the data to see what drove the highest levels of traffic to the website – a chatbot, email marketing, or the app. What they find is the messenger app has a read rate of 84% and a click-through rate (CTR) of 53%. The app’s overall engagement rate is 1,428% higher than email. Because it offers the greatest personalization.
DavidsTea customer segmentation
DavidsTea uses email marketing to recognize customer loyalty. When a customer reaches a specific anniversary with the company, they receive a “look back” email. It contains data on their first purchase, their most purchased teas, and how much they bought.
Therefore, by receiving this email, the customer feels unique and valued throughout their customer journey and is inclined to continue purchasing.
The Lego Group faces the challenge of marketing Lego Bricks on social media. The company identifies six distinct personas based on purchase and usage:
- Lead Users—people LEGO actively engages with on product design
- 1:1 Community—people whose names and addresses they know
- Connected Community—people who have bought LEGO and have also been to either a LEGO shop or a LEGO park
- Active Households—people who have bought LEGO in the last 12 months
- Covered Households—people who have bought LEGO once
- All Households—those who have never bought LEGO
The first three personas represent the most fertile ground. Because they share a deeper involvement with the brand. From there, Lego builds online communities on the social networks these segments use most often.
Lego takes advantage of their most valuable asset, their fans, who post pictures, videos, and provide new product ideas. This effort helps them to increase to the world’s fourth-largest toy manufacturer.
Netflix uses personalization that begins as soon as a user creates an account with Netflix and streams even just one TV show or movie. They use an algorithm that allows them to consistently and accurately A/B test and experiment with viewer preferences. Netflix’s algorithm dictates everything – the homepage layout, the recommended content, and even the visuals, or landing cards, for each piece of cinema. What’s more, Netflix personalizes the image you see based on the actors, actresses, or genres that it thinks you like. Netflix’s recommendation system saves them a massive $1Billion per year .
Olay customer segmentation
Olay creates Skin Advisor. The artificial intelligence beauty tool collects data from customers by asking them five to seven quick questions about their skin. The advisor then reveals the true age of the customer’s skin, and recommend products.
The data shows many customers are seeking Retinol based products. However, the subsequent lack of Retinol products in its range is contributing to the brand losing customers. Therefore, Olay releases Retinol 24 which has gone on to be one of the brand’s best selling products and has helped transform their sales.
Do these case studies help you see the impact of effective customer segmentation? And the tools you can apply, today ?

Rob Petersen
Related posts.

8 distinguished data science case studies

9 reasons why we love a good case study

15 inspiring case studies of pivoting
10 lead nurturing case studies show the ROI
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Technology and Operations Management
Mba student perspectives.
- Assignments
- Assignment: RC TOM Challenge 2018
MetLife: A Case Study in Customer Segmentation

In 2015, MetLife began a year-long brand discovery process that centered around using data and machine learning to develop a more refined view of their customer segments and enable a more nuanced go to market strategy. By better understanding their customers' needs, attitudes, and behaviors, MetLife hoped to gain a competitive advantage in targeting and better serving an increasingly demanding set of customers.
In 2015, MetLife began a year-long brand discovery process that resulted in what they would later call “the most significant change to their brand in over 30 years”. [i] At the core of this strategic refresh, was a fundamentally data driven approach, enabled by advances in machine learning, that revealed to MetLife that the insurance landscape around them was changing: Technological innovations such as the proliferation of internet connections and increased penetration of mobile devices changed the way business was done. [ii] Disruptive newcomers, such as Lemonade, were redefining the market place with their simplified approaches to underwriting. And despite that, customer and shareholder expectations were higher than ever. [iii] In the months that followed, MetLife interviewed and surveyed more than 50,000 customers and with the help of big data clustering techniques used the information to better understand and segment their customers and subsequently redesign their go to market approach. [iii] As an employee of Bain and Company, working with the MetLife team, I had the privilege to see the beginnings of the transformation firsthand.
Rethinking customer segmentation
Traditionally, insurance organizations tried to glean directional insights about their customers’ needs, attitudes, and behaviors through demographics. [iv] In the case of retail customers, age tended to be an important demographic that proxied attainment of certain life stages and thus the sophistication of the individual customer. In the case of corporate customers, the number of employees tended to be an important demographic that proxied sophistication of the organization. Armed with these types of rudimentary insights, insurers would use their best judgement in deciding the bundle of products to offer customers. However, using only demographics, insurers had at best only a rough outline of who their customers were let alone what they wanted or how to target them.
To better understand their customers, MetLife strove to “move from basic demographics and life stages to a view based on mindsets and attitudes.” [v] They collected data on their customers through in-depth surveys designed to extract a combination of demographic, firmographic, attitudinal, and need-type information. Using advanced segmentation tools, survey respondents were clustered into distinct groups based on their individual survey responses resulting in, for the first time in the company’s history, a refined picture of who their customers were. These groups (or segments) provided a new way to think about allocating resources against the pursuit of the “right” customers. Publicly available results of one such clustering (dates back to 2013 corresponding to some earlier work with segmentation), and the strategic targeting implications, are shown in the images below. [vi]
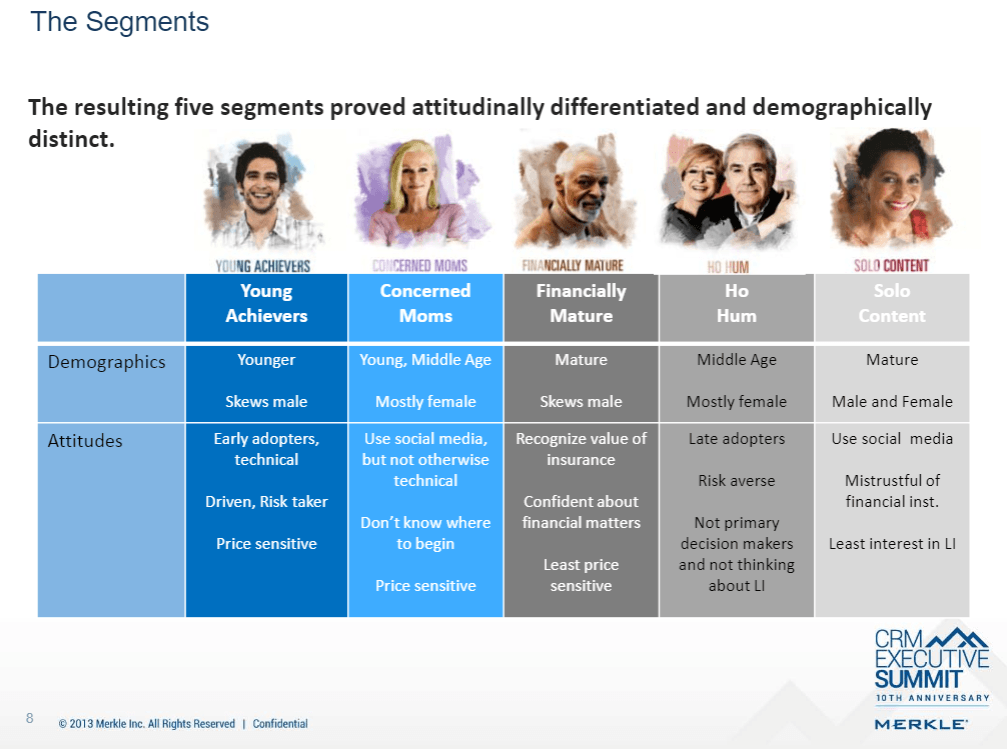
Pathways to Just Digital Future
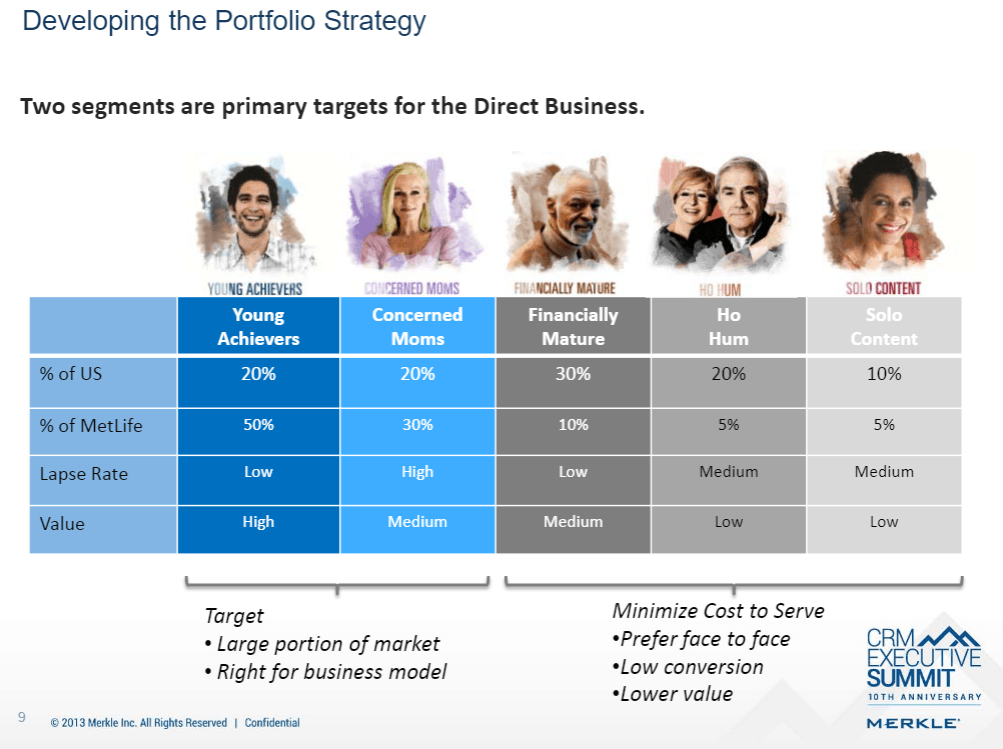
The path forward
As part of their brand refresh, MetLife committed to a data-driven approach “focused on identifying the right customers and creating truly differentiated customer value propositions.” [iii] They committed to an $800 million net annual savings target which they expect to be at full run rate by 2020. [iii] MetLife management stated that realizing the savings would require an estimated $1 billion in investments, a significant portion of which was in technology aimed at getting better data to fuel their increasingly robust data analytics capabilities. [iii]
Further, a core aspect of the customer segmentation work that MetLife engaged in was predicated on the idea that ideal customer segments needed to be “strategic and tactical in nature.” [vii] As part of the of the customer segmentation work, members of the sales force were made aware of the customer segments and given tools to help them effectively engage with target customers.
MetLife took its segmentation practices one step further and began educating its corporate customers, encouraging them to think about their employees through a combination of demographic and psychographic data. [v] MetLife’s business offerings now include “helping HR leaders select their benefits and adjust current programs to suit their diverse employees.” [v]
In many ways, MetLife’s data-driven strategic refresh was significant moment for the company and the broader insurance industry. It applied machine learning towards sales generation when most traditional insurance companies were focused on applying machine learning solely from a risk and improved underwriting perspective.
Going forward, MetLife should continue to embed machine learning deeper within their organization. A 2017 McKinsey article outlined four broad areas where machine learning could create value for an organization: projecting (forecasting), producing (operations), promoting (sales and marketing) and providing (enhanced user experiences). [viii]
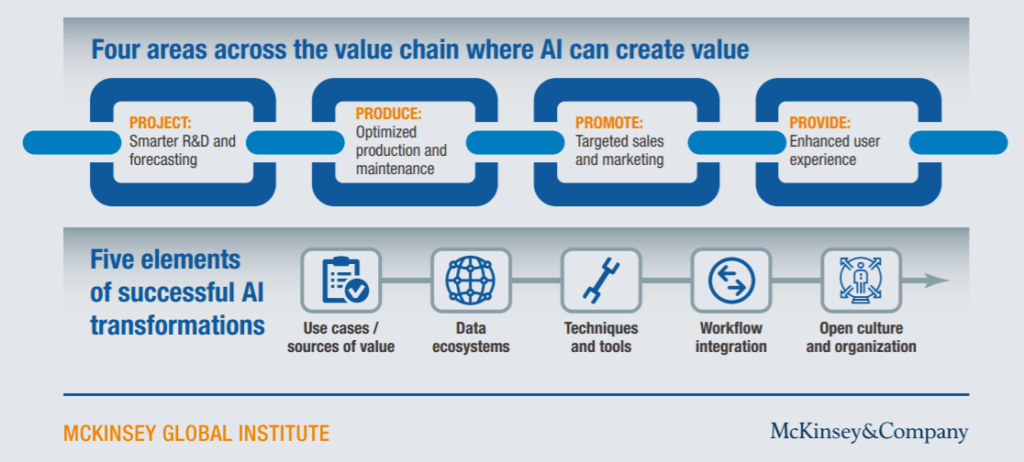
MetLife’s efforts in this strategic refresh focused on promoting. Going forward, management should be cognizant not to neglect other areas in which machine learning can add value to the organization.
Ultimately, are sequential improvements in the way MetLife uses machine learning enough to give them a competitive advantage over disruptive newcomers, or is some form of transformational improvement necessary for them to remain relevant?
(768 words)
[i] Stout, Craig. 2016. “The Power Of A Customer Centered Approach – The Metlife Rebrand”. Brand And Marketing Consultancy | Prophet . https://www.prophet.com/2016/10/power-customer-centered-approach-metlife-rebrand/ .
[ii] OECD (2017), Technology and innovation in the insurance sector, accessed November 2018
[iii] Metlife inc corporate investor day – final. (2016, Nov 10). Fair Disclosure Wire Retrieved from http://search.proquest.com.ezp-prod1.hul.harvard.edu/docview/1842918111?accountid=11311
[iv] Carr, Mark, and Amy Modini. 2012. “A New Approach To Segmentation For The Changing Insurance Industry”. Cmbinfo.Com . https://www.cmbinfo.com/cmb-cms/wp-content/uploads/2012/03/HealthDoc_FINAL.pdf .
[v] “Building Stronger Engagement Through Employee Segmentation | Workforce”. 2018. Metlife.Com . https://www.metlife.com/workforce/stronger-engagement-segmentation/ .
[vi] Mehra, Sanjay, and Leah van Zelm. 2013. “Segmentation. Customer Strategy Done Right – PDF”. Docplayer.Net . https://docplayer.net/13983641-Segmentation-customer-strategy-done-right.html .
[vii] Barlyn, Suzanne. 2017. “Metlife To Invest $1 Billion In Tech To Reach Cost-Savings Goals”. U.S. . https://www.reuters.com/article/us-metlife-investment-technology-idUSKBN17T2R6 .
[viii] Bughin, Jacques, Eric Hazan, James Manyika, and Jonathan Woetzel. 2017. “Artificial Intelligence The Next Digital Frontier”. Mckinsey Global Institute , 5.
Leave a comment Cancel reply
You must be logged in to post a comment.
Machine Learning for Customer Segmentation Through Bibliometric Approach
- Conference paper
- First Online: 26 July 2020
- Cite this conference paper

- Lopamudra Behera 7 ,
- Pragyan Nanda 7 ,
- Bhagyashree Mohanta 8 ,
- Rojalin Behera 9 &
- Srikanta Patnaik 8
Part of the book series: Algorithms for Intelligent Systems ((AIS))
2019 Accesses
3 Citations
In the age of information science and automation, ‘technological revolution’ and ‘machine era’ have gained significant attention from researchers of every quarter of life. Exuberance of artificial computation with machine learning techniques with practical applications and precision has become a perennial issue in every discipline. Optimization of marketing efficiency with assistance of computational applications has improved the accuracy and transparency level to achieve competitive advantages, to enhance organizational efficiency and to gain market advancement. In this bibliometric study, the authors have analyzed the literatures published during the period 2009–2019 having occurrence of relevant terms and major sources of contribution related to the area of ‘customer segmentation’ as an impact of ‘machine learning applications.’ Data scribe has been obtained from Scopus database, total of 1440 numbers of research articles were further analyzed using VOSviewer tool. The study revealed co-occurrence of keywords and bibliometric coupling of major sources of contribution. Findings suggest that the most frequent occurred key terms related to machine Learning have more influence and link strength than the terms related to customer segmentation by analyzing significant sources in terms of citations received and number of contribution made.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
S. Goyat, The basis of market segmentation: a critical review of literature. Eur. J. Bus. Manag. 3 (9), 45–54 (2011)
Google Scholar
J. Tikmani, S. Tiwari, S. Khedkar, An approach to consumer classification using K-Means. IJIRCCE 3 (11), 10542–10549 (2015)
C.P. Ezenkwu, S. Ozuomba, C. Kalu, Application of K-Means algorithm for efficient customer segmentation: a strategy for targeted customer services (2015)
V.R. Patel, R.G. Mehta, Impact of outlier removal and normalization approach in modified k-means clustering algorithm. Int. J. Comput. Sci. Issues (IJCSI) 8 (5), 331 (2011)
G. Linden, B. Smith, J. York, Amazon.com recommendations: item-to-item collaborative filtering. IEEE Internet Comput. 7 (1), 76–80 (2003)
H.K. Rao, Z. Zeng, A.P. Liu, Research on personalized referral service and big data mining for e-Commerce with machine learning, in 2018 4th International Conference on Computer and Technology Applications (ICCTA) (IEEE, 2018, May), pp. 35–38
Y. Fang, X. Xiao, X. Wang, H. Lan, Customized bundle recommendation by association rules of product categories for online supermarkets, in 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC) (IEEE, 2018, June), pp. 472–475
M. Pondel, J. Korczak, Collective clustering of marketing data-recommendation system Upsaily, in 2018 Federated Conference on Computer Science and Information Systems (FedCSIS) (IEEE, 2018, September), pp. 801–810
M. Tavakoli, M. Molavi, V. Masoumi, M. Mobini, S. Etemad, R. Rahmani, Customer segmentation and strategy development based on user behavior analysis, RFM model and data mining techniques: a case study, in 2018 IEEE 15th International Conference on e-Business Engineering (ICEBE) (IEEE, 2018, October), pp. 119–126
H.W. Yang, Z.G. Pan, X.Z. Wang, B. Xu, A personalized products selection assistance based on e-commerce machine learning, in Proceedings of 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826) , vol. 4 (IEEE, 2004, August), pp. 2629–2633
X. Chen, W. Sun, B. Wang, Z. Li, X. Wang, Y. Ye, Spectral clustering of customer transaction data with a two-level subspace weighting method. IEEE Trans. Cybern. 49 (9), 3230–3241 (2018)
A.S. Hossain, Customer segmentation using centroid based and density based clustering algorithms, in 2017 3rd International Conference on Electrical Information and Communication Technology (EICT) (IEEE, 2017, December), pp. 1–6
X. Chen, Y. Fang, M. Yang, F. Nie, Z. Zhao, J.Z. Huang, Purtreeclust: a clustering algorithm for customer segmentation from massive customer transaction data. IEEE Trans. Knowl. Data Eng. 30 (3), 559–572 (2017)
C. Catal, S. Guldan, Product review management software based on multiple classifiers. IET Softw. 11 (3), 89–92 (2017)
H. Zhao, X.H. Zhang, Q. Wang, Z.C. Zhang, C.Y. Wang, Customer segmentation on mobile online behavior, in 2014 International Conference on Management Science & Engineering 21th Annual Conference Proceedings (IEEE, 2014, August), pp. 103–109
Y. Xi, Chinese review spam classification using machine learning method, in 2012 International Conference on Control Engineering and Communication Technology (IEEE, 2012, December), pp. 669–672
D. Gallego, G. Huecas, An empirical case of a context-aware mobile recommender system in a banking environment, in 2012 Third FTRA International Conference on Mobile, Ubiquitous, and Intelligent Computing (IEEE, 2012, June), pp. 13–20
C.L. Borgman, Bibliometrics and scholarly communication: editor’s introduction. Commun. Res. 16 (5), 583–599 (1989)
I. Zupic, T. Čater, Bibliometric methods in management and organization. Organ. Res. Methods 18 (3), 429–472 (2015)
J.W. Prado, V. Castro Alcântara, F. Melo Carvalho, K.C. Vieira, L.K. Machado, D.F. Tonelli, Multivariate analysis of credit risk and bankruptcy research data: a bibliometric study involving different knowledge fields (1968–2014). Scientometrics 106 (3), 1007–1029 (2016)
Y. Wang, Q. Wang, R. Zhu, C. Yang, Z. Chen, Y. Bai, Trends of spinal tuberculosis research (1994–2015): a bibliometric study. Medicine 95 (38) (2016)
A.W.K. Yeung, T.K. Goto, W.K. Leung, The changing landscape of neuroscience research, 2006–2015: a bibliometric study. Front. Neurosci. 11 , 120 (2017)
N. Roig-Tierno, T.F. Gonzalez-Cruz, J. Llopis-Martinez, An overview of qualitative comparative analysis: a bibliometric analysis. J. Innovation Knowl. 2 (1), 15–23 (2017)
X. Chen, Z. Liu, L. Wei, J. Yan, T. Hao, R. Ding, A comparative quantitative study of utilizing artificial intelligence on electronic health records in the USA and China during 2008–2017. BMC Med. Inform. Decis. Mak. 18 (5), 117 (2018)
A.W.K. Yeung, Bibliometric study on functional magnetic resonance imaging literature (1995–2017) concerning chemosensory perception. Chemosens. Percept. 11 (1), 42–50 (2018)
C. Vallaster, S. Kraus, J.M.M. Lindahl, A. Nielsen, Ethics and entrepreneurship: a bibliometric study and literature review. J. Bus. Res. 99 , 226–237 (2019)
N. Van Eck, L. Waltman, Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 84 (2), 523–538 (2010)
J.F. Burnham, Scopus database: a review. Biomed. Digital Libr. 3 (1), 1 (2006)
Ş. Ozan, A case study on customer segmentation by using machine learning methods, in 2018 International Conference on Artificial Intelligence and Data Processing (IDAP) (IEEE, 2018, September), pp. 1–6
P.D. Hung, N.D. Ngoc, T.D. Hanh, K-means clustering using RA case study of market segmentation, in Proceedings of the 2019 5th International Conference on E-Business and Applications (2019, February), pp. 100–104
C. Miller, What’s in the box?! Towards explainable machine learning applied to non-residential building smart meter classification. Energy Build. 199 , 523–536 (2019)
M. Nilashi, A. Mardani, H. Liao, H. Ahmadi, A.A. Manaf, W. Almukadi, A hybrid method with TOPSIS and machine learning techniques for sustainable development of green hotels considering online reviews. Sustainability 11 (21), 6013 (2019)
G. David, A. Averbuch, SpectralCAT: categorical spectral clustering of numerical and nominal data. Pattern Recogn. 45 (1), 416–433 (2012)
MATH Google Scholar
M.S.B. Phridviraj, C.G. Rao, A novel approach for unsupervised learning of transaction data, in Proceedings of the 5th International Conference on Engineering and MIS (2019, June), pp. 1–5
R. Razavi, A. Gharipour, M. Fleury, I.J. Akpan, A practical feature-engineering framework for electricity theft detection in smart grids. Appl. Energy 238 , 481–494 (2019)
T. Ko, J.H. Lee, H. Cho, S. Cho, W. Lee, M. Lee, Machine learning-based anomaly detection via integration of manufacturing, inspection and after-sales service data. Ind. Manag. Data Syst. (2017)
D. Koolen, N. Sadat-Razavi, W. Ketter, Machine learning for identifying demand patterns of home energy management systems with dynamic electricity pricing. Appl. Sci. 7 (11), 1160 (2017)
I. Smeureanu, G. Ruxanda, L.M. Badea, Customer segmentation in private banking sector using machine learning techniques. J. Bus. Econ. Manag. 14 (5), 923–939 (2013)
J.M. Arevalillo, A machine learning approach to assess price sensitivity with application to automobile loan segmentation. Appl. Soft Comput. 76 , 390–399 (2019)
A. Ghahari, N.K. Newlands, V. Lyubchich, Y.R. Gel, Deep learning at the interface of agricultural insurance risk and spatio-temporal uncertainty in weather extremes. North Am. Actuarial J. 23 (4), 535–550 (2019)
MathSciNet MATH Google Scholar
K. Stormi, T. Laine, T. Elomaa, Feasibility of B2C customer relationship analytics in the B2B industrial context (2018)
K.S. Tan, P. Subramanian, Proposition of machine learning driven personalized marketing approach for E-commerce. J. Comput. Theor. Nanosci. 16 (8), 3532–3537 (2019)
M. Carnein, H. Trautmann, Customer segmentation based on transactional data using stream clustering, in Pacific-Asia Conference on Knowledge Discovery and Data Mining (Springer, Cham, 2019, April), pp. 280–292
B. Markic, D. Tomic, Marketing intelligent system for customer segmentation. Marketing Intelligent Systems Using Soft Computing (Springer, Berlin, Heidelberg, 2010), pp. 79–111
G. David, A. Averbuch, Hierarchical data organization, clustering and denoising via localized diffusion folders. Appl. Comput. Harmonic Anal. 33 (1), 1–23 (2012)
P.P. Shetty, C.M. Varsha, V.D. Vadone, S. Sarode, D. Pradeep Kumar, Customers churn prediction with RFM model and building a recommendation system using semi-supervised learning in retail sector. Int. J. Recent Technol. Eng. 8 (1), 3353–3358 (2019)
P. Albuquerque, S. Alfinito, C.V. Torres, Support vector clustering for customer segmentation on mobile TV service. Commun. Stat.-Simul. Comput. 44 (6), 1453–1464 (2015)
L.S. Chen, C.C. Hsu, M.C. Chen, Customer segmentation and classification from blogs by using data mining: an example of VOIP phone. Cybern. Syst. Int. J. 40 (7), 608–632 (2009)
R. Florez-Lopez, J.M. Ramon-Jeronimo, Marketing segmentation through machine learning models: an approach based on customer relationship management and customer profitability accounting. Soc. Sci. Comput. Rev. 27 (1), 96–117 (2009)
F. Yoseph, M. Heikkila, Segmenting retail customers with an enhanced RFM and a hybrid regression/clustering method, in 2018 International Conference on Machine Learning and Data Engineering (iCMLDE) (IEEE, 2018, December), pp. 108–116
J. Cuzzola, J. Jovanović, E. Bagheri, D. Gašević, Automated classification and localization of daily deal content from the Web. Appl. Soft Comput. 31 , 241–256 (2015)
A. Ahani, M. Nilashi, O. Ibrahim, L. Sanzogni, S. Weaven, Market segmentation and travel choice prediction in Spa hotels through TripAdvisor’s online reviews. Int. J. Hosp. Manag. 80 , 52–77 (2019)
P. Zou, B. Yu, X.Q. Wang, Cost-sensitive learning method with data drift in customer segmentation. Harbin Gongye Daxue Xuebao (J. Harbin Inst. Technol. 43 (1), 119–124 (2011)
Z. Peng, H. Yuanyuan, L. Yijun, Customer value segmentation based on cost-sensitive learning support vector machine. Int. J. Serv. Technol. Manage. 14 (1), 126–137 (2010)
H. Chen, S. Li, P. Wu, N. Yi, S. Li, X. Huang, Fine-grained sentiment analysis of chinese reviews using LSTM network. J. Eng. Sci. Technol. Rev. 11 (1) (2018)
L. Sun, Research on product attribute extraction and classification method for online review, in 2017 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII) (IEEE, 2017, December), pp. 117–121
H.V. Long, L.H. Son, M. Khari, K. Arora, S. Chopra, R. Kumar et al., A new approach for construction of geodemographic segmentation model and prediction analysis. Comput. Intell. Neurosci. 2019 (2019)
Download references
Author information
Authors and affiliations.
Interscience Institute of Management and Technology, Bhubaneswar, India
Lopamudra Behera & Pragyan Nanda
SOA University, Bhubaneswar, India
Bhagyashree Mohanta & Srikanta Patnaik
Sambalpur University, Sambalpur, India
Rojalin Behera
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Pragyan Nanda .
Editor information
Editors and affiliations.
School of Computer Science and Engineering, SOA University, Bhubaneswar, Odisha, India
Srikanta Patnaik
Simulation and Modelling, School of Science and Technology, Middlesex University, London, UK
Xin-She Yang
Department of Computer Science and Engineering, Oakland University, Rochester, MI, USA
Ishwar K. Sethi
Rights and permissions
Reprints and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper
Cite this paper.
Behera, L., Nanda, P., Mohanta, B., Behera, R., Patnaik, S. (2021). Machine Learning for Customer Segmentation Through Bibliometric Approach. In: Patnaik, S., Yang, XS., Sethi, I. (eds) Advances in Machine Learning and Computational Intelligence. Algorithms for Intelligent Systems. Springer, Singapore. https://doi.org/10.1007/978-981-15-5243-4_16
Download citation
DOI : https://doi.org/10.1007/978-981-15-5243-4_16
Published : 26 July 2020
Publisher Name : Springer, Singapore
Print ISBN : 978-981-15-5242-7
Online ISBN : 978-981-15-5243-4
eBook Packages : Engineering Engineering (R0)
Share this paper
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Customer Segmentation using Machine learning Techniques
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
For Vendors
99 machine learning case studies from 91 enterprises by 2024.
- 99 use cases in 17 industries
- 14 business processes in 14 business functions
- Implementations in 91 companies in 20 countries
- 10 benefits
- Growth over 6 years
- 9 vendors which created these case studies
Which industries leverage machine learning?
The most common use case of machine learning is Financial services which is mentioned in 19% of case studies.
The most common industries using machine learning are:
- Financial services
Which business functions leverage machine learning?
The most common business function of machine learning is Analytics which is mentioned in 14 case studies.
Most common business functions using machine learning are:
Which processes leverage machine learning?
The top process reported in machine learning case studies is Credit appraisal.
Most common business processes using machine learning are:
- Credit appraisal
- Financial planning & analysis
- Marketing analytics
- Data quality management
- Innovation management
- Product development
- Shipping / transportation management
- Financial risk management
- Customer journey mapping
- Incident management
- Performance management
- Sales forecasting
- Campaign management
- Data governance
What is the geographical distribution of machine learning case studies?
Click on the countries with links to explore how that country’s machine learning market is structured including top vendors, case studies etc.
Countries that use machine learning most commonly are listed below.
- United States of America
- United Kingdom
What are machine learning’s use cases?
The most common use case of machine learning is customer segmentation which is mentioned in 27% of case studies.
What are machine learning’s benefits?
The most common benefit of machine learning is time saving which is mentioned in 24% of case studies.
How are machine learning case studies growing?
Growth by vendor.
Leading vendors in terms of case study contributions to machine learning are:
- CognitiveScale
Growth over time
Years in which the;
- The first case study in our DB was published: 2016
- Most machine learning case studies have been published: 2019
- The highest increase in the number of case studies was reported vs the previous year: 2018
- The largest decrease in the number of case studies was reported vs the previous year: 2020
Comprehensive list of machine learning case studies
AIMultiple identified 99 case studies in machine learning covering 10 benefits and 99 use cases. You can learn more about these case studies in table below:
Our research on machine learning software
If you want to learn more about machine learning software, you can also check our related research articles that can assist you in your decision:
IMAGES
VIDEO
COMMENTS
psychological. Geographic customer segmentation is very simple, it's all about the user's location. This can be implemented in various ways. You can group by country, state, city, or zip code. Demographic segmentation is related to the structure, size, and movements of customers over space and time.
There are different products/solutions available in the market from packaged software to CRM products. Today, I will apply an unsupervised machine learning algorithm with Python. This dataset from November 2018 — April 2019 is actual sales data courtesy of an e-commerce company. It was provided to me for an interview case study.
Customer segmentation is important both in customer relationship management literature and softwares. The most common way to separate one customer from another is to promote a group of customers as premium and the remaining customers as standard. In this work, a company's manually segmented customer data is analyzed. The study aims to solve the company's data segmentation problem by using its ...
A case study on a wearable device is conducted to validate the proposed approach. ... studies conducting customer segmentation based on online reviews have limitations in customer clustering because of the free form of online reviews and the variety of customer preferences. ... Numerous data-driven IS and IM studies have used machine learning ...
A beginner's guide to customer segmentation. Attracting customers in a competitive landscape puts marketing front of mind for many companies. A lot rides on the ability to come up with the right ...
Keywords - Machine learning, Customer segmentation, K-means algorithm. 1.INTRODUCTION Today many of the businesses are going online and, in this case, online marketing is becoming ... "A Case Study on Customer Segmentation by using Machine Learning Methods", IEEE, Year: 2018. [2] Jayant Tikmani, Sudhanshu Tiwari, Sujata Khedkar "Telecom ...
Customer Segmentation Using Machine Learning and Clustering. In another use case, we applied the RFM (Recency, Frequency, Monetary) approach to customer segmentation and showed how to interactively visualize and explore customer segments as well as use Guided Insights to identify customer segments of high value. In this use case, we will take a ...
Three most common types of Customer Segmentation. Although there are more than three types of customer segmentation, we are going to look at the three most common strategies to do customer segmentation. 1. Demographic Segmentation. The parameters such as age, gender, education, income, financial status, etc. come under the demographics of a person.
A case study using Fitbit Charge 3 was conducted to validate the proposed approach. Fitbit Charge 3 was chosen because it is a well-known model for which sufficient reviews can be obtained in a short period. Customer segmentation of Fitbit Charge 3 was conducted based on online product reviews.
Download Citation | On Sep 1, 2018, Sukru Ozan published A Case Study on Customer Segmentation by using Machine Learning Methods | Find, read and cite all the research you need on ResearchGate
Applying machine learning techniques to solve real-world problems is important in the growing trend of quantitative decision-making. In line with this, the study has solved a real-world problem faced by the retail supermarket. ... Sivaguru, M. Dynamic customer segmentation: a case study using the modified dynamic fuzzy c-means clustering ...
this process, increasing the efficiency of marketing efforts through segmentation and geo-targeting. A national residential energy supplier approached Mosaic, a leading machine learning consulting firm, because they wanted to understand current customers and to identify high potential areas to target for new customer acquisition.
Behavioral Segmentation means grouping customer based on their behavior. For example how frequently they purchase as a group, the total amount they spend on a goods, when they last bought a product, and so on. To learn more about other types of Customer Segmentation, you can read this article. Criteria for Customer Segmentation
Customer segmentation is defined as dividing company's customers. on the basis of demographic (age, gender, marital status) and behavioral (types of. products ordered, annual income) aspects ...
There are four types of customer segmentation: Demographic, Psychographic Geographic, and Behavioral. With the rise of machine learning, artificial in t elligence, personalization, and split testing, changes in customer segmentation can occur quicker with a significant impact. Here are 6 customer segmentation case studies that show big results.
Code Output (Created By Author) Based on the visual charts, the consumer population is mainly segmented by age, marital status, profession, and purchasing power. We can now identify the defining traits of each cluster. Cluster 0: Single people from the arts and entertainment sectors with low purchasing power.
MetLife: A Case Study in Customer Segmentation. In 2015, MetLife began a year-long brand discovery process that centered around using data and machine learning to develop a more refined view of their customer segments and enable a more nuanced go to market strategy. By better understanding their customers' needs, attitudes, and behaviors ...
This is where machine learning comes into play, various algorithms are applied for unravelling the hidden patterns in the data for better decision making for the future. ... customers with similar behaviours into the same segment and with different patterns into different segments is called customer segmentation. In this paper, 3 different ...
In this work, a company's manually segmented customer data is analyzed. The study aims to solve the company's data segmentation problem by using its real data regarding its customers' payments. Since, machine learning methods are useful to solve problems about data management, the solution is searched within machine learning methods ...
enhance customer segmentation and targeting strategies [18]. Abidar et al proposed a new strategy for customer segmen-tation using machine learning techniques, highlighting the importance of targeted actions in marketing. Their approach demonstrates the effectiveness of machine learning in iden-
Although the variation of customer segmentation with machine learning tool publication is very low for the nominated period, the overall development of the topic interest across the time period is impressive. It can be assumed the popularity of the topic will increase in the future research. ... Ozan, A case study on customer segmentation by ...
The rapid expansion of e-commerce resulted in the influx of data in the mainstream. The data of customers can lead to better results and can help the stakeholders to take better results and improve their business. Machine learning also found its application in the e-commerce. Machine learning provides a vast collection of algorithms that produce efficient results in segmenting the customers ...
AIMultiple analyzed 99 machine learning case studies for data-driven insights. They highlight machine learning's. 99 use cases in 17 industries. 14 business processes in 14 business functions. Implementations in 91 companies in 20 countries. 10 benefits. Growth over 6 years. 9 vendors which created these case studies. Which industries leverage.