

NN/g UX Podcast
By nielsen norman group, available on.
Bonus Episode: Design’s Role as AI Expands (Feat. Don Norman and Sarah Gibbons, VP at NN/g)
Nn/g ux podcast mar 28, 2024.

AI is changing faster than we can sometimes process and will likely do so for a while. The recent tech layoffs have also not spared UX professionals, adding to the uncertainty about our future roles in this rapidly changing environment. While there is still much we don't know about AI, Don Norman, co-founder of NN/g, and Sarah Gibbons, VP at NN/g, share their insights on the future roles of designers, encouraging professionals to think big in the wake of AI's advancements.
Related NN/g Articles & Training Courses
Generative UI and Outcome-Oriented Design
AI as a UX Assistant
- The 4 Degrees of Anthropomorphism of Generative AI
AI Chat Is Not (Always) the Answer
- AI-Powered Tools for UX Research: Issues and Limitations
- Prompt Structure in Conversations with Generative AI
Sycophancy in Generative-AI Chatbots
New Course: Practical AI for UX Professionals
Other Related Content
- Don Norman’s Website
0:00-1:12 - Intro
1:13-18:18 - What will design’s role be as AI expands?
18:18-23:15 - What is going to stay the same as AI expands?
23:16-end - Rapid Fire Questions
37. XR: Improving Learning Outcomes
Extended reality (XR) experiences hold the potential to transform the way we learn, work, and collaborate. Specifically, it can make educational experiences more interactive, engaging and ultimately drive higher learning outcomes. In this episode, we feature Jan Plass, who discusses the affordances of XR technology, provides examples of XR learning experiences and shares his expectations for its impact on the education landscape. Jan Plass is a Professor at New York University, Paulette Goddard Chair, and Director of CREATE. Learn more about Jan Plass : CREATE Lab Looking Inside Cells On the Morning You Wake Verizon AR/VR Learning Apps (i.e. Visceral Science, Mapper's Delight, UNSUNG, Looking Inside Cells etc.) NN/g ARTICLES & TRAINING COURSES Augmented/Virtual Reality vs. Computer Screens 10 Usability Heuristics Applied to Virtual Reality Virtual Reality and User Experience Emerging Patterns in Interface Design (full-day/2 half-day UXC course)
The Design of Everyday Things CHAPTERS: 0:00-3:13 - Intro 3:13-5:35 - What is XR? 5:35-8:54 - XR as a Learning Opportunity 8:54-12:19 - Examples of XR for learning 12:19-15:30 - Evidence of Learning with VR Technology 15:30-18.51 - Can VR features Induce Emotions and Result in Better Learning Outcomes? 18:51-23.45 - Comparing UX in 2D and 3D spaces? 23:45-27:41 - Accessibility and Inclusivity in XR 27:41 - XR Development: The Role of Affordances
36. AI & UX: Innovations, Challenges, and Impact
The surge of AI is currently changing the way we work and live. To avoid feeling left behind, it is important to engage with and understand these tools. This is true for UX designers just as much as almost everybody else. In this episode, we feature Henry Modisett from Perplexity AI and Kate Moran to get two insightful perspectives on the current state of AI and its connection to UX. Learn more about Henry Modisett Learn more about Kate Moran Perplexity.AI NN/g ARTICLES & TRAINING COURSES AI for UX: Getting Started (free article) AI & Machine Learning Will Change UX Research & Design (free video) AI Improves Employee Productivity by 66% (free article) AI-Powered Tools for UX Research: Issues and Limitations (free article) AI: First New UI Paradigm in 60 Years (free article) Sycophancy in Generative-AI Chatbots (free article) Information Foraging with Generative AI: A Study of 3 Chatbots (free article) The ELIZA Effect: Why We Love AI (free article) Practical AI for UX Professionals (full-day/2 half-day UXC course) CHAPTERS 0:00 Intro 1:43 Perplexity AI: History & Value Proposition 10:30 Perplexity AI: Next Steps & Future Developments 15:04 Making AI User Friendly: Generative Interfaces 24:33 Understanding AI as a Consumer Product 28:28 Mental Models for AI 30:41 An Outlook for AI 35:51 NN/g’s Role in the AI Movement 37:34 Anthropomorphism of AI 40:07 Dealing with the Fear of AI
35. Wireframing & Prototyping (feat. Leon Barnard, Content Manager, Balsamiq)
Wireframing is an incredibly useful design technique to flesh out conceptual ideas and communicate them to others. However, with the advent of powerful prototyping tools, some designers may think of these as irrelevant or outdated practices. Leon Barnard, Content Manager at Balsamiq and co-author of the book Wireframing for Everyone , discusses why he thinks wireframing is not only still relevant, but essential for maximizing creativity and innovative thinking.
- Connect with Leon Barnard
- Balsamiq Wireframing Academy Wireframing for Everyone (book) by Michael Angeles, Leon Barnard, & Billy Carlson
How to Draw a Wireframe (Even if You Can’t Draw) (free article)
UX Basics: Study Guide (collection of free articles)
UX Basic Training (UX certification course)
UX Deliverables (UX certification course)
Visual Design Fundamentals (UX certification course)
34. Data-Driven Decision-Making and Intranet Design (feat. Christian Knoebel and Charlie Kreitzberg, Princeton University)
We often talk about measuring progress, but it can sometimes be harder to do in practice than in theory, especially when you’re combining mixed research methods. However, some teams have managed to not only make sense of the data, but use it to make award-winning designs. In this episode we feature two members of Princeton University’s award-winning intranet team: Charlie Kreitzberg, Senior UX Advisor, and Christian Knoebel, Director Digital Strategy, and how they combined two frameworks: the 5D Rubric and pairLab, to bridge the gap between UX and product design.
Learn about the 5-D Rubric
Learn about pairLab
Related NN/g resources:
- 10 Best Intranets of 2022 (the year Princeton University won) (free article)
- Intranet & Enterprise Design Study Guide (free article)
- Past Intranet Design Annual: 2022 (the year Princeton University won) (534-page report)
- Intranet Design Annual: 2023 (most recent awards) (483-page report)
33. Tracking UX Progress with Metrics (feat. Dr. John Pagonis, UXMC, Qualitative and Quantitative Researcher)
Measuring a user experience can be intimidating at first, but it's an essential part of determining whether your work is moving in the right direction (and by how much). UX Master Certified Dr. John Pagonis shares his experiences from working with other organizations on measuring UX improvements and interpreting quantitative data.
Learn more about John Pagonis:
- Connect on LinkedIn
- Watch a past keynote talk: Usefulness measurement: A practical guide for all UXers (37 min video)
NN/g Resources about Usability and UX Metrics:
- Usefulness, Utility, and Usability by Jakob Nielsen, PhD (2-min video)
- The UX Unicorn Myth (decathlon analogy, explained, 2-min video)
- Usability 101 by Jakob Nielsen, PhD (free article)
- Measuring UX and ROI (full-day course for UX certification)
- UX Metrics and ROI by Kate Moran (297-page report)
NN/g Articles about Microsoft's Desirability Toolkit and Adjectives List
- Using the Microsoft Desirability Toolkit to Test Visual Appeal (free article)
- Microsoft Desirability Toolkit Product Reaction Words (free article)
Jeff Sauro, PhD on UX-Lite, UMUX-Lite, SUS, SEQ
(an aside: his website, MeasuringU.com , is an excellent resource)
- 10 Things To Know About The Single Ease Question (SEQ)
- Measuring Usability with the System Usability Scale (SUS)
- 5 Ways to Interpret a SUS Score
- Measuring Usability: From the SUS to the UMUX-Lite
- Evolution of the UX-Lite
Quick Update: Episodes Now On YouTube!
(But don't worry, we will still continue publishing future episodes on Spotify, Apple Podcasts, and many other platforms!)
Check out our YouTube Channel here
Go to our YouTube Podcast playlist
32. Conducting Research with Employees (feat. Angie Li, UXMC, Senior Manager of Product Design at Asurion)
Research with employees might sound easy in theory: you work in the same company as the people you need to observe or interview, and you might not even need to pay them for input. However, there's a bit more to it than meets the eye. In this episode, we feature UX Master Certified Angie Li, and she discusses what has helped her organize and run successful research with internal team members.
Learn more about Angie Li
NN/g Articles & Training Courses
- Employees as Usability-Test Participants (free article)
- Structuring Intranet Discovery & Design Research (free article)
- Ethnographic User Research (full-day/2 half-day UXC course)
- User Interviews (full-day/2 half-day UXC course)
- Usability Testing (full-day/2 half-day UXC course)
31. Service Design 101 (feat. Thomas Wilson, UXMC, Senior Principal Service Designer & Strategist)
Members of our UX Master Certified community are applying UX principles to their work in a range of different ways. In this episode, we interview Thomas Wilson, Senior Principal Service Designer at United Healthcare and discuss what service design is and what makes it challenging and rewarding.
Learn more about Thomas Wilson: LinkedIn
NN/g Service Design Resources:
- Service Blueprinting (full-day or half-day formats)
- Service Design Study Guide (free article with links to many more)
- Learn more about UX Master Certification
Some of the (many) people and organizations Thomas mentioned:
- Service Design Network
- Adam St. John Lawrence
- Marc Stickdorn
- Anthony Ulwick
30. Stakeholder Relationships (feat. Sarah Gibbons, Vice President at NN/g)
Building stakeholder relationships is no easy task but it is crucial for getting buy-in, aligning expectations and ultimately building trust. But, what even is a "stakeholder" and how do you know if you have good relationships built? In this episode, we feature a conversation between Samhita Tankala and Sarah Gibbons who discuss the challenges that come with stakeholder management and how to build successful relationships.
Learn more about Sarah Gibbons
Related NN/g articles, videos, and courses:
- Successful Stakeholder Relationships (UX Certification course)
- How to Sell UX: Translating UX to Business Value (Video)
- How to Collaborate with Stakeholders in UX Research (Article)
- UX Stories Communicate Designs (Article)
- Making a Case for UX in 3 Steps (Video)
- Stakeholder Analysis for UX Projects (Article)
- UX Stakeholders: Study Guide
Other sources Sarah mentioned:
- The Five Dysfunctions of a Team by Patrick Lencioni
29. UX Mentorship (feat. Tim Neusesser, UX Specialist at NN/g, and Travis Grawey, Director of Product Design at OfficeSpace)
The importance of mentorship for personal and professional development is an often-discussed topic, yet it can be challenging to find a mentor or become a mentor yourself. In this episode, we feature a conversation between a mentee, NN/g’s Tim Neusesser, and his mentor, Travis Grawey. In this episode they discuss how mentorship has impacted both of their careers.
Learn more about Tim Neusesser
Learn more about Travis Grawey (who mentors along with many others at ADPList )
Related NN/g articles & videos:
- Why You Need UX Mentoring (video)
- The C's of Great UX Mentorship (video)
- Finding UX Mentors (video)
- UX Careers Report (free report)
28. Games User Research (feat. Steve Bromley, author and games user researcher)
Have you ever wondered what it's like to usability test a video game? Or what goes on behind the scenes of gaming studios as they prepare for big release dates? In this episode, games user researcher Steve Bromley shares how he got into the field, and what makes games different from traditional user experiences.
Steve's Website: gamesuserresearch.com ; Steve's Book: How To Be A Games User Researcher
Other websites Steve Mentioned
- A Theory Of Fun For Game Design (Raph Koster)
- A Playful Production Process
- Game Developer Conference Videos
NN/g's Free Articles and Videos on Games & Gamification:
- 10 Usability Heuristics Applied to Video Games (article)
- Games User Research (article)
- Video Game Design and UX (video)
- Gamification in the User Experience (video)
- Psychology & UX Study Guide (free study guide)
NN/g UX Certification Courses (full-day or half-day formats)
- Persuasive & Emotional Design
- The Human Mind and Usability
27. Customer Journey Management (feat. Kim Salazar, Sr. UX Specialist at NN/g and Jochem van der Veer, CEO/Co-Founder of TheyDo)
If you ask experienced UX practitioners how to stay user-centric, you’ll inevitably hear something about the importance of customer journeys. However, as teams become more mature in their UX practices, the number of journeys being tracked and analyzed has been growing, sometimes faster than teams can manage, leading to scattered and uncoordinated redesign efforts. In this episode, we hear some tips about customer journey management from Kim Salazar of NN/g and Jochem van der Veer of TheyDo, a customer journey management platform.
Learn more about the episode guests:
Kim Salazar, Senior UX Specialist at NN/g
Jochem van der Veer, Co-Founder & CEO, TheyDo / TheyDo.com
Related NN/g courses & reports:
Customer-Journey Management (full-day / 2 half-days course)
- Operationalizing CX: Organizational Strategies for Delivering Superior Omnichannel Experiences (142-page report)
The Practice of Customer-Journey Mangement (free article)
What is Journey Management? (3 min video)

26. The Evolution of UX (feat. Dr. Jakob Nielsen, Co-Founder & Principal, NN/g)
The UX industry has recently seen what some call "unprecedented" shifts with layoffs and generative artificial intelligence rapidly changing how UX work is done. However, there have been similarly turbulent periods in tech, decades before. Dr. Jakob Nielsen reflects on the changes that have taken place over the near 25 years Nielsen Norman Group has been around, and discusses whether or not generative AI is just a phase or truly the next chapter of UX work.
Learn more about Dr. Jakob Nielsen
Past keynote speeches by Dr. Jakob Nielsen
Topics Covered:
- 1:45 - Dr. Jakob Nielsen's "origin story"
- 3:46 - What UX was like during the "dot-com boom"
- 6:30 - How the UX profession has changed since the "dot-com boom"
- 8:21 - Generative AI - a phase or the next chapter of UX work?
- 13:26 - How AI will shift the labor of UX away from pixel-pushing and toward orchestration/editorializing
- 16:58 - The future of UX: what keeps Dr. Jakob Nielsen inspired
- 19:34 - Balancing the pressure to build new features vs. fixing existing infrastructures (UX debt)
- 23:00 - Foundational UX ideologies: who is responsible for a good experience; matching how people actually behave
- 25:17 - Advice for people new to UX
- 27:40 - Advice for experienced UX professionals in preparing for a future with AI
25. Discount Usability: Expert Reviews and Heuristic Evaluations (feat. Evan Sunwall, UX Specialist, NNg)
With the recent surge in tech layoffs, a downsizing of UX labor means UX research is harder to do, meaning: research needs to be prioritized in really intentional ways. Discount inspection methods like expert reviews and heuristic evaluations can help identify high-priority design issues that need further research and design effort. In this episode, Evan Sunwall offers some insight into how to facilitate and communicate the results of these inspection methods.
Connect with Evan Sunwall on LinkedIn - https://www.linkedin.com/in/esunwall/
Evan's Recommended Further Reading on NN/g:
- Jakob Nielsen's 10 Usability Heuristics (article) The classic heuristics for effective interaction design used by many UX professionals to evaluate digital experiences.
- Heuristic Evaluation of User Interface (video)
- How to Conduct a Heuristic Evaluation (article)
- How to Conduct an Expert Review (article)
Other Books:
- Don't Make Me Think (book) - a very short and easy-to-read primer on usability and its role in creating successful products.
24. Artificial Intelligence: What Is It? What Is It Not? (feat. Susan Farrell, Principal UX Researcher at mmhmm.app)
The term artificial intelligence, AI, is having a bit of a boom, with the explosion in popularity of tools like ChatGPT, Lensa, DALL•E 2, and many others. The praises of AI have been equally met with skepticism and criticism, with cautionary tales about AI information quality, plagiarism, and other risks. Susan Farrell, the Principal UX Researcher at mmhmm, shares a bit about her experiences in researching chatbots and AI driven tools, and defines what AI is, what it isn’t, and what teams should consider when implementing AI systems. Susan Farrell's social media: LinkedIn ; Mastodon What Susan is working on: mmhmm.app NN/g courses referenced in this episode:
- Design Tradeoffs & UX Decision Making (full-day and 2-day course)
- Emerging Patterns in Interface Design (full-day and 2-day course)
Recommended Reading to deep dive into artificial intelligence & machine learning:
- Age of Invisible Machines - Robb Wilson
- The Promise and Terror of Artificial Intelligence - Os Keyes
- Becoming a chatbot: my life as a real estate AI’s human backup
- The Invisible Workforce that Makes AI Possible
- For Humans Learning Machine Learning
- What are large language models (LLMs), why have they become controversial?
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
Interested in working for us? Check out our job posting and apply by Jan. 30, 2023.
23. Building Better Products with a Better Mindset (feat. Ryan Hudson-Peralta, Principal Experience Designer at Rocket Homes)
Building exceptional experiences usable by all is no easy feat. Focusing on what can be influenced and accepting what cannot be changed are two critical steps to crafting better products... and careers. We spoke with Ryan Hudson-Peralta, a principal experience designer at Rocket Homes, who often introduces himself as a "father, husband, international speaker, and designer... who just happens to be born without hands." Ryan shares a bit about his journey into the UX field, and how his mindset of curiosity and positivity allows him to create meaningful experiences with his designs and with his career.
Learn more about Ryan Hudson-Peralta: lookmomnohands.com
If you would like to learn about UX design, we have thousands of articles and videos at our website www.nngroup.com .
Full-Day Design Courses (also available in 2 half-day formats)
- UX Basic Training
- Web Page UX Design
- Application Design
- Mobile User Experience
- Designing Complex Apps for Specialized Domains
22. UX, Big Data, and Artificial Intelligence (feat. Kenya Oduor, Ph.D., founder of Lean Geeks)
How has the UX field changed over the years? What does the future of UX work look like if scope is wildly expanding? Will we be automated out of a job? What should teams do to ensure they’re not misinterpreting data? Kenya Oduor shares her thoughts on these questions and more, offering suggestions for UX professionals wishing to set themselves up for success in a future of coexistence with artificial intelligence systems and automation. (Surprisingly, these tips are quite helpful for planning and analyzing quantitative user research as well.)
Learn more about Kenya Oduor, Ph.D. and Lean Geeks: Bio , LinkedIn , Twitter , YouTube , LeanGeeks.net
Related NN/g Articles & Videos:
The Relationship Between Artificial Intelligence and User Experience (4 min video)
AI & Machine Learning Will Change UX Research & Design (11 min video)
10 Usability Heuristics in Interface Design (article)
Visibility of System Status (Usability Heuristic #1) (article)
Hierarchy of Trust: The 5 Experiential Levels of Commitment (article)
Related NN/g Course: Emerging Patterns in Interface Design (UXC course - full day or 2 half-days)
21. Making Your Visual Designs Work Harder For You (feat. Kelley Gordon, Digital Design Lead at NN/g)
Visual design takes a lot more work than just making things look pretty, and is a fundamental part of many user's experiences. Our digital design lead, Kelley Gordon, shares some practical tips for both designers and "non-designers" alike to strengthen visual designs and improve working relationships.
Read more about Kelley Gordon here
Follow us on Instagram @nngux
Full-day courses and 1-Hour Talks referenced in this episode:
- Design Critiques: What, How, and When (1-Hour Talk)
- Web Page UX Design (UXC Course)
- Visual Design Fundamentals (UXC Course)
20. What Makes a "Good" UX Professional?
19. Designing a UX Career (feat. Sarah Doody, Founder of the Career Strategy Lab)
Have you thought about your career lately? Chances are, you have - given the buzz around the record high voluntary resignation rates during this “Great Resignation.” In this episode, Sarah Doody, UX Researcher, Experience Designer, and Founder of the Career Strategy Lab, shares her thoughts on how UX professionals can design their ideal careers, whether they’re in the market for a new role or not. Read more about Sarah Doody:
- Website (sarahdoody.com)
- Twitter (@sarahdoody)
- LinkedIn (/in/sarahdoody)
- Instagram (@sarahdoodyux)
NN/g Resources on UX Careers:
- Jakob Nielsen: How to Start A New Career in UX (2-min video)
- UX Careers (free 90-page report)
- Growing in your UX Career: A Study Guide (article)
- Portfolios for UX Researchers (article)
Interested in working with us? Apply to this posting by April 4th
18. Presenting UX Work in a Compelling Way (feat. David Glazier, Senior Staff UX Designer at Illumina)
UX professionals often find themselves saddled with the burden of convincing others to value UX work. David Glazier, Sr. Staff UX Lead of Digital Experience at Illumina tells his story about how effective communication helped him get buy-in with stakeholders and key decision-makers.
Read more about David Glazier on LinkedIn
Courses & Talks mentioned in this episode:
- Storytelling to Present UX Work (live, full-day UX Certification course)
- VR & User Research (1-hour recorded talk by David Glazier)
- Presenting to Stakeholders (1-hour recorded talk, related
More articles, videos, and upcoming training can be found at www.nngroup.com
17. User Research Trends: What's Changed and What Hasn't (feat. Erin May and JH Forster, hosts of Awkward Silences)
There is no question that user research has changed over the last two years, but how significant are those changes? The answer is complex, but User Interviews' Erin May (VP Growth & Marketing) and JH Forster (VP Product) demystify these trends and share their observations and hopes for the years to come.
Check out the Awkward Silences podcast by User Interviews
Erin May: Twitter (@erinhmay) , LinkedIn
John-Henry (JH) Forster: Twitter (@jhforster) , LinkedIn
User Interviews: Twitter , LinkedIn , Facebook
Recruiting and Screening Candidate for User Research Studies (article)
Qualitative Research Study Guide (article)
Quantitative Research Study Guide (article)
Related 1-Hour Talks:
Remote Research Trends (1-Hour Talk)
How Inclusive Design Expands Business Value (1-Hour Talk)
Upcoming Training Events:
Virtual UX Conference January 8-21 (2 half-day format)
Qualitative Research Series April 4-8 (5-day training event)
User Interviews Links:
The State of User Research 2021 Report
User Research Field Guides
Recruit 3 research participants for free on UserInterviews.com
16. What's up with DesignOps? (feat. Kate Kaplan, Insights Architect at NN/g)
As design teams mature in size and scope, the importance of intentionally designing and systematizing processes, approaches, and tools becomes increasingly difficult to ignore. Kate Kaplan shares insights from her research studying design teams and offers tips for those seeking to initiate and lead DesignOps efforts as a way to make design more impactful at their organizations.
Learn more about Kate Kaplan on LinkedIn and nngroup.com
NN/g Resources Mentioned:
- DesignOps 101 (free article)
- DesignOps Maturity (free article)
- 6 Levels of UX Maturity (free article)
- UX Maturity Stage 3: Emergent (free article)
- DesignOps: DesignOps: Scaling UX Design and User Research (UXC course)
Other Links Mentioned: Rosenfeld Media’s DesignOps Summit: https://rosenfeldmedia.com/designopssummit2021/
A note on companies to follow, from Kate: "There are so many teams at different organizations publicly sharing and publishing their DesignOps journeys and experiments, and I think that willingness to share is amazing and points to the greater community being built around DesignOps. Some that come top of mind to follow are Salesforce, Cisco, IBM, AirBnB, Pinterest, Athena Health, Atlassian. Most of these companies have internal design blogs or medium channels where they share their approaches."
15. The Metaverse, Blockchain, and UX (feat. Geoff Robertson, Founder & UX Specialist at Chockablock)
A two-part podcast episode discussing the implications of decentralized computing and mixed reality on the future of UX work.
Geoff's Website: geoffrobertson.me
1-Hour Talks discussed in the episode:
- Blockchain 101
- Blockchain & UX
Related courses:
- Emerging Patterns in Interface Design (UX Certification eligible course)
Upcoming online events:
- Intranet and Employee Experience Symposium: Nov 9-10
- Qualitative Research Series (5-Days): Nov 15-19
14. Keeping Product Visions User-Centered (feat. Anna Kaley, UX Specialist at NN/g)
Product visions can align a team and inspire a better future state. When visions stem from real user needs, the ideas that follow have the greatest potential for success. NN/g UX Specialist Anna Kaley discusses keeping users at the center of product development, and shares insights from next weeks' UX Vision and Strategy Series, presented alongside Chief Designer, Sarah Gibbons.
Read more about Anna Kaley (NN/g bio)
Referenced courses and training series:
- UX Vision and Strategy Series (Oct 18-22, 2021) with Anna Kaley and Sarah Gibbons
- Product and UX: Building Partnerships for Better Outcomes
- Being a UX Leader: Essential Skills for Any UX Practitioner
- Lean UX and Agile
Related (free) videos & articles:
- UX Vision (3-min video by Anna Kaley) Create an aspirational view of the experience users will have with your product, service, or organization in the future. This isn't fluff, but will guide a unified design strategy. Here are 5 steps to creating a UX vision.
- UX Roadmaps: Definition and Components (article by Sarah Gibbons)
13. Special Edition: What's the "UX hill" you would die on?
To kick off Season 2, we're releasing a special edition episode, inspired by a tweet posted by @AllisonGrayce in Feb 2021 , where she asks followers, "what's a #ux hill you regularly die on?" Host Therese Fessenden asks both NN/g team members and members of the UXC and UXMC community what issues, topics, and principles they fiercely stand by, and shares their answers.
Guests and submissions featured in the episode (in order):
Chris Callaghan (UXMC) - UX and Optimisation Director (Manchester, UK) Twitter: @CallaghanDesign
Kara Pernice - Sr. VP at Nielsen Norman Group Bio: nngroup.com/people/kara-pernice
Mary Formanek (UXMC) - Senior User Experience + Product Lead Engineer (Arizona, US) Mary's Article: "Label Your Icons: No, we can’t read your mind. Please label your icons." Tiktok: @UXwithMary
Ben Shih - UX Consultant and Product Designer (Stockholm, Sweden) Portfolio: benshih.design
Rachel Krause - UX Specialist at Nielsen Norman Group Bio: nngroup.com/people/rachel-krause/
Anna Kaley - UX Specialist at Nielsen Norman Group Bio: nngroup.com/people/anna-kaley
You can find also information about the upcoming UX Vision and Strategy Series with Anna Kaley and Sarah Gibbons here.
12. ResearchOps (feat. Kara Pernice, Sr. VP at NN/g)
One might think user research gets easier when there are more people available to do it; but managing research initiatives at scale can be a difficult task in itself. In this episode, Kara Pernice, Senior VP at NN/g shares her experience and insights about managing UX research operations.
Kara Pernice's Articles and Videos (NN/g bio)
NN/g courses and articles referenced in this episode:
- ResearchOps (UX certification course)
- ResearchOps (article)
- Research Repositories for Tracking UX Research and Growing Your ResearchOps (article)
- Design Systems 101 (article)
- DesignOps (UX certification course)
Research repository tools mentioned:
- Consider.ly
Other ResearchOps pioneers and communities:
- Kate Towsey's Work (articles on Medium)
- Leveling up your Ops and Research — a strategic look at scaling research and Ops (by Brigette Metzler)
- ResearchOps Community (and Slack channel )
...and if you were curious what research papers launched Kara into her UX career, here are two of them:
- Nielsen, J. (1990). Big paybacks from 'discount' usability engineering. IEEE Software 7, 3 (May), 107-108.
- Nielsen, J. (1992). Finding usability problems through heuristic evaluation. Proc. ACM CHI'92 (Monterey, CA, 3-7 May), 373-380.
11. Solo UX: How to Be a One-Person UX Team (feat. Garrett Goldfield, UX Specialist at NN/g)
Advocating for UX work is hard. It's even harder when you're the only UX professional on your team. That said, there is still hope for one-person UX teams, and Garrett Goldfield shares his recommendations on how to make the most out of limited time and resources, and how to lead the charge in shifting corporate culture toward a more human-centered future.
Read more about Garrett Goldfield (NN/g bio)
Resources & courses cited in this episode:
- Episode 1. What is UX, anyway? (feat. Dr. Jakob Nielsen, the usability guru) (previous NN/g UX Podcast episode)
- The One-Person UX Team (UX Certification course)
- The Human Mind and Usability (UX Certification course)
10. On Delight, Emotion, and UX - Flipping the Script with UX Specialists Therese Fessenden & Rachel Krause
To celebrate our first podcast milestone, we flipped the script. NN/g UX Specialist Rachel Krause guest-hosts this episode, and interviews host Therese Fessenden about the concept of "delight" in user experience: what it is, why the pursuit of delight can often be a short-sighted and misunderstood endeavor, and how a more holistic approach to interpreting and anticipating user needs can more reliably lead to an experience that delights beyond a single interaction.
Read more about the hosts:
- Therese Fessenden's Articles & Videos (NN/g bio)
- Rachel Krause's Articles & Videos (NN/g bio)
Free resources cited in this episode:
- A Theory of User Delight: Why Usability Is the Foundation for Delightful Experiences (free article)
- Design for Emotion (by Daniel Ruston, UX Lead at Google Design)
- Principles of Emotional Design (Intuit case study by Garron Engstrom)
- How Delightful! 4 Principles for Designing Experience-Centric Products (Autodesk MLP case study by Maria Giudice)
- Research: Perspective-Taking Doesn’t Help You Understand What Others Want (HBR article by Tal Eyal, Mary Steffel, Nicholas Epley)
- Harvard Psychiatrist Identifies 7 Skills to Help You Get Along With Anybody (Inc. article by Carmine Gallo about Helen Riess' work)
Other resources cited in this episode:
- Emerging Patterns in Interface Design (UX Certification course)
- Persuasive and Emotional Design (UX Certification course)
- DesignOps: Scaling UX Design and User Research (UX Certification course)
- Designing for Emotion by Aarron Walter (book)
9. You Are Not the User: How the the False Consensus Effect Can Lead Good Design Astray (feat. Alita Joyce, UX Specialist at NN/g)
Does having more experience in the UX industry enable you to make better design decisions by intuition? Does user research ever become a waste of time if some research already exists in academic papers? The answer, it seems, is not that simple. In this episode, UX Specialists Alita Joyce and Therese Fessenden discuss why, after all these years doing independent user research, you should still test your interfaces and research with your own customers. Read more: Alita Joyce's Articles & Videos (NN/g bio)
- Viral video (by @tired_actor) "The Square Hole" (TikTok video)
- The False-Consensus Effect (free article)
- The “False Consensus Effect”: An Egocentric Bias in Social Perception and Attribution Processes (PDF of full study by Ross, Greene, and House)
- 10 Usability Heuristics for User Interface Design (free article)
- How to Conduct a Heuristic Evaluation (free article)
- 10 Usability Heuristics Applied to Video Games (free article)
- Don Norman - Changing Role of the Designer Part 2: Community Based Design (4 min video)
- Adam Grant - The "I’m Not Biased" Bias (Tweet about NBC Sunday Spotlight feature)
- The Human Mind and Usability (UX Certification course)
- Persuasive and Emotional Design (UX Certification course)
- Democratizing Innovation by Eric Von Hippel (book)
- Thinking, Fast and Slow by Daniel Kahneman (book)
8. Thinking Beyond Interactions: Omnichannel Experiences and CX (feat. Kim Salazar, Sr. UX Specialist at NN/g)
What does it take to create a great customer experience? As it turns out: a lot more than just a series of great interactions. Kim Salazar, Sr. UX Specialist, shares her expertise on what omnichannel experiences are, why they matter for CX, and how having a mature CX means fundamentally changing how we view and handle UX work.
Resources cited in this episode
- Ep. 1 - What is UX, anyway? (feat. Dr. Jakob Nielsen, the usability guru) (our inaugural podcast episode)
- CX Transformation (full-day course)
- Journey Mapping to Understand Customer Needs (full-day course)
- Kim's Articles & Videos (NN/g bio)
Other related articles & videos
- What is Omnichannel UX? (2-min video)
- User Experience vs. Customer Experience: What’s The Difference? (free article + 4 min video)
- Good Customer Experience Demands Organizational Fluidity (free article)
7. Lessen Digital Misery with Complex Apps (feat. Page Laubheimer, Sr. UX Specialist at NN/g)
"Keep it simple," is one of many great UX mantras... but how exactly does someone "keep it simple" when working with complex applications? In this episode, Page Laubheimer, Senior UX Specialist with NN/g, shares his expertise in information architecture (IA) and complex app design, recommends a few ideas to "lessen digital misery" on business-to-business (B2B) and enterprise applications, and offers advice for when you have to redesign a legacy application that is part of a user's everyday life.
Resources cited in this episode:
- Designing Complex Apps for Specialized Domains (full-day course)
- Data Visualizations for Dashboards (4-min video)
- Dashboards: Making Charts and Graphs Easier to Understand (NN/g article)
- Why I Now Use “Four-Threshold” Flags On Dashboards (Nick Desbarats' article)
- Tesler's Law (Wikipedia article)
- Page's NN/g Articles and Videos (bio page)
6. Ethics in UX (feat. Maria Rosala, UX Specialist at NN/g)
Aren't all "user-centered" designs ethical by default if we're giving people what they want? Not exactly. Maria Rosala, UX Specialist at NN/g, shares her thoughts about how we can be better researchers and designers by asking critical questions about our research and design decisions, evaluating important tradeoffs, and ensuring we include the right people in our research and design process.
Resources Cited in this Episode:
- User Interviews (UX Certification course)
- Design Tradeoffs and UX Decision Frameworks (UX Certification course)
- Ethics in User Research (1-hr online seminar)
- You Are Not The User: The False-Consensus Effect (free article)
- TED Talk: How I'm fighting bias in algorithms | Joy Buolamwini (9 min YouTube video)
Also related: How Inclusive Design Expands Business Value (1-hr online seminar)
5. ROI: The Business Value of UX (feat. Kate Moran, Sr. UX Specialist at NN/g)
How do you evaluate the impact of UX work? As the world faces another bout of pandemic lockdowns, UX teams are finding themselves in a tough position of justifying their work to business decision-makers. Kate Moran, Senior UX Specialist at NN/g, shares insights from her recently published report on UX Metrics and ROI (return on investment) and offers advice on how to prove your worth. In this episode, we cover: what ROI is and why it matters, avoiding common pitfalls when calculating ROI, and how to stay growth-oriented without harming long-term business strategy.
- UX Metrics and ROI report (297-page report)
- Measuring UX and ROI (full-day course)
- Myths of Calculating ROI (free article)
- Don't Shame Your Users Into Converting (4-min video)
- Stop Shaming Your Users for Micro Conversions (free article)
- Kate's NN/g Articles and Videos (bio page)
4. Creativity During a Crisis (feat. Aurora Harley, Sr. UX Specialist at NN/g)
"Diamonds are made under pressure," but what does that mean for creativity and productivity? Aurora Harley, Senior UX Specialist, shares some advice on staying creative and productive during times of stress, thoughts on reframing constraints as opportunities, and tips for nurturing an environment that fosters innovative thought regardless of distance. Resources Cited in this Episode
- Effective Ideation Techniques for UX Design (full-day course)
- Changing Role of the Designer (Don Norman) (5 min video)
- Ideation Techniques for a One-Person UX Team (2 min video)
- Remote Ideation - Synchronous or Asynchronous Techniques (4 min video)
- Troubleshooting Group Ideation: 10 Fixes for More and Better UX Ideas (free article)

3. UX Careers: Growing in (and out of) Your Current Role (feat. Rachel Krause, UX Specialist at NN/g)
What does a typical UX career path look like? Are there even typical career paths in UX? How can you become a UX leader? What should new and seasoned UX professionals keep in mind as they move through their careers? Rachel Krause, a UX Specialist at Nielsen Norman Group, shares her insights from her research on the UX profession, and perspectives from her own journey into the field of user experience.
- What a UX Career Looks Like Today (free article)
- User Experience Careers (90-page report)
- Management vs. Specialization as UX Career Growth (3 min video)
- The State of UX Job Descriptions (3 min video)
- Being a UX Leader: Essential Skills for Any UX Practitioner (full-day course)

2. Empathy, Adaptability, and Design (feat. Sarah Gibbons, Chief Designer at NN/g)
Sarah Gibbons & Therese Fessenden discuss empathy and adaptability as critical design skills (perhaps now more than ever) and share thoughts on how design plays a bigger role than meets the eye.
- NN/g Instagram: @nngux
- Service Blueprinting (full-day course)
- Design Thinking is Like Cooking (2 min video)
- UX Roadmaps (full-day course)
- UX Roadmaps: Definition and Components (free article)
- Sarah's NN/g Articles and Videos (bio page)
Also related: Brené on Comparative Suffering, the 50/50 Myth, and Settling the Ball ( Unlocking Us with Brené Brown podcast episode)

1. What is UX, anyway? (feat. Dr. Jakob Nielsen, the usability guru)
Nielsen Norman Group is celebrating its 22nd anniversary by launching our very own NN/g UX Podcast. Join host Therese Fessenden as she interviews NN/g co-founder Dr. Jakob Nielsen on the most important questions about our industry: What really is "user experience," anyway? And what is the state of UX now, compared to when NN/g started 22 years ago?
- The Definition of User Experience (article)
- WAP Mobile Phones Field Study Findings (article)
- Describing UX to Family and Friends (3-min video)
- Usability 101: Introduction to Usability (article)
- User Experience vs. Customer Experience (article)
- Jakob Nielsen's Profile, Articles, and Videos
- Artificial Intelligence
- Product Management
- UX Research
Unlocking the Power of Research Repositories for Product Managers

Zita Gombár

Bence Mózer

A centralized system is required to develop a good understanding of your users across teams and across your firm. Here's when research repositories come in handy. They bring together various points of user input and feedback. So, whether you're a UX researcher, designer, or a product manager, this post is for you.

Have you ever wished for faster answers to your research questions? If your team has already conducted a few studies, you likely have a solid understanding of your users and may already have the answers you need.
However, various other departments within your organization are likely also receiving feedback from customers. How do you connect your data with insights from other teams? And how can you ensure that people have access to research data when they need it? Discover the solution in a research repository.
Based on our extensive experience working with diverse clients, including large enterprises and NGOs, UX Studio has developed a comprehensive ebook on research repositories for UX research . This resource covers all the essential aspects, starting with the definition and key principles of research repositories, along with insights on building and maintaining them for long-term success. We would also like to provide you with a sneak peek from the book about why a research repository is crucial for your organization.

What is a research repository?
Any system that keeps research data and notes that can be quickly retrieved, accessed, and used by the entire team is referred to as a research repository (or research library). Let’s look at the key components of this definition.
A research repository is a system that stores all of your research data, notes, and documentation (such as research plans, interview guides, scripts, personas, competitor analysis, etc.) connected to the study. It allows for easy search and access by the entire team.
Let’s take a closer look at the elements of this definition:
Storage system.
A system of this type is any tool you use to store and organize your research data. This can take various forms and structures. It could be an all-in-one application, a file-sharing system, a database, or a wiki.
Research data.
Any information that helps you understand your users can be considered research data. It makes no difference what format is used. Text, images, videos, or recordings can all be used to collect research data. Notes, transcripts, or snippets of customer feedback can also be used.
Ease of use.
Anyone on your team can access, search, explore, and combine research data if it is simple to use. Developers, designers, customer success representatives, and product managers are all examples of this. Any of them can gain access to the research repository in order to learn more about users. The researcher is no longer the gatekeeper when it comes to understanding users.
Since it’s a massive collection of research, the research repository is also the team’s go-to place for learning about users and their pain points. Instead of searching three different locations for reports, all research information is centralized in one single place.

How can a research repository help your company?
As a company starts doing more and more user research, this means more studies, more reports, and a whole lot of information that you cannot really access unless you know who worked on what.
If you work in a company without a research repository, you probably rely a lot on file sharing software like SharePoint or Google Drive. This means you spend a lot of time navigating through folders and files to find what you’re looking for (if you can find it at all), as well as sharing file links to distribute your work and findings.
How often do you wish for a simpler way of organizing all this data?
Let’s explore how research repositories can elevate your research work!
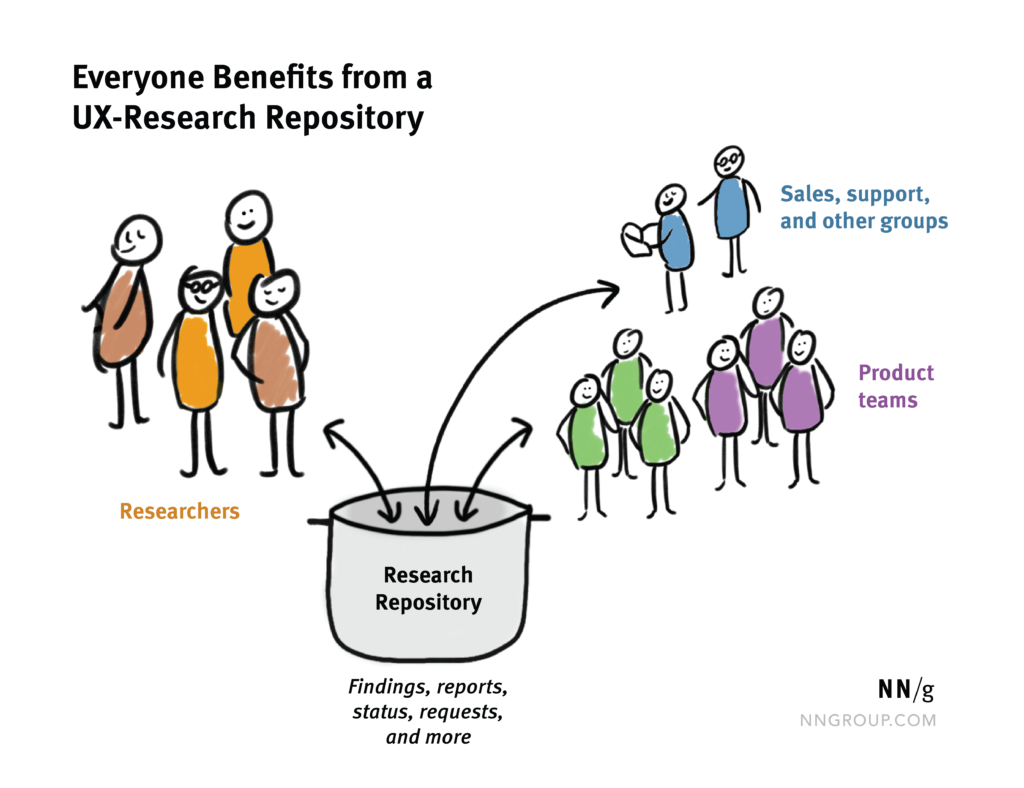
The go-to place to learn about users
Since it’s a massive collection of research, the research repository is the team’s go-to place for learning about users and their pain points. Instead of searching three different locations for reports, all research information is centralized in one single place.
Speeding up research.
Whenever you have a new research question, you can start by reviewing existing data. Since it’s all organized according to tags, you don’t have to go through multiple reports to find it. This way, if there’s relevant information, you get the answers faster.
Get more value from original research.
If research observations are no longer tied to report findings, they can be reused to answer other questions. Of course, if they’re relevant. This builds on the previous point of speeding up research. Also, it allows you to get more value from original studies.
No more repeated research.
As reports get buried and lost in file-sharing systems, so does the information they contain. We briefly mentioned this before. But you’re probably familiar with the situation. Someone performed a study on a feature at some point. Let’s say that another person joins the team and wants to learn about that feature. Without any knowledge of existing research, researchers start a new study for the same question. If, on the other hand, all the research data is centralized, you can see what questions have already been asked.
Enable evidence-based decisions.
Probably this is one of the biggest wins for a research repository. It allows teams to see the big issues that need to be solved. Also, teams get to see on their own, how these issues come up. On top of that, they can now use that data to prioritize projects and resources. This makes it easier than using gut feelings or personal opinions.
Anyone can learn about users – to increase UX research maturity.
By default, the researcher is the person who knows everything about users and their problems. A research repository opens up this knowledge to anyone who is interested. With a bit of time and patience, everybody can get to know users.
You can prioritize your roadmap.
Putting all the data together will give you an overall view of the user experience. This, in turn, will help you see what areas you need to prioritize on your roadmap.
Yes, it takes time and resources to set up and maintain a research repository. But the benefits are clearly worth that investment. Even more so since information, along with access to it are essential for high-performing teams. Besides research, it is about building trust and transparency across your team and giving them what they need to make the right decisions.
When to use a research repository?
Whether you are thinking about setting up a research system for an ongoing project or you would like to organize your existing insights, there are a few things to consider.
Long term, ongoing research.
This is common for in-house research. It may also occur if the user research is outsourced to a third party. Data will begin to pile up at some point in long-term, ongoing research. It will become more difficult to locate information as it accumulates. We’ve also discussed the issues that may arise if you only rely on reports. In this case, you will undoubtedly require a solution to organize and structure all of the research findings.
This is the first major scenario in which you should strongly consider establishing a research repository. Even if you’re a one-person team, and you’re the only one doing the research, it’s a good idea to start promoting research repositories. Explain your situation to your manager or team .
Multiple researchers are working on the same project.
It doesn’t really matter whether this is a short-term or long-term project. When multiple researchers are working on the same project, they require a solution that will assist them in compiling all of the data. You can collect all of the observations using a research repository. Even if the two researchers discuss their findings, using a research repository increases the likelihood that important data will not be overlooked.
Good products are developed from great insights. However, teams require access to these insights in order to integrate them into the product. This is where research repositories can be helpful.
Setting up a research repository may take some time, but it is a great investment for scaling research operations in the long run and increasing UX research maturity. Despite the initial effort required, a research repository can take your entire research to the next level. For this, you can use the tools you have at hand such as Notion or Google Sheet, or you can try out dedicated tools such as Dovetail or Condens .
At UX Studio, we have assisted numerous companies in setting up their research processes, enabling them to conduct in-house research and enhance their product development with a user-centered approach.
For comprehensive guidance on research repositories, we invite you to download our complete book here .
Do you want to build your in-house research team or create your own repository?
As a top UI/UX design agency , UX studio has successfully handled over 250 collaborations with clients worldwide.
Should you want to improve the design and performance of your digital product, message us to book a consultation with us. Our experts would be happy to assist with the UX strategy, product and user research, or UX/UI design.
Let's talk
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 29 August 2023
re3data – Indexing the Global Research Data Repository Landscape Since 2012
- Heinz Pampel ORCID: orcid.org/0000-0003-3334-2771 1 , 2 ,
- Nina Leonie Weisweiler ORCID: orcid.org/0000-0001-6967-9443 2 ,
- Dorothea Strecker ORCID: orcid.org/0000-0002-9754-3807 1 ,
- Michael Witt 3 ,
- Paul Vierkant 4 ,
- Kirsten Elger 5 ,
- Roland Bertelmann 2 ,
- Matthew Buys 4 ,
- Lea Maria Ferguson 2 ,
- Maxi Kindling 6 ,
- Rachael Kotarski ORCID: orcid.org/0000-0001-6843-7960 7 &
- Vivien Petras 1
Scientific Data volume 10 , Article number: 571 ( 2023 ) Cite this article
2992 Accesses
2 Citations
25 Altmetric
Metrics details
For more than ten years, re3data, a global registry of research data repositories (RDRs), has been helping scientists, funding agencies, libraries, and data centers with finding, identifying, and referencing RDRs. As the world’s largest directory of RDRs, re3data currently describes over 3,000 RDRs on the basis of a comprehensive metadata schema. The service allows searching for RDRs of any type and from all disciplines, and users can filter results based on a wide range of characteristics. The re3data RDR descriptions are available as Open Data accessible through an API and are utilized by numerous Open Science services. re3data is engaged in various initiatives and projects concerning data management and is mentioned in the policies of many scientific institutions, funding organizations, and publishers. This article reflects on the ten-year experience of running re3data and discusses ten key issues related to the management of an Open Science service that caters to RDRs worldwide.
Similar content being viewed by others

SciSciNet: A large-scale open data lake for the science of science research
Zihang Lin, Yian Yin, … Dashun Wang

PANGAEA - Data Publisher for Earth & Environmental Science
Janine Felden, Lars Möller, … Frank Oliver Glöckner

A dataset describing data discovery and reuse practices in research
Kathleen Gregory
Introduction
In the 2010s, making research data publicly accessible gained importance: Terms such as e-science 1 and cyberscience 2 were shaping discourses about scientific work in the digital age. Various discussions within the scientific community 3 , 4 , 5 , 6 , 7 , 8 resulted in an increased awareness of the value of permanent access to research data. Policy recommendations of the Organization for Economic Co-operation and Development (OECD) 9 or the European Commission 10 reflected this shift.
The need for professional data management was increasingly emphasized with the publication of the now widely recognized FAIR Data Principles 11 . Researchers, academic institutions, and funders started to address this issue in policies 12 , initiatives and networks 13 , 14 , 15 , and infrastructures 16 , 17 , 18 , 19 . For example, the National Science Foundation (NSF) in the United States published a Data Sharing Policy in 2011, in which the funding agency required beneficiaries to provide information about data handling in a Data Management Plan 20 . In Germany, the German Research Foundation (DFG) published a similar statement regarding access to research data in the 2010s 21 , 22 .
The handling of research data was also discussed in library and computing center communities: In 2009, the German Initiative for Networked Information (DINI), a network of information infrastructure providers, published a position paper on the need for research data management (RDM) at higher education institutions 23 . Through the discussions within DINI, the need for a registry of RDRs became evident. At the time, the Directory of Open Access Repositories (OpenDOAR) 24 had already established itself as a directory of subject and institutional Open Access repositories. However, there was no comparable directory for RDRs, and it remained unclear how many repositories dedicated to research data existed.
In 2011, a consortium of research institutions in Germany submitted a proposal to the German Research Foundation (DFG), asking for funding to develop ‘re3data – Registry of Research Data Repositories’ 25 . Members of the consortium were the Karlsruhe Institute of Technology (KIT), the Humboldt-Universität zu Berlin, and the Helmholtz Open Science Office at the GFZ German Research Centre for Geosciences. The DFG approved the proposal in the same year. The project aimed to develop a service that would help researchers identify suitable RDRs to store their research data. re3data went online in 2012, and already listed 400 RDRs one year later 26 .
While working on the registry, the project team in Germany became aware of a similar initiative in the USA. With support from the Institute of Museum and Library Services, Purdue and Pennsylvania State University libraries developed Databib, a ‘curated, global, online catalog of research data repositories’ 27 . Databib went online in the same year 28 . At the time, RDRs were indexed and curated by library staff at re3data partner institutions, whereas Databib had established an international editorial board to curate RDR descriptions 27 . Databib and re3data signed a Memorandum of Understanding in 2012, and, following excellent cooperation, the two services merged in 2014 29 . The merger brought together successful ideas from each service: The metadata schemas were combined, resulting in version 2.2 of the re3data metadata schema 30 , and the sets of RDR descriptions were merged. The international editorial board of Databib was expanded to include re3data editors. Development of the IT infrastructure of re3data continued, combining the expertise both services had built. For operating the service, a management duo was installed, comprising a member each from institutions representing re3data and Databib.
The two services have always been closely corresponding with DataCite, an international not-for-profit organization that aims to ensure that research outputs and resources are openly available and connected so that their reuse can advance knowledge across and between disciplines, now and in the future 31 . In this process, the main objective was to cover the interests of the global community of operators more comprehensively. In 2015, the DataCite Executive Board and the General Assembly decided to enter into an agreement with re3data, making re3data a DataCite partner service 29 . In 2017, re3data won the Oberly Award for Bibliography in the Agricultural or Natural Sciences from the American Libraries Association 32 .
Today, re3data is the largest directory of RDRs worldwide, indexing over 3,000 RDRs as of March 2023. re3data is widely used by academic institutions, funding organizations, publishers, journals, and various other stakeholders, such as the European Open Science Cloud (EOSC) and the National Research Data Infrastructure in Germany (NFDI). re3data metadata is also used to monitor and study the landscape of RDRs, and it is reused by numerous tools and services. Third-party-funded projects support the continuous development of the service. Currently, the DFG is funding the development of the service within the project re3data COREF 33 , 34 . In addition, the project partners DataCite and KIT bring the re3data perspective into EOSC projects such as FAIRsFAIR (completed) 35 and FAIR-IMPACT 29 .
This article outlines the decade-long experience of managing a widely used registry that supports a diverse and global community of stakeholders. The article is clustered around ten key issues that have emerged over time. For each of the ten issues, we first present a brief definition from the perspective of re3data. We then describe our approach to addressing the issue, and finally, we offer a reflection on our work.
The section outlines ten key issues that have emerged in the last ten years of operating re3data.
For re3data, Open Science means providing unrestricted access to the re3data metadata and schema, transparency of the indexing process, as well as open communication with the community of global RDRs.
At all times, re3data has been committed to Open Science by striving to be transparent and by sharing metadata. The openness of re3data pertains not only to the handling of its metadata and the associated infrastructure, but also to collaborative engagements with the community of research data stewards and other stakeholders in the field of research data management.
An example of this is the development of the re3data metadata schema: The initial version of the schema integrated a request for comments that allowed stakeholders to offer suggestions and improvements 26 . This participatory approach, accompanied by a public relations campaign, has yielded positive outcomes. Numerous experts engaged in the request for comments and contributed their perspective and expertise. Based on the positive feedback, we subsequently integrated a participatory phase in further updates of the metadata schema 30 , 36 .
In addition to this general commitment to openness, re3data has made its metadata available under the Creative Commons deed CC0. Due to adopting this highly permissive license, re3data metadata is strongly utilized by other parties, thereby enabling the development of new and innovative services and tools. Moreover, adaptable Jupyter Notebooks 37 have been published to facilitate the use of the re3data metadata. Additionally, workshops 38 have been arranged to support individuals in working with the notebooks and re3data data in general.
As a registry of RDRs, re3data also promotes Open Science by helping researchers find suitable repositories for publishing their data. For researchers who are looking for a repository that supports Open Science practices, re3data offers concise information on repository openness via its icon system. A recent analysis showed that most repositories indexed in re3data are considered ‘open’ 39 .
Lessons learned
The extensive reuse of re3data metadata increases its overall value, and participatory phases allow for incorporating different perspectives and experiences.
Quality assurance
For re3data, quality assurance encompasses all processes to ensure a service that meets the needs of a global community, as well as verifiably high-quality information.
High-quality RDR descriptions are at the core of re3data. Therefore, continuous efforts ensure that re3data metadata describes appropriately and correctly. Figure 1 shows the editorial process in re3data. Anyone, for example RDR operators, can submit repositories to be indexed in re3data by providing the repository name, URL, and some other core properties via a web form 40 . The re3data editorial board analyzes if the suggested RDR conforms with the re3data registration policy 40 . The policy requires that the RDR is operated by a legal entity, such as a library or university, and that the terms of use are clearly communicated. Additionally, the RDR must have a focus on storing and providing access to research data. If an RDR meets these requirements, it is indexed based on the re3data metadata schema. A member of the editorial board creates an initial RDR description, which is then reviewed by another editor. This approach has proven effective in resolving any inconsistencies in interpreting RDR characteristics. An indexing manual explains how the schema is to be applied and helps to ensure consistency between RDR descriptions. Once this review is complete, the RDR description is made publicly visible.

Schematic overview of the editorial process in re3data.
re3data applies a number of measures to ensure the long-term quality and consistency of RDR descriptions, including automated quality checks. For example, it is periodically checked whether the URLs of the RDR still resolve – if not, the entry of a RDR is reexamined. Figure 2 shows a screenshot of a re3data RDR description.

Screenshot of the re3data description of the research data repository PANGAEA 97 .
The re3data metadata schema on which RDR descriptions are based is reviewed and updated regularly to ensure that users’ changing information needs are met. Operators of an RDR, as well as any other person, can suggest changes to RDR descriptions by submitting a change request. A link for filing a change request can be found at the bottom of each RDR description in re3data. Once a change request has been submitted, a member of the editorial board will review the proposed changes and verify them against information on the RDR website. If the change request is deemed valid, the RDR description will be adapted accordingly.
As part of the project re3data COREF, quality assurance practices at RDRs were systematically investigated. The aim was to understand how RDRs ensure high-quality data, and to better reflect these measures in the metadata schema. The results of the study 41 , which were based on a survey among RDR operators, show that approaches to quality assurance are diverse and depend on the mission and scope of the RDR. However, RDRs are key actors in enabling quality assurance. Furthermore, there is a path dependence of data review on the review process of textual publications. In addition to the study, a workshop 42 , 43 was held with CoreTrustSeal that focused on quality assurance measures RDRs have implemented. CoreTrustSeal is a RDR certification organization launched in 2017 that defines requirements for base-level certification for RDRs 44 .
Combining manual and automated verification was shown to be most effective in ensuring that RDR descriptions remain consistent while meeting users’ diverse information needs.
Community engagement
For re3data, community engagement encompasses all activities that ensure interaction with the global RDR community in a participatory process.
Collaboration has always been a central principle for re3data. This is reflected in the fact that research communities, RDR providers, and other relevant stakeholders contribute significantly to the completeness and accuracy of the re3data metadata as well as its further technical and conceptual development. Examples include the participatory phase during the revision of the metadata schema, the involvement of important stakeholders in the development of the re3data Conceptual Model for User Stories 45 , 46 , or the activities that investigate data quality assurance at RDRs.
re3data engages in collaborations in various forms with diverse stakeholders, for example:
In collaboration with the Canadian Data Repositories Inventory Project and later with the Digital Research Alliance of Canada, both initiatives aiming at describing the Canadian landscape of RDRs comprehensively, descriptions of Canadian RDRs in re3data were improved, and additional RDRs were indexed 47 , 48 .
A collaboration initiative was initiated in Germany with the Helmholtz Metadata Collaboration (HMC). In this initiative, the descriptions of research data infrastructures within the Helmholtz Association are being reviewed and enhanced 49 .
re3data also engages in international networks, particularly within the Research Data Alliance (RDA). Activities focus on several RDA working and interest groups 50 , 51 , 52 that touch on topics relevant to RDR registries.
Combining strategies of engagement connects the service to its stakeholders and creates opportunities for collaboration and innovation.
Interoperability
For re3data, interoperability means facilitating interactions and metadata exchange with the global RDR community by relying on established standards.
Interoperability is a necessary condition to integrate a service into a global network of diverse stakeholders. International standards must be implemented to achieve this, for example with the re3data API 53 . The API can be used to query various parameters of an RDR as expressed in the metadata schema. The API enables the machine readability and integration of re3data metadata into other services. The re3data API is based on the RESTful API concept and is well-documented. Applying the HATEOAS principles 54 enables the decoupling of clients and servers, and thus allows for independent development of server functionality. This results in a robust interface that promotes interoperability and reduces barriers to future use. Also, re3data supports OpenSearch, a standard that enables interaction with search results in a format suitable for syndication and aggregation.
Interoperability also guides the development of the metadata schema: Established vocabularies and standards are used to describe RDRs wherever possible. Examples of standards used in the metadata schema include:
ISO 639-3 for language information, for example a RDR name
ISO 8601 for the use of date information on a RDR
DFG Classification of Subject Areas for subject information on a RDR
In addition, re3data pursues interoperability by jointly working on a mapping between the DFG Classification of Subject Areas used by re3data and the OECD Fields of Science classification used by DataCite 55 .
re3data records whether an RDR has obtained formal certification, for example by World Data System (WDS) or CoreTrustSeal. The certification status, along with other properties, is visualized by the re3data icon system that makes the core properties of RDRs easily accessible visually. The icon system provides information about the openness of the RDR and its data collection, the use of PID systems, as well as the certification status. The icon system can also be integrated into RDR websites via badges 56 . Figure 3 shows an example of a re3data badge.

The re3data badge integrated in the research data repository Health Atlas.
re3data captures information that might be relevant to metadata aggregator services, including API URLs, as well as the metadata standard(s) used. In offering this information in a standardized form, re3data fosters the development of services that span multiple collections, such as data portals. For example, as part of the FAIRsFAIR project work, re3data metadata has been integrated into DataCite Commons 57 to embed repository information in the DataCite PID Graph. This step not only improves the discoverability of repositories that support research data management in accordance with the FAIR principles but also serves as a basis for the development of new services such as the FAIR assessment tool F-UJI 35 , 58 .
The adherence to established standards facilitates the reuse of re3data metadata and increases the integration of the service into the broader Open Science landscape.
Developement
For re3data, continuous development ensures that the service is able to respond dynamically to evolving requirements of the global RDR community.
Maintaining a registry for an international community poses a significant challenge, particularly the continued provision of reliable technical operations and a governance structure capable of responding adequately to user demands. re3data has found suitable solutions to these challenges, which have enabled the service to be in operation for more than ten years. The long-standing collaboration with DataCite has contributed to this success. Participation in third-party-funded projects has facilitated the collaborative development of core service elements together with partners. Participation in committees such as those surrounding EOSC and RDA, as well as active engagement with the RDR community, have motivated discussions about changing requirements and led to the continuous evolution of the registry.
Responsibilities for specific tasks are divided among several entities, such as a working group responsible for guiding future directions of the service and the editorial board responsible for maintaining re3data metadata. In addition, there are teams responsible for technology as well as for outreach and communication. The working group includes experts from DataCite and other stakeholders, who discuss current requirements, prioritize developments, and ensure coordination with RDR operators worldwide. In addition to these entities, coordination with third-party-funded projects involving re3data is ongoing.
Continuous and agile development addresses the users’ constantly evolving needs. Operating a registry that meets those needs in the long term requires flexibility.
Sustainability
For re3data, sustainability means ensuring a long-term and reliable service to the global RDR community.
Maintaining the sustainable operation of a service like re3data beyond an initial project phase is a challenge. For re3data, the consortium model has proven effective, as the service is supported by a wide range of scientific institutions. This model, which is embedded in the governance of re3data, allows the operation of the service to be sustained through self-funding while also enabling important developments to be undertaken within the scope of third-party projects. Thanks to funding received from the DFG (re3data COREF project) and the European Union’s Horizon 2020 program (FAIRsFAIR project), significant investments have been made in the IT infrastructure and overall advancement of the service in recent years.
A strategy based on diverse revenue streams contributes to securing funding for the service long-term.
For re3data, being mentioned in policies comes with a responsibility for operating a reliable service and maintaining high-quality metadata for the global RDR community.
During the development of the re3data service, the partners engaged in dialogues with various stakeholders that were interested in using the registry to refer to RDRs in their policies. They might do this, for example, to recommend or mandate the use of RDRs in general for publishing research data, or the use of a specific RDR. Today, re3data is mentioned in the policies of several funding agencies, scientific institutions, and journals. These actors use re3data to identify RDRs operated by specific academic institutions that were developed using funding from a funding organization, or that store data that are the basis of a journal article. Examples of policies and policy guidance documents that refer to re3data:
Academic institutions:
Brandon University, Canada 59
Technische Universität Berlin, Germany 60
University of Edinburgh, United Kingdom 61
University of Eastern Finland 62
Western Norway University of Applied Sciences 63
Bill & Melinda Gates Foundation, USA 64
European Commission 65 and ERC, EU 66
National Science Foundation (NSF), USA 67
NIH, USA 68
Journals and Publishers:
Taylor & Francis, United Kingdom 69
Springer Nature, United Kingdom 70
Sage, United Kingdom 71
Wiley, Germany 72
Regular searches are conducted to track mentions of re3data in policies. On the re3data website, a list of policies referring to re3data is maintained and regularly updated 73 .
As a result of being mentioned in policies so frequently, re3data receives inquiries from researchers for information on listed RDRs almost daily. These inquiries are usually forwarded to the RDR directly.
Policies represent firm support for research data management by academic institutions, funders, and journals and publishers. By facilitating the search for and referencing of RDRs in policies, re3data further promotes Open Science practices.
For re3data, data reuse is one of the main objectives, ensuring that third parties can rely on re3data metadata to build services that support the global RDR community.
Because re3data metadata are published as open data, third parties are free to integrate it into their systems. Several service operators have already taken advantage of this opportunity. In general, there are three types of services that work with re3data data:
Services for finding and describing RDRs: These services usually work with a subset of re3data metadata. Sometimes, the data is manually curated, and then integrated into external services based on specific parameters. Examples include:
DARIAH-EU has developed its Data Deposit Recommendation Service based on a subset of re3data metadata, which helps humanities researchers find suitable RDRs 74 , 75 .
The American Geophysical Union (AGU) has utilized re3data metadata to create a dedicated gateway for RDRs in the geosciences with its Repository Finder tool 76 , 77 , which was later incorporated into the DataCite Commons web search interface.
Services for monitoring the landscape of RDRs: These services analyze re3data metadata using specific parameters and visualize the results. Examples include:
OpenAIRE has integrated re3data metadata into its Open Science Observatory to provide information on RDRs that are part of OpenAIRE 78 .
The European Commission operates the Open Science Monitor, a dashboard that analyzes re3data metadata. The following metrics are displayed: number of RDRs by subject, number of RDRs by access type, and number of RDRs by country 79 , 80 .
Services for assessing RDRs: These services use re3data metadata and other data sources to evaluate RDRs more comprehensively. Examples include:
The F-UJI Automated FAIR Data Assessment Tool is a web-based service that assesses the degree to which individual datasets conform to the FAIR Data principles. The tool utilizes re3data metadata to evaluate characteristics of the RDR that store the datasets 81 .
Charité Metrics Dashboard, a dashboard on responsible research practices from the Berlin Institute of Health at Charité in Berlin, Germany, builds on F-UJI data and combines this information with additional re3data metadata 82 .
These examples underscore the value Open Science tools like re3data generate by making their data openly available without restrictions. As a result of the permissive licensing, re3data metadata can be used for new and innovative applications, establishing re3data as a vital data provider for the global Open Science community.
Permissive licensing and extensive collaboration have turned re3data into a key data provider in the Open Science ecosystem.
Metadata for research
For re3data, providing RDR descriptions also means offering metadata that enables analyses of the global RDR community.
In research disciplines studying data infrastructures, for example library and information science or science and technology studies, re3data is regularly used for information on the state of research infrastructures. As re3data has been mapping the landscape of data infrastructures for ten years, it has evolved into a tool that is used for monitoring Open Science activities, research data management, and other topics. Studies reusing re3data metadata include analyses of the overall RDR landscape, the landscape of RDRs in a specific domain, or the RDR landscape of a region or country. Some examples of studies reusing re3data metadata for research are:
Overall studies: Boyd 83 examined the extent to which RDR exhibit properties of infrastructures. Khan & Ahangar 84 and Hansson & Dahlgren 85 focused on the openness of RDRs from a global perspective.
Regional studies: Bauer et al . 86 examined Austrian RDRs, Cho 87 Asian RDRs, Milzow et al . 88 Swiss RDRs, and Schöpfel 89 French RDRs.
Domain studies: Gómez et al . 90 and Li & Liu 91 investigated the landscape of RDRs in humanities and social science. Prashar & Chander 92 focused on computer science.
Members of the re3data team have also published studies reusing re3data metadata, including studies of the global state of RDR 93 , openness 39 , and quality assurance of RDRs 41 .
In response to the demand for information on the RDR landscape, the re3data graphical user interface provides various visualizations of the current state of RDRs. For example, re3data metadata can be browsed visually by subject category and on a map. In addition, the metrics page of re3data shows how RDRs are distributed across central properties of the metadata schema 94 .
The start page of re3data includes a recommendation for how to cite the service if it was used as a source in papers:
re3data - Registry of Research Data Repositories. https://doi.org/10.17616/R3D last accessed: [date].
In citing the service, the use of re3data as a data source in research and the service in general becomes more visible.
The increasing number of studies reusing re3data metadata shows a real demand for reliable information on the global RDR landscape.
Communications
For re3data, communication means engaging in dialogue with relevant stakeholders in the global RDR community.
Broad-based public relations are very important for a service catering to a global community. In recent years, re3data has pursued a communication strategy that includes the following elements:
Conference presentations: It has been proven effective to represent the service at conferences, paving new ways to engage with the community.
Mailing lists: The re3data team regularly informs members of a variety of mailing lists about news from the service.
Social media: re3data communicates current developments via Mastodon ( https://openbiblio.social/@re3data ) and Twitter ( https://twitter.com/re3data ).
Help desk: Communication via the help desk is essential for the re3data service. The help desk team answers questions about RDR descriptions, as well as general questions about data management. The number of general inquiries, e.g., for finding a suitable RDR, has increased over the years.
Blog: The project re3data COREF operates a blog that informs about developments in the project 95 . Some blog posts are also published in the DataCite Blog 96 .
Establishing broad-based communication channels enables the service to reach and engage with relevant stakeholders in a variety of formats.
Over the past ten years, re3data has evolved into a reliable and valuable Open Science service. The service offers high-quality RDR descriptions from all disciplines and regions. re3data is managed cooperatively; new features are developed in third-party projects.
Four basic principles guide the development of re3data: openness, community engagement, high-quality metadata, and ongoing consideration of users’ needs. These principles ensure that the activities of the service align with the values and interests of its stakeholders. In the context of these principles, ten key issues for the operation of the service have emerged over the last ten years.
In the past two years, following in-depth conversations with diverse parties, a new conceptual model for re3data was developed 45 . This process contributed to a better understanding of the needs of RDR operators and other stakeholders. The conceptual model will guide developments of re3data, embedding the service further in the evolving ecosystem of Open Science services with the intention to support researchers, scientific institutions, funding organizations, publishers, and journals in implementing the FAIR principles and realizing an interconnected global research data ecosystem.
This article describes the history and current status of the global registry re3data. Based on operational experience, it reflects on some of the basic principles that have shaped the service since its inception.
Having been launched more than ten years ago, re3data is now the most comprehensive registry of RDRs. The service currently describes more than 3,000 RDRs and caters to a diverse user base including RDR operators, researchers, funding agencies, and publishers. Ten key issues that are relevant for operating an Open Science service like re3data are identified, discussed, and reflected: openness, quality assurance, community engagement, interoperability, development, sustainability, policies, data reuse, metadata for research, and communications. For each of the key issues, we provide a definition, explain the approach applied by the re3data service, and describe what the re3data team learned from working on each issue.
Among other aspects, the paper outlines the design, governance, and objectives of re3data, providing important background information on a service that has evolved into a central data source on the global RDR landscape.
Data availability
The re3data RDR descriptions are openly available via https://re3data.org under a CC0 deed.
Code availability
The source code of the directory is not publicly released. The re3data subject ontology and several Jupyter notebooks with examples for using the re3data API can be found at: https://github.com/re3data .
National Science Foundation Cyberinfrastructure Council. Cyberinfrastructure Vision for 21st Century Discovery 2007 . https://www.nsf.gov/pubs/2007/nsf0728/nsf0728.pdf (2023).
National Science Foundation. Revolutionizing Science and Engineering through Cyberinfrastructure: Report of the National Science Foundation Blue-Ribbon Advisory Panel on Cyberinfrastructure 2003 . https://www.nsf.gov/cise/sci/reports/atkins.pdf (2023).
How to encourage the right behaviour. Nature 416 , 1–1 (2002).
Let Data Speak to Data. Nature 438 , 531–531 (2005).
The Royal Society. Science as an Open Enterprise https://royalsociety.org/~/media/Royal_Society_Content/policy/projects/sape/2012-06-20-SAOE.pdf (2023).
Data for the masses. Nature 457 , 129–129 (2009).
Data’s shameful neglect. Nature 461 , 145–145 (2009).
Science Staff. Challenges and opportunities. Science 331 , 692–693 (2011).
Article Google Scholar
OECD. OECD Principles and Guidelines for Access to Research Data from Public Funding (2007).
European Commission. Commission Recommendation of 17 July 2012 on Access to and Preservation of Scientific Information (2012).
Wilkinson, M. D. et al . The FAIR guiding principles for scientific data management and stewardship. Scientific Data 3 , 160018 (2016).
Pampel, H. & Bertelmann, R. in Handbuch Forschungsdatenmanagement (2011) . https://opus4.kobv.de/opus4-fhpotsdam/frontdoor/index/index/docId/195 (2023).
European Commission. European Cloud Initiative - Building a Competitive Data and Knowledge Economy in Europe (2016).
Michener,W. et al . DataONE: Data observation network for earth preserving data and enabling innovation in the biological and environmental sciences. D-Lib Magazine 17 (2011).
Parsons, M. A. The Research Data Alliance: Implementing the technology, practice and connections of a data infrastructure. Bul. Am. Soc. Info. Sci. Tech. 39 , 33–36 (2013).
Borgman, C. L. Big Data, Little Data, No Data: Scholarship in the Networked World (The MIT Press, 2016).
Manghi, P., Manola, N., Horstmann, W. & Peters, D. An Infrastructure for Managing EC Funded Research Output - The OpenAIRE Project 2010 . https://publications.goettingen-research-online.de/handle/2/57068 (2023).
Blanke, T., Bryant, M., Hedges, M., Aschenbrenner, A. & Priddy, M. Preparing DARIAH in 2011 IEEE Seventh International Conference on eScience , 158–165 (IEEE, 2011).
Hey, T. & Trefethen, A. in Scientific Collaboration on the Internet (eds Olson, G. M., Zimmerman, A. & Bos, N.) 14–31 (The MIT Press, 2008).
National Science Board. Digital Research Data Sharing and Management 2011 . https://www.nsf.gov/nsb/publications/2011/nsb1124.pdf (2023).
Deutsche Forschungsgemeinschaft. Empfehlungen Zur Gesicherten Aufbewahrung Und Bereitstellung Digitaler Forschungsprimar daten 2009 . https://www.dfg.de/download/pdf/foerderung/programme/lis/ua_inf_empfehlungen_200901.pdf (2023).
Allianz der deutschen Wissenschaftsorganisationen. Grundsatze Zum Umgang Mit Forschungsdaten https://doi.org/10.2312/ALLIANZOA.019 (2010).
DINI Working Group Electronic Publishing. Positionspapier Forschungsdaten. https://doi.org/10.18452/1489 (2009).
OpenDOAR. https://beta.jisc.ac.uk/opendoar (2023).
Deutsche Forschungsgemeinschaft. Re3data.Org - Registry of Research Data Repositories. Community Building, Net working and Research Data Management Services GEPRIS . https://gepris.dfg.de/gepris/projekt/209240528?context=projekt&task=showDetail&id=209240528& (2023).
Pampel, H. et al . Making research data repositories visible: The re3data.org registry. PLoS ONE 8 (ed Suleman, H.) e78080 (2013).
Witt, M. Databib: Cataloging the World’s Data Repositories 2013 . https://ir.inflibnet.ac.in:8443/ir/handle/1944/1778 (2023).
Witt, M. & Giarlo, M. Databib: IMLS LG-46-11-0091-11 Final Report (White Paper) 2012 . https://docs.lib.purdue.edu/libreports/2 (2023).
Buys, M. Strategic Collaboration 2022 . https://datacite.org/assets/re3data%20and%20DataCite_openHours.pdf (2023).
Vierkant, P. et al . Metadata Schema for the Description of Research Data Repositories: version 2.2 . https://doi.org/10.2312/RE3.006 (2014).
Brase, J. DataCite - A Global Registration Agency for Research Data in 2009 Fourth International Conference on Cooperation and Promotion of Information Resources in Science and Technology , 257–261 (IEEE, 2009).
Witt, M. DataCite’s Re3data Wins Oberly Award from the American Libraries Association https://doi.org/10.5438/0001-0HN* .
Deutsche Forschungsgemeinschaft. Re3data – Offene Und Nutzerorientierte Referenz Fur Forschungsdatenrepositorien (Re3data COREF) GEPRIS . https://gepris.dfg.de/gepris/projekt/422587133?context=projekt&task=showDetail&id=422587133& (2023).
re3data COREF. Re3data COREF Project https://coref.project.re3data.org/project (2023).
FAIRsFAIR. Repository Discovery in DataCite Commons https://www.fairsfair.eu/repository-discovery-datacite-commons (2023).
Strecker, D. et al . Metadata Schema for the Description of Research Data Repositories: version 3.1 . https://doi.org/10.48440/RE3.010 (2021).
re3data. Examples for using the re3data API GitHub . https://github.com/re3data/using_the_re3data_API (2023).
Schabinger, R., Strecker, D., Wang, Y. & Weisweiler, N. L. Introducing Re3data – the Registry of Research Data Repositories . https://doi.org/10.5281/ZENODO.5592123 (2021).
re3data COREF. How Open Are Repositories in Re3data? https://coref.project.re3data.org/blog/how-open-are-repositories-in-re3data (2023).
re3data. Suggest https://www.re3data.org/suggest (2023).
Kindling, M. & Strecker, D. Data quality assurance at research data repositories. Data Science Journal 21 , 18 (2022).
Kindling, M. et al . Report on re3data COREF/CoreTrustSeal workshop on quality management at research data repositories. Informationspraxis 8 (2022).
Kindling, M., Strecker, D. & Wang, Y. Data Quality Assurance at Research Data Repositories: Survey Data (Zenodo, 2022).
L’Hours, H., Kleemola, M. & De Leeuw, L. CoreTrustSeal: From academic collaboration to sustainable services. IASSIST Quarterly 43 , 1–17 (2019).
Vierkant, P. et al . Re3data Conceptual Model for User Stories . https://doi.org/10.48440/RE3.012 (2021).
Weisweiler, N. L. et al . Re3data Stakeholder Survey and Workshop Report . https://doi.org/10.48440/RE3.013 (2021).
Webster, P. Integrating Discovery and Access to Canadian Data Sources. Contributing to Academic Library Data Services by Sharing Data Source Knowledge Nation Wide in. In collab. with Haigh, S. (2017). https://library.ifla.org/id/eprint/2514/ (2023).
Dearborn, D. et al . Summary Report: Canadian Research Data Repositories and the Re3data Repository Registry in collab. with Labrador, A. & Purcell, F. (2023).
Helmholtz Open Science Office. Community Building for Research Data Repositories in Helmholtz https://os.helmholtz.de/en/open-science-in-helmholtz/networking/community-building-research-data-repositories/ (2023).
Research Data Alliance. Libraries for Research Data IG https://www.rd-alliance.org/groups/libraries-research-data.html (2023).
Research Data Alliance. Data Repository Attributes WG https://www.rd-alliance.org/groups/data-repository-attributes-wg (2023).
Research Data Alliance. Data GranularityWG https://www.rd-alliance.org/groups/data-granularity-wg (2023).
re3data. API https://www.re3data.org/api/doc (2023).
HATEOAS https://en.wikipedia.org/w/index.php?title=HATEOAS&oldid=1141349344 (2023).
Ninkov, A. B. et al . Mapping Metadata - Improving Dataset Discipline Classification . https://doi.org/10.5281/ZENODO.6948238 (2022).
Pampel, H. Re3data.Org Reaches a Milestone and Begins Offering Badges https://doi.org/10.5438/KTR7-ZJJH .
DataCite. DataCite Commons https://commons.datacite.org/repositories (2023).
Wimalaratne, S. et al . D4.7 Tools for Finding and Selecting Certified Repositories for Researchers and Other Stakeholders. https://doi.org/10.5281/ZENODO.6090418 (2022).
Brandon University. Research Data Management Strategy https://www.brandonu.ca/research/files/Research-Data-Strategy.pdf (2023).
Technical University Berlin. Research Data Policy of TU Berlin https://www.tu.berlin/en/working-at-tu-berlin/important-documents/guidelinesdirectives/research-data-policy (2023).
The University of Edinburgh. Research Data Management Policy https://www.ed.ac.uk/information-services/about/policies-and-regulations/research-data-policy (2023).
University of Eastern Finland. Data management at the end of research https://www.uef.fi/en/datasupport/data-management-at-the-end-of-research (n. d.).
Western Norway University of Applied Sciences. Research Data https://www.hvl.no/en/library/research-and-publish/publishing/research-data/ (2023).
Gates Open Access Policy. Data Sharing Requirements https://openaccess.gatesfoundation.org/how-to-comply/data-sharing-requirements/ (2023).
European Commission. Horizon Europe (HORIZON) - Programme Guide 2022 . https://ec.europa.eu/info/funding-tenders/opportunities/docs/2021-2027/horizon/guidance/programme-guide_horizon_en.pdf (2023).
European Research Council. Open Research Data and Data Management Plans - Information for ERC Grantee 2022 . https://erc.europa.eu/sites/default/files/document/file/ERC_info_document-Open_Research_Data_and_Data_Management_Plans.pdf (2023).
National Science Foundation. Dear Colleague Letter: Effective Practices for Making Research Data Discoverable and Citable (Data Sharing) https://www.nsf.gov/pubs/2022/nsf22055/nsf22055.jsp (2023).
National Institutes of Health. Repositories for Sharing Scientific Data https://sharing.nih.gov/data-management-and-sharing-policy/sharing-scientific-data/repositories-for-sharing-scientific-data (2023).
Taylor and Francis. Understanding and Using Data Repositories https://authorservices.taylorandfrancis.com/data-sharing/share-your-data/repositories/ (2023).
Scientific Data. Data Repository Guidance https://www.nature.com/sdata/policies/repositories (2023).
SAGE. Research Data Sharing FAQs https://us.sagepub.com/en-us/nam/research-data-sharing-faqs (2023).
Wiley. Data Sharing Policy https://authorservices.wiley.com/author-resources/Journal-Authors/open-access/data-sharing-citation/data-sharing-policy.html (2023).
re3data. Publications https://www.re3data.org/publications (2023).
Buddenbohm, S., de Jong, M., Minel, J.-L. & Moranville, Y. Find research data repositories for the humanities - the data deposit recommendation service. Int. J. Digit. Hum. 1 , 343–362 (2021).
DARIAH. DDRS https://ddrs-dev.dariah.eu/ddrs/ (2023).
Witt, M. et al . in Digital Libraries: Supporting Open Science (eds Manghi, P., Candela, L. & Silvello, G.) 86–96 (Springer, 2019).
DataCite. DataCite Repository Selector https://repositoryfinder.datacite.org/ (2023).
OpenAIRE. Open Science Observatory https://osobservatory.openaire.eu/home (2023).
The Lisbon Council. Open Science Monitor Methodological Note 2019 . https://research-and-innovation.ec.europa.eu/system/files/2020-01/open_science_monitor_methodological_note_april_2019.pdf (2023).
European Commission. Facts and Figures for Open Research Data https://research-and-innovation.ec.europa.eu/strategy/strategy-2020-2024/our-digital-future/open-science/open-science-monitor/facts-and-figures-open-research-data_en (2023).
Devaraju, A. & Huber, R. F-UJI - An Automated FAIR Data Assessment Tool Zenodo . https://doi.org/10.5281/ZENODO.4063720 (2023).
Berlin Institute of Health. ChariteMetrics Dashboard https://quest-dashboard.charite.de/#tabMethods (2023).
Boyd, C. Understanding research data repositories as infrastructures. P. J. Asso. for Info. Science & Tech. 58 , 25–35 (2021).
Khan, N. A. & Ahangar, H. Emerging Trends in Open Research Data in 2017 9th International Conference on Information and Knowledge Technology , 141–146 (2017).
Hansson, K. & Dahlgren, A. Open research data repositories: Practices, norms, and metadata for sharing images. J. Asso. for Info. Science & Tech. 73 , 303–316 (2022).
Bauer, B. & Ferus, A. Osterreichische Repositorien in OpenDOAR und re3data.org: Entwicklung und Status von Infrastrukturen fur Green Open Access und Forschungsdaten. Mitteilungen der VOB 71 , 70–86 (2018).
Cho, J. Study of Asian RDR based on re3data. EL 37 , 302–313 (2019).
Milzow, K., von Arx, M., Sommer, C., Cahenzli, J. & Perini, L. Open Research Data: SNSF Monitoring Report 2017-2018. https://doi.org/10.5281/ZENODO.3618123 (2020).
Schopfel, J. in Schopfel, J. & Rebouillat, V. Research Data Sharing and Valorization: Developments, Tendencies, Models (Wiley, 2022).
Gomez, N.-D., Mendez, E. & Hernandez-Perez, T. Data and metadata research in the social sciences and humanities: An approach from data repositories in these disciplines. EPI 25 , 545 (2016).
Li, Z. & Liu, W. Characteristics Analysis of Research Data Repositories in Humanities and Social Science - Based on Re3data.Org in 4th International Symposium on Social Science (Atlantis Press, 2018).
Prashar, P. & Chander, H. Research Data Management through Research Data Repositories in the Field of Computer Sciences https://ir.inflibnet.ac.in:8443/ir/bitstream/1944/2400/1/43.pdf (2023).
Kindling, M. et al . The landscape of research data repositories in 2015: A re3data analysis. D-Lib Magazine 23 (2017).
re3data. Statistics https://www.re3data.org/metrics (2023).
re3data COREF. Re3data COREF Blog https://coref.project.re3data.org/ (2023).
Witt, M., Weisweiler, N. L. & Ulrich, R. Happy 10th Anniversary, Re3data! DataCite . https://doi.org/10.5438/MQW0-YT07 .
Felden, J. et al . PANGAEA - Data Publisher for Earth & Environmental Science. Scientific Data 10 , 347 (2023).
Article ADS PubMed PubMed Central Google Scholar
Download references
Acknowledgements
This work has been supported by the German Research Foundation (DFG) under the projects re3data.org - Registry of Research Data Repositories. Community Building, Networking and Research Data Management Services (Grant ID: 209240528) and re3data – Offene und nutzerorientierte Referenz für Forschungsdatenrepositorien (re3data COREF) (Grant ID: 422587133). The article processing charge was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – 491192747 and the Open Access Publication Fund of Humboldt-Universität zu Berlin.
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and affiliations.
Humboldt-Universität zu Berlin, Berlin School of Library and Information Science, Berlin, Germany
Heinz Pampel, Dorothea Strecker & Vivien Petras
Helmholtz Association, Helmholtz Open Science Office, Potsdam, Germany
Heinz Pampel, Nina Leonie Weisweiler, Roland Bertelmann & Lea Maria Ferguson
University of Purdue, Distributed Data Curation Center, West Lafayette, IN, USA
Michael Witt
DataCite - International Data Citation Initiative e. V, Hannover, Germany
Paul Vierkant & Matthew Buys
GFZ German Research Centre for Geosciences, Library and Information Services, Potsdam, Germany
Kirsten Elger
Freie Universität Berlin, Open-Access-Büro Berlin, Berlin, Germany
Maxi Kindling
University of Bath, Library, Bath, UK
Rachael Kotarski
You can also search for this author in PubMed Google Scholar
Contributions
H.P., N.L.W., D.S. and M.W. wrote the first draft. P.V., E.K., R.B., M.B., L.M.F., M.K., R.K. and V.P. provided critical feedback and helped shape the manuscript. H.P., N.L.W., D.S., M.W., P.V., E.K., R.B., M.B., L.M.F., M.K., R.K. and V.P. contributed to the final writing and revision of the manuscript.
Corresponding authors
Correspondence to Heinz Pampel or Nina Leonie Weisweiler .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Pampel, H., Weisweiler, N.L., Strecker, D. et al. re3data – Indexing the Global Research Data Repository Landscape Since 2012. Sci Data 10 , 571 (2023). https://doi.org/10.1038/s41597-023-02462-y
Download citation
Received : 13 July 2023
Accepted : 09 August 2023
Published : 29 August 2023
DOI : https://doi.org/10.1038/s41597-023-02462-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Garbage in, garbage out: mitigating risks and maximizing benefits of ai in research.
- Brooks Hanson
- Shelley Stall
Nature (2023)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

Redirect Notice

Repositories for Sharing Scientific Data
In general, NIH does not endorse or require sharing data in any particular repository, although some initiatives and funding opportunities will have individual requirements. Overall, NIH encourages researchers to select the repository that is most appropriate for their data type and discipline. See Selecting a Data Repository .
Browse through this listing of NIH-supported repositories to learn more about some places to share scientific data. Note that this list is not exhaustive. Select the link provided in the “Data Submission Policy” column to find data submission instructions for each repository.
In addition, NIH provides a listing of generalist repositories that accept all data types .
NIH-supported Scientific Data Repositories*
Join thousands of product people at Insight Out Conf on April 11. Register free.
Insights hub solutions
Analyze data
Uncover deep customer insights with fast, powerful features, store insights, curate and manage insights in one searchable platform, scale research, unlock the potential of customer insights at enterprise scale.
Featured reads

Inspiration
Three things to look forward to at Insight Out

Tips and tricks
Make magic with your customer data in Dovetail

Four ways Dovetail helps Product Managers master continuous product discovery
Events and videos
© Dovetail Research Pty. Ltd.
What is a research repository, and why do you need one?
Last updated
31 January 2024
Reviewed by
Miroslav Damyanov
Without one organized source of truth, research can be left in silos, making it incomplete, redundant, and useless when it comes to gaining actionable insights.
A research repository can act as one cohesive place where teams can collate research in meaningful ways. This helps streamline the research process and ensures the insights gathered make a real difference.
- What is a research repository?
A research repository acts as a centralized database where information is gathered, stored, analyzed, and archived in one organized space.
In this single source of truth, raw data, documents, reports, observations, and insights can be viewed, managed, and analyzed. This allows teams to organize raw data into themes, gather actionable insights, and share those insights with key stakeholders.
Ultimately, the research repository can make the research you gain much more valuable to the wider organization.
- Why do you need a research repository?
Information gathered through the research process can be disparate, challenging to organize, and difficult to obtain actionable insights from.
Some of the most common challenges researchers face include the following:
Information being collected in silos
No single source of truth
Research being conducted multiple times unnecessarily
No seamless way to share research with the wider team
Reports get lost and go unread
Without a way to store information effectively, it can become disparate and inconclusive, lacking utility. This can lead to research being completed by different teams without new insights being gathered.
A research repository can streamline the information gathered to address those key issues, improve processes, and boost efficiency. Among other things, an effective research repository can:
Optimize processes: it can ensure the process of storing, searching, and sharing information is streamlined and optimized across teams.
Minimize redundant research: when all information is stored in one accessible place for all relevant team members, the chances of research being repeated are significantly reduced.
Boost insights: having one source of truth boosts the chances of being able to properly analyze all the research that has been conducted and draw actionable insights from it.
Provide comprehensive data: there’s less risk of gaps in the data when it can be easily viewed and understood. The overall research is also likely to be more comprehensive.
Increase collaboration: given that information can be more easily shared and understood, there’s a higher likelihood of better collaboration and positive actions across the business.
- What to include in a research repository
Including the right things in your research repository from the start can help ensure that it provides maximum benefit for your team.
Here are some of the things that should be included in a research repository:
An overall structure
There are many ways to organize the data you collect. To organize it in a way that’s valuable for your organization, you’ll need an overall structure that aligns with your goals.
You might wish to organize projects by research type, project, department, or when the research was completed. This will help you better understand the research you’re looking at and find it quickly.
Including information about the research—such as authors, titles, keywords, a description, and dates—can make searching through raw data much faster and make the organization process more efficient.
All key data and information
It’s essential to include all of the key data you’ve gathered in the repository, including supplementary materials. This prevents information gaps, and stakeholders can easily stay informed. You’ll need to include the following information, if relevant:
Research and journey maps
Tools and templates (such as discussion guides, email invitations, consent forms, and participant tracking)
Raw data and artifacts (such as videos, CSV files, and transcripts)
Research findings and insights in various formats (including reports, desks, maps, images, and tables)
Version control
It’s important to use a system that has version control. This ensures the changes (including updates and edits) made by various team members can be viewed and reversed if needed.
- What makes a good research repository?
The following key elements make up a good research repository that’s useful for your team:
Access: all key stakeholders should be able to access the repository to ensure there’s an effective flow of information.
Actionable insights: a well-organized research repository should help you get from raw data to actionable insights faster.
Effective searchability : searching through large amounts of research can be very time-consuming. To save time, maximize search and discoverability by clearly labeling and indexing information.
Accuracy: the research in the repository must be accurately completed and organized so that it can be acted on with confidence.
Security: when dealing with data, it’s also important to consider security regulations. For example, any personally identifiable information (PII) must be protected. Depending on the information you gather, you may need password protection, encryption, and access control so that only those who need to read the information can access it.
- How to create a research repository
Getting started with a research repository doesn’t have to be convoluted or complicated. Taking time at the beginning to set up the repository in an organized way can help keep processes simple further down the line.
The following six steps should simplify the process:
1. Define your goals
Before diving in, consider your organization’s goals. All research should align with these business goals, and they can help inform the repository.
As an example, your goal may be to deeply understand your customers and provide a better customer experience. Setting out this goal will help you decide what information should be collated into your research repository and how it should be organized for maximum benefit.
2. Choose a platform
When choosing a platform, consider the following:
Will it offer a single source of truth?
Is it simple to use
Is it relevant to your project?
Does it align with your business’s goals?
3. Choose an organizational method
To ensure you’ll be able to easily search for the documents, studies, and data you need, choose an organizational method that will speed up this process.
Choosing whether to organize your data by project, date, research type, or customer segment will make a big difference later on.
4. Upload all materials
Once you have chosen the platform and organization method, it’s time to upload all the research materials you have gathered. This also means including supplementary materials and any other information that will provide a clear picture of your customers.
Keep in mind that the repository is a single source of truth. All materials that relate to the project at hand should be included.
5. Tag or label materials
Adding metadata to your materials will help ensure you can easily search for the information you need. While this process can take time (and can be tempting to skip), it will pay off in the long run.
The right labeling will help all team members access the materials they need. It will also prevent redundant research, which wastes valuable time and money.
6. Share insights
For research to be impactful, you’ll need to gather actionable insights. It’s simpler to spot trends, see themes, and recognize patterns when using a repository. These insights can be shared with key stakeholders for data-driven decision-making and positive action within the organization.
- Different types of research repositories
There are many different types of research repositories used across organizations. Here are some of them:
Data repositories: these are used to store large datasets to help organizations deeply understand their customers and other information.
Project repositories: data and information related to a specific project may be stored in a project-specific repository. This can help users understand what is and isn’t related to a project.
Government repositories: research funded by governments or public resources may be stored in government repositories. This data is often publicly available to promote transparent information sharing.
Thesis repositories: academic repositories can store information relevant to theses. This allows the information to be made available to the general public.
Institutional repositories: some organizations and institutions, such as universities, hospitals, and other companies, have repositories to store all relevant information related to the organization.
- Build your research repository in Dovetail
With Dovetail, building an insights hub is simple. It functions as a single source of truth where research can be gathered, stored, and analyzed in a streamlined way.
1. Get started with Dovetail
Dovetail is a scalable platform that helps your team easily share the insights you gather for positive actions across the business.
2. Assign a project lead
It’s helpful to have a clear project lead to create the repository. This makes it clear who is responsible and avoids duplication.
3. Create a project
To keep track of data, simply create a project. This is where you’ll upload all the necessary information.
You can create projects based on customer segments, specific products, research methods, or when the research was conducted. The project breakdown will relate back to your overall goals and mission.
4. Upload data and information
Now, you’ll need to upload all of the necessary materials. These might include data from customer interviews, sales calls, product feedback, usability testing, and more. You can also upload supplementary information.
5. Create a taxonomy
Create a taxonomy to organize the data effectively by ensuring that each piece of information will be tagged and organized.
When creating a taxonomy, consider your goals and how they relate to your customers. Ensure those tags are relevant and helpful.
6. Tag key themes
Once the taxonomy is created, tag each piece of information to ensure you can easily filter data, group themes, and spot trends and patterns.
With Dovetail, automatic clustering helps quickly sort through large amounts of information to uncover themes and highlight patterns. Sentiment analysis can also help you track positive and negative themes over time.
7. Share insights
With Dovetail, it’s simple to organize data by themes to uncover patterns and share impactful insights. You can share these insights with the wider team and key stakeholders, who can use them to make customer-informed decisions across the organization.
8. Use Dovetail as a source of truth
Use your Dovetail repository as a source of truth for new and historic data to keep data and information in one streamlined and efficient place. This will help you better understand your customers and, ultimately, deliver a better experience for them.
Get started today
Go from raw data to valuable insights with a flexible research platform
Editor’s picks
Last updated: 21 December 2023
Last updated: 16 December 2023
Last updated: 17 February 2024
Last updated: 19 November 2023
Last updated: 5 March 2024
Last updated: 15 February 2024
Last updated: 11 March 2024
Last updated: 12 December 2023
Last updated: 6 March 2024
Last updated: 10 April 2023
Last updated: 20 December 2023
Latest articles
Related topics, log in or sign up.
Get started for free

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- PeerJ Comput Sci
Nine best practices for research software registries and repositories
Daniel garijo.
1 Universidad Politécnica de Madrid, Madrid, Spain
Hervé Ménager
2 Institut Pasteur, Université Paris Cité, Bioinformatics and Biostatistics Hub, Paris, France
Lorraine Hwang
3 University of California, Davis, Davis, California, United States
Ana Trisovic
4 Harvard University, Boston, Massachusetts, United States
Michael Hucka
5 California Institute of Technology, Pasadena, California, United States
Thomas Morrell
Alice allen.
6 University of Maryland, College Park, MD, United States
Task Force on Best Practices for Software Registries
7 FORCE11 Software Citation Implementation Working Group
SciCodes Consortium
8 Consortium of Scientific Software Registries and Repositories
Associated Data
The following information was supplied regarding data availability:
There is no data or code associated with this publication.
Scientific software registries and repositories improve software findability and research transparency, provide information for software citations, and foster preservation of computational methods in a wide range of disciplines. Registries and repositories play a critical role by supporting research reproducibility and replicability, but developing them takes effort and few guidelines are available to help prospective creators of these resources. To address this need, the FORCE11 Software Citation Implementation Working Group convened a Task Force to distill the experiences of the managers of existing resources in setting expectations for all stakeholders. In this article, we describe the resultant best practices which include defining the scope, policies, and rules that govern individual registries and repositories, along with the background, examples, and collaborative work that went into their development. We believe that establishing specific policies such as those presented here will help other scientific software registries and repositories better serve their users and their disciplines.
Introduction
Research software is an essential constituent in scientific investigations ( Wilson et al., 2014 ; Momcheva & Tollerud, 2015 ; Hettrick, 2018 ; Lamprecht et al., 2020 ), as it is often used to transform and prepare data, perform novel analyses on data, automate manual processes, and visualize results reported in scientific publications ( Howison & Herbsleb, 2011 ). Research software is thus crucial for reproducibility and has been recognized by the scientific community as a research product in its own right—one that should be properly described, accessible, and credited by others ( Smith, Katz & Niemeyer, 2016 ; Chue Hong et al., 2021 ). As a result of the increasing importance of computational methods, communities such as Research Data Alliance (RDA) ( Berman & Crosas, 2020 ) ( https://www.rd-alliance.org/ ) and FORCE11 ( Bourne et al., 2012 ) ( https://www.force11.org/ ) emerged to enable collaboration and establish best practices. Numerous software services that enable open community development of and access to research source code, such as GitHub ( https://github.com/ ) and GitLab ( https://gitlab.com ), appeared and found a role in science. General-purpose repositories, such as Zenodo ( CERN & OpenAIRE, 2013 ) and FigShare ( Thelwall & Kousha, 2016 ), have expanded their scope beyond data to include software, and new repositories, such as Software Heritage ( Di Cosmo & Zacchiroli, 2017 ), have been developed specifically for software. A large number of domain-specific research software registries and repositories have emerged for different scientific disciplines to ensure dissemination and reuse among their communities ( Gentleman et al., 2004 ; Peckham, Hutton & Norris, 2013 ; Greuel & Sperber, 2014 ; Allen & Schmidt, 2015 ; Gil, Ratnakar & Garijo, 2015 ; Gil et al., 2016 ).
Research software registries are typically indexes or catalogs of software metadata, without any code stored in them; while in research software repositories , software is both indexed and stored ( Lamprecht et al., 2020 ). Both types of resource improve software discoverability and research transparency, provide information for software citations, and foster preservation of computational methods that might otherwise be lost over time, thereby supporting research reproducibility and replicability. Many provide or are integrated with other services, including indexing and archival services, that can be leveraged by librarians, digital archivists, journal editors and publishers, and researchers alike.
Transparency of the processes under which registries and repositories operate helps build trust with their user communities ( Yakel et al., 2013 ; Frank et al., 2017 ). However, many domain research software resources have been developed independently, and thus policies amongst such resources are often heterogeneous and some may be omitted. Having specific policies in place ensures that users and administrators have reference documents to help define a shared understanding of the scope, practices, and rules that govern these resources.
Though recommendations and best practices for many aspects of science have been developed, no best practices existed that addressed the operations of software registries and repositories. To address this need, a Best Practices for Software Registries Task Force was proposed in June 2018 to the FORCE11 Software Citation Implementation Working Group (SCIWG) ( https://github.com/force11/force11-sciwg ). In seeking to improve the services software resources provide, software repository maintainers came together to learn from each other and promote interoperability. Both common practices and missing practices unfolded in these exchanges. These practices led to the development of nine best practices that set expectations for both users and maintainers of the resource by defining management of its contents and allowed usages as well as clarifying positions on sensitive issues such as attribution.
In this article, we expand on our pre-print “Nine Best Practices for Research Software Registries and Repositories: A Concise Guide” ( Task Force on Best Practices for Software Registries et al., 2020 ) to describe our best practices and their development. Our guidelines are actionable, have a general purpose, and reflect the discussion of a community of more than 30 experts who handle over 14 resources (registries or repositories) across different scientific domains. Each guideline provides a rationale, suggestions, and examples based on existing repositories or registries. To reduce repetition, we refer to registries and repositories collectively as “resources.”
The remainder of the article is structured as follows. We first describe background and related efforts in “Background”, followed by the methodology we used when structuring the discussion for creating the guidelines (Methodology). We then describe the nine best practices in “Best Practices for Repositories and Registries”, followed by a discussion (Discussion). “Conclusions” concludes the article by summarizing current efforts to continue the adoption of the proposed practices. Those who contributed to the development of this article are listed in Appendix A, and links to example policies are given in Appendix B. Appendix C provides updated information about resources that have participated in crafting the best practices and an overview of their main attributes.
In the last decade, much was written about a reproducibility crisis in science ( Baker, 2016 ) stemming in large part from the lack of training in programming skills and the unavailability of computational resources used in publications ( Merali, 2010 ; Peng, 2011 ; Morin et al., 2012 ). On these grounds, national and international governments have increased their interest in releasing artifacts of publicly-funded research to the public ( Office of Science & Technology Policy, 2016 ; Directorate-General for Research & Innovation (European Commission), 2018 ; Australian Research Council, 2018 ; Chen et al., 2019 ; Ministère de l’Enseignement supérieur, de la Recherche et de l’Innovation, 2021 ), and scientists have appealed to colleagues in their field to release software to improve research transparency ( Weiner et al., 2009 ; Barnes, 2010 ; Ince, Hatton & Graham-Cumming, 2012 ) and efficiency ( Grosbol & Tody, 2010 ). Open Science initiatives such as RDA and FORCE11 have emerged as a response to these calls for greater transparency and reproducibility. Journals introduced policies encouraging (or even requiring) that data and software be openly available to others ( Editorial Staff, 2019 ; Fox et al., 2021 ). New tools have been developed to facilitate depositing research data and software in a repository ( Baruch, 2007 ; CERN & OpenAIRE, 2013 ; Di Cosmo & Zacchiroli, 2017 ; Clyburne-Sherin, Fei & Green, 2019 ; Brinckman et al., 2019 ; Trisovic et al., 2020 ) and consequently, make them citable so authors and other contributors gain recognition and credit for their work ( Soito & Hwang, 2017 ; Du et al., 2021 ).
Support for disseminating research outputs has been proposed with FAIR and FAIR4RS principles that state shared digital artifacts, such as data and software, should be Findable, Accessible, Interoperable, and Reusable ( Wilkinson et al., 2016 ; Lamprecht et al., 2020 ; Katz, Gruenpeter & Honeyman, 2021 ; Chue Hong et al., 2021 ). Conforming with the FAIR principles for published software ( Lamprecht et al., 2020 ) requires facilitating its discoverability, preferably in domain-specific resources ( Jiménez et al., 2017 ). These resources should contain machine-readable metadata to improve the discoverability (Findable) and accessibility (Accessible) of research software through search engines or from within the resource itself. Furthering interoperability in FAIR is aided through the adoption of community standards e.g ., schema.org ( Guha, Brickley & Macbeth, 2016 ) or the ability to translate from one resource to another. The CodeMeta initiative ( Jones et al., 2017 ) achieves this translation by creating a “Rosetta Stone” which maps the metadata terms used by each resource to a common schema. The CodeMeta schema ( https://codemeta.github.io/ ) is an extension of schema.org which adds ten new fields to represent software-specific metadata. To date, CodeMeta has been adopted for representing software metadata by many repositories ( https://hal.inria.fr/hal-01897934v3/codemeta ).
As the usage of computational methods continues to grow, recommendations for improving research software have been proposed ( Stodden et al., 2016 ) in many areas of science and software, as can be seen by the series of “Ten Simple Rules” articles offered by PLOS ( Dashnow, Lonsdale & Bourne, 2014 ), sites such as AstroBetter ( https://www.astrobetter.com/ ), courses to improve skills such as those offered by The Carpentries ( https://carpentries.org/ ), and attempts to measure the adoption of recognized best practices ( Serban et al., 2020 ; Trisovic et al., 2022 ). Our quest for best practices complements these efforts by providing guides to the specific needs of research software registries and repositories.
Methodology
The best practices presented in this article were developed by an international Task Force of the FORCE11 Software Citation Implementation Working Group (SCIWG). The Task Force was proposed in June 2018 by author Alice Allen, with the goal of developing a list of best practices for software registries and repositories. Working Group members and a broader group of managers of domain specific software resources formed the inaugural group. The resulting Task Force members were primarily managers and editors of resources from Europe, United States, and Australia. Due to the range in time zones, the Task Force held two meetings 7 h apart, with the expectation that, except for the meeting chair, participants would attend one of the two meetings. We generally refer to two meetings on the same day with the singular “meeting” in the discussions to follow.
The inaugural Task Force meeting (February, 2019) was attended by 18 people representing 14 different resources. Participants introduced themselves and provided some basic information about their resources, including repository name, starting year, number of records, and scope (discipline-specific or general purpose), as well as services provided by each resource ( e.g ., support of software citation, software deposits, and DOI minting). Table 1 presents an overview of the collected responses, which highlight the efforts of the Task Force chairs to bring together both discipline-specific and general purpose resources. The “Other” category indicates that the answer needed clarifying text ( e.g ., for the question “is the repository actively curated?” some repositories are not manually curated, but have validation checks). Appendix C provides additional information on the questions asked to resource managers ( Table C.1 ) and their responses ( Tables C.2 – C.4 ).
During the inaugural Task Force meeting, the chair laid out the goal of the Task Force, and the group was invited to brainstorm to identify commonalities for building a list of best practices. Participants also shared challenges they had faced in running their resources and policies they had enacted to manage these resources. The result of the brainstorming and discussion was a list of ideas collected in a common document.
Starting in May 2019 and continuing through the rest of 2019, the Task Force met on the third Thursday of each month and followed an iterative process to discuss, add to, and group ideas; refine and clarify the ideas into different practices, and define the practices more precisely. It was clear from the onset that, though our resources have goals in common, they are also very diverse and would be best served by best practices that were descriptive rather than prescriptive. We reached consensus on whether a practice should be a best practice through discussion and informal voting. Each best practice was given a title and a list of questions or needs that it addressed.
Our initial plan aimed at holding two Task Force meetings on the same day each month, in order to follow a common agenda with independent discussions built upon the previous month’s meeting. However, the later meeting was often advantaged by the earlier discussion. For instance, if the early meeting developed a list of examples for one of the guidelines, the late meeting then refined and added to the list. Hence, discussions were only duplicated when needed, e.g ., where there was no consensus in the early group, and often proceeded in different directions according to the group’s expertise and interest. Though we had not anticipated this, we found that holding two meetings each month on the same day accelerated the work, as work done in the second meeting of the day generally continued rather than repeating work done in the first meeting.
The resulting consensus from the meetings produced a list of the most broadly applicable practices, which became the initial list of best practices participants drew from during a two-day workshop, funded by the Sloan Foundation and held at the University of Maryland College Park, in November, 2019 ( Scientific Software Registry Collaboration Workshop ). A goal of the workshop was to develop the final recommendations on best practices for repositories and registries to the FORCE11 SCIWG. The workshop included participants outside the Task Force resulting in a broader set of contributions to the final list. In 2020, this group made additional refinements to the best practices during virtual meetings and through online collaborative writing producing in the guidelines described in the next section. The Task Force then transitioned into the SciCodes consortium ( http://scicodes.net ). SciCodes is a permanent community for research software registries and repositories with a particular focus on these best practices. SciCodes continued to collect information about involved registries and repositories, which are listed in Appendix C. We also include some analysis of the number of entries and date of creation of member resources. Appendix A lists the people who participated in these efforts.
Best practices for repositories and registries
Our recommendations are provided as nine separate policies or statements, each presented below with an explanation as to why we recommend the practice, what the practice describes, and specific considerations to take into account. The last paragraph of each best practice includes one or two examples and a link to Appendix B, which contains many examples from different registries and repositories.
These nine best practices, though not an exhaustive list, are applicable to the varied resources represented in the Task Force, so are likely to be broadly applicable to other scientific software repositories and registries. We believe that adopting these practices will help document, guide, and preserve these resources, and put them in a stronger position to serve their disciplines, users, and communities 1 .
Provide a public scope statement
The landscape of research software is diverse and complex due to the overlap between scientific domains, the variety of technical properties and environments, and the additional considerations resulting from funding, authors’ affiliation, or intellectual property. A scope statement clarifies the type of software contained in the repository or indexed in the registry. Precisely defining a scope, therefore, helps those users of the resource who are looking for software to better understand the results they obtained.
Moreover, given that many of these resources accept submission of software packages, providing a precise and accessible definition will help researchers determine whether they should register or deposit software, and curators by making clear what is out of scope for the resource. Overall, a public scope manages the expectations of the potential depositor as well as the software seeker. It informs both what the resource does and does not contain.
The scope statement should describe:
- What is accepted, and acceptable, based on criteria covering scientific discipline, technical characteristics, and administrative properties
- What is not accepted, i.e. , characteristics that preclude their incorporation in the resource
- Notable exceptions to these rules, if any
Particular criteria of relevance include the scientific community being served and the types of software listed in the registry or stored in the repository, such as source code, compiled executables, or software containers. The scope statement may also include criteria that must be satisfied by accepted software, such as whether certain software quality metrics must be fulfilled or whether a software project must be used in published research. Availability criteria can be considered, such as whether the code has to be publicly available, be in the public domain and/or have a license from a predefined set, or whether software registered in another registry or repository will be accepted.
An illustrating example of such a scope statement is the editorial policy ( https://ascl.net/wordpress/submissions/editiorial-policy/ ) published by the Astrophysics Source Code Library (ASCL) ( Allen et al., 2013 ), which states that it includes only software source code used in published astronomy and astrophysics research articles, and specifically excludes software available only as a binary or web service. Though the ASCL’s focus is on research documented in peer-reviewed journals, its policy also explicitly states that it accepts source code used in successful theses. Other examples of scope statements can be found in Appendix B.
Provide guidance for users
Users accessing a resource to search for entries and browse or retrieve the description(s) of one or more software entries have to understand how to perform such actions. Although this guideline potentially applies to many public online resources, especially research databases, the potential complexity of the stored metadata and the curation mechanisms can seriously impede the understandability and usage of software registries and repositories.
User guidance material may include:
- How to perform common user tasks, such as searching the resource, or accessing the details of an entry
- Answers to questions that are often asked or can be anticipated, e.g ., with Frequently Asked Questions or tips and tricks pages
- Who to contact for questions or help
A separate section in these guidelines on the Conditions of use policy covers terms of use of the resource and how best to cite records in a resource and the resource itself.
Guidance for users who wish to contribute software is covered in the next section, Provide guidance to software contributors .
When writing guidelines for users, it is advisable to identify the types of users your resource has or could potentially have and corresponding use cases. Guidance itself should be offered in multiple forms, such as in-field prompts, linked explanations, and completed examples. Any machine-readable access, such as an API, should be fully described directly in the interface or by providing a pointer to existing documentation, and should specify which formats are supported ( e.g ., JSON-LD, XML) through content negotiation if it is enabled.
Examples of such elements include, for instance, the bio.tools registry ( Ison et al., 2019 ) API user guide ( https://biotools.readthedocs.io/en/latest/api_usage_guide.html ), or the ORNL DAAC ( ORNL, 2013 ) instructions for data providers ( https://daac.ornl.gov/submit/ ). Additional examples of user guidance can be found in Appendix B.
Provide guidance to software contributors
Most software registries and repositories rely on a community model, whereby external contributors will provide software entries to the resource. The scope statement will already have explained what is accepted and what is not; the contributor policy addresses who can add or change software entries and the processes involved.
The contributor policy should therefore describe:
- Who can or cannot submit entries and/or metadata
- Required and optional metadata expected for deposited software
- Review process, if any
- Curation process, if any
- Procedures for updates ( e.g ., who can do it, when it is done, how is it done)
Topics to consider when writing a contributor policy include whether the author(s) of a software entry will be contacted if the contributor is not also an author and whether contact is a condition or side-effect of the submission. Additionally, a contributor policy should specify how persistent identifiers are assigned (if used) and should state that depositors must comply with all applicable laws and not be intentionally malicious.
Such material is provided in resources such as the Computational Infrastructure for Geodynamics ( Hwang & Kellogg, 2017 ) software contribution checklist ( https://github.com/geodynamics/best_practices/blob/master/ContributingChecklist.md#contributing-software ) and the CoMSES Net Computational Model Library ( Janssen et al., 2008 ) model archival tutorial ( https://forum.comses.net/t/archiving-your-model-1-gettingstarted/7377 ). Additional examples of guidance for software contributors can be found in Appendix B.
Establish an authorship policy
Because research software is often a research product, it is important to report authorship accurately, as it allows for proper scholarly credit and other types of attributions ( Smith, Katz & Niemeyer, 2016 ). However, even though authorship should be defined at the level of a given project, it can prove complicated to determine ( Alliez et al., 2019 ). Roles in software development can widely vary as contributors change with time and versions, and contributions are difficult to gauge beyond the “commit,” giving rise to complex situations. In this context, establishing a dedicated policy ensures that people are given due credit for their work. The policy also serves as a document that administrators can turn to in case disputes arise and allows proactive problem mitigation, rather than having to resort to reactive interpretation. Furthermore, having an authorship policy mirrors similar policies by journals and publishers and thus is part of a larger trend. Note that the authorship policy will be communicated at least partially to users through guidance provided to software contributors. Resource maintainers should ensure this policy remains consistent with the citation policies for the registry or repository (usually, the citation requirements for each piece of research software are under the authority of its owners).
The authorship policy should specify:
- How authorship is determined e.g ., a stated criteria by the contributors and/or the resource
- Policies around making changes to authorship
- The conflict resolution processes adopted to handle authorship disputes
When defining an authorship policy, resource maintainers should take into consideration whether those who are not coders, such as software testers or documentation maintainers, will be identified or credited as authors, as well as criteria for ordering the list of authors in cases of multiple authors, and how the resource handles large numbers of authors and group or consortium authorship. Resources may also include guidelines about how changes to authorship will be handled so each author receives proper credit for their contribution. Guidelines can help facilitate determining every contributors’ role. In particular, the use of a credit vocabulary, such as the Contributor Roles Taxonomy ( Allen, O’Connell & Kiermer, 2019 ), to describe authors’ contributions should be considered for this purpose ( http://credit.niso.org/ ).
An example of authorship policy is provided in the Ethics Guidelines ( https://joss.theoj.org/about#ethics ) and the submission guide authorship section ( https://joss.readthedocs.io/en/latest/submitting.html#authorship ) of the Journal of Open Source Software ( Katz, Niemeyer & Smith, 2018 ), which provides rules for inclusion in the authors list. Additional examples of authorship policies can be found in Appendix B.
Document and share your metadata schema
The structure and semantics of the information stored in registries and repositories is sometimes complex, which can hinder the clarity, discovery, and reuse of the entries included in these resources. Publicly posting the metadata schema used for the entries helps individual and organizational users interested in a resource’s information understand the structure and properties of the deposited information. The metadata structure helps to inform users how to interact with or ingest records in the resource. A metadata schema mapped to other schemas and an API specification can improve the interoperability between registries and repositories.
This practice should specify:
- The schema used and its version number. If a standard or community schema, such as CodeMeta ( Jones et al., 2017 ) or schema.org ( Guha, Brickley & Macbeth, 2016 ) is used, the resource should reference its documentation or official website. If a custom schema is used, formal documentation such as a description of the schema and/or a data dictionary should be provided.
- Expected metadata when submitting software, including which fields are required and which are optional, and the format of the content in each field.
To improve the readability of the metadata schema and facilitate its translation to other standards, resources may provide a mapping (from the metadata schema used in the resource) to published standard schemas, through the form of a “cross-walk” ( e.g ., the CodeMeta cross-walk ( https://codemeta.github.io/crosswalk/ )) and include an example entry from the repository that illustrates all the fields of the metadata schema. For instance, extensive documentation ( https://biotoolsschema.readthedocs.io/en/latest/ ) is available for the biotoolsSchema ( Ison et al., 2021 ) format, which is used in the bio.tools registry. Another example is the OntoSoft vocabulary ( http://ontosoft.org/software ), used by the OntoSoft registry ( Gil, Ratnakar & Garijo, 2015 ; Gil et al., 2016 ) and available in both machine-readable and human readable formats. Additional examples of metadata schemas can be found in Appendix B.
Stipulate conditions of use
The conditions of use document the terms under which users may use the contents provided by a website. In the case of software registries and repositories, these conditions should specifically state how the metadata regarding the entities of a resource can be used, attributed, and/or cited, and provide information about the licenses used for the code and binaries. This policy can forestall potential liabilities and difficulties that may arise, such as claims of damage for misinterpretation or misapplication of metadata. In addition, the conditions of use should clearly state how the metadata can and cannot be used, including for commercial purposes and in aggregate form.
This document should include:
- Legal disclaimers about the responsibility and liability borne by the registry or repository
- License and copyright information, both for individual entries and for the registry or repository as a whole
- Conditions for the use of the metadata, including prohibitions, if any
- Preferred format for citing software entries
- Preferred format for attributing or citing the resource itself
When writing conditions of use, resource maintainers might consider what license governs the metadata, if licensing requirements apply for findings and/or derivatives of the resource, and whether there are differences in the terms and license for commercial vs noncommercial use. Restrictions on the use of the metadata may also be included, as well as a statement to the effect that the registry or repository makes no guarantees about completeness and is not liable for any damages that could arise from the use of the information. Technical restrictions, such as conditions of use of the API (if one is available), may also be mentioned.
Conditions of use can be found for instance for DOE CODE ( Ensor et al., 2017 ), which in addition to the general conditions of use ( https://www.osti.gov/disclaim ) specifies that the rules for usage of the hosted code ( https://www.osti.gov/doecode/faq#are-there-restrictions ) are defined by their respective licenses. Additional examples of conditions of use policies can be found in Appendix B.
State a privacy policy
Privacy policies define how personal data about users are stored, processed, exchanged or removed. Having a privacy policy demonstrates a strong commitment to the privacy of users of the registry or repository and allows the resource to comply with the legal requirement of many countries in addition to those a home institution and/or funding agencies may impose.
The privacy policy of a resource should describe:
- What information is collected and how long it is retained
- How the information, especially any personal data, is used
- Whether tracking is done, what is tracked, and how ( e.g ., Google Analytics)
- Whether cookies are used
When writing a privacy policy, the specific personal data which are collected should be detailed, as well as the justification for their resource, and whether these data are sold and shared. Additionally, one should list explicitly the third-party tools used to collect analytic information and potentially reference their privacy policies. If users can receive emails as a result of visiting or downloading content, such potential solicitations or notifications should be announced. Measures taken to protect users’ privacy and whether the resource complies with the European Union Directive on General Data Protection Regulation ( https://gdpr-info.eu/ ) (GDPR) or other local laws, if applicable, should be explained 2 . As a precaution, the statement can reserve the right to make changes to this privacy policy. Finally, a mechanism by which users can request the removal of such information should be described.
For example, the SciCrunch’s ( Grethe et al., 2014 ) privacy policy ( https://scicrunch.org/page/privacy ) details what kind of personal information is collected, how it is collected, and how it may be reused, including by third-party websites through the use of cookies. Additional examples of privacy policies can be found in Appendix B.
Provide a retention policy
Many software registries and repositories aim to facilitate the discovery and accessibility of the objects they describe, e.g ., enabling search and citation, by making the corresponding records permanently accessible. However, for various reasons, even in such cases maintainers and curators may have to remove records. Common examples include removing entries that are outdated, no longer meet the scope of the registry, or are found to be in violation of policies. The resource should therefore document retention goals and procedures so that users and depositors are aware of them.
The retention policy should describe:
- The length of time metadata and/or files are expected to be retained;
- Under what conditions metadata and/or files are removed;
- Who has the responsibility and ability to remove information;
- Procedures to request that metadata and/or files be removed.
The policy should take into account whether best practices for persistent identifiers are followed, including resolvability, retention, and non-reuse of those identifiers. The retention time provided by the resource should not be too prescriptive ( e.g ., “for the next 10 years”), but rather it should fit within the context of the underlying organization(s) and its funding. This policy should also state who is allowed to edit metadata, delete records, or delete files, and how these changes are performed to preserve the broader consistency of the registry. Finally, the process by which data may be taken offline and archived as well as the process for its possible retrieval should be thoroughly documented.
As an example, Bioconductor ( Gentleman et al., 2004 ) has a deprecation process through which software packages are removed if they cannot be successfully built or tested, or upon specific request from the package maintainer. Their policy ( https://bioconductor.org/developers/package-end-of-life/ ) specifies who initiates this process and under which circumstances, as well as the successive steps that lead to the removal of the package. Additional examples of retention policies can be found in Appendix B.
Disclose your end-of-life policy
Despite their usefulness, the long-term maintenance, sustainability, and persistence of online scientific resources remains a challenge, and published web services or databases can disappear after a few years ( Veretnik, Fink & Bourne, 2008 ; Kern, Fehlmann & Keller, 2020 ). Sharing a clear end-of-life policy increases trust in the community served by a registry or repository. It demonstrates a thoughtful commitment to users by informing them that provisions for the resource have been considered should the resource close or otherwise end its services for its described artifacts. Such a policy sets expectations and provides reassurance as to how long the records within the registry will be findable and accessible in the future.
This policy should describe:
- Under what circumstances the resource might end its services;
- What consequences would result from closure;
- What will happen to the metadata and/or the software artifacts contained in the resource in the event of closure;
- If long-term preservation is expected, where metadata and/or software artifacts will be migrated for preservation;
- How a migration will be funded.
Publishing an end-of-life policy is an opportunity to consider, in the event a resource is closed, whether the records will remain available, and if so, how and for whom, and under which conditions, such as archived status or “read-only.” The restrictions applicable to this policy, if any, should be considered and detailed. Establishing a formal agreement or memorandum of understanding with another registry, repository, or institution to receive and preserve the data or project, if applicable, might help to prepare for such a liability.
Examples of such policies include the Zenodo end-of-life policy ( https://help.zenodo.org/ ), which states that if Zenodo ceases its services, the data hosted in the resource will be migrated and the DOIs provided would be updated to resolve to the new location (currently unspecified). Additional examples of end-of-life policies can be found in Appendix B.
A summary of the practices presented in this section can be found in Table 2 .
The best practices described above serve as a guide for repositories and registries to provide better service to their users, ranging from software developers and researchers to publishers and search engines, and enable greater transparency about the operation of their described resources. Implementing our practices provides users with significant information about how different resources operate, while preserving important institutional knowledge, standardizing expectations, and guiding user interactions.
For instance, a public scope statement and guidance for users may directly impact usability and, thus, the popularity of the repository. Resources including tools with a simple design and unambiguous commands, as well as infographic guides or video tutorials, ease the learning curve for new users. The guidance for software contributions, conditions of use, and sharing the metadata schema used may help eager users contribute new functionality or tools, which may also help in creating a community around a resource. A privacy policy has become a requirement across geographic boundaries and legal jurisdictions. An authorship policy is critical in facilitating collaborative work among researchers and minimizing the chances for disputes. Finally, retention and end-of-life policies increase the trust and integrity of a repository service.
Policies affecting a single community or domain were deliberately omitted when developing the best practices. First, an exhaustive list would have been a barrier to adoption and not applicable to every repository since each has a different perspective, audience, and motivation that drives policy development for their organization. Second, best practices that regulate the content of a resource are typically domain-specific to the artifact and left to resources to stipulate based on their needs. Participants in the 2019 Scientific Software Registry Collaboration Workshop were surprised to find that only four metadata elements were shared by all represented resources 3 . The diversity of our resources precludes prescriptive requirements, such as requiring specific metadata for records, so these were also deliberately omitted in the proposed best practices.
Hence, we focused on broadly applicable practices considered important by various resources. For example, amongst the participating registries and repositories, very few had codes of conduct that govern the behavior of community members. Codes of conduct are warranted if resources are run as part of a community, especially if comments and reviews are solicited for deposits. In contrast, a code of conduct would be less useful for resources whose primary purpose is to make software and software metadata available for reuse. However, this does not negate their importance and their inclusion as best practices in other arenas concerning software.
As noted by the FAIR4RS movement, software is different than data, motivating the need for a separate effort to address software resources ( Lamprecht et al., 2020 ; Katz et al., 2016 ). Even so, there are some similarities, and our effort complements and aligns well with recent guidelines developed in parallel to increase the transparency, responsibility, user focus, sustainability, and technology of data repositories. For example, both the TRUST Principles ( Lin et al., 2020 ) and CoreTrustSeal Requirements ( CoreTrustSeal, 2019 ) call for a repository to provide information on its scope and list the terms of use of its metadata to be considered compliant with TRUST or CoreTrustSeal, which aligns with our practices “ Provide a public scope statement ” and “ Stipulate conditions of use ”. CoreTrustSeal and TRUST also require that a repository consider continuity of access, which we have expressed as the practice to “ Disclosing your end-of-life policy ”. Our best practices differ in that they do not address, for example, staffing needs nor professional development for staff, as CoreTrustSeal requires, nor do our practices address protections against cyber or physical security threats, as the TRUST principles suggest. Inward-facing policies, such as documenting internal workflows and practices, are generally good in reducing operational risks, but internal management practices were considered out of scope of our guidelines.
Figure 1 shows the number of resources that support (partially or in their totality) each best practice. Though we see the proposed best practices as critical, many of the repositories that have actively participated in the discussions (14 resources in total) have yet to implement every one of them. We have observed that the first three practices (providing public scope statement, add guidance for users and for software contributors) have the widest adoption, while the retention, end-of-life, and authorship policy the least. Understanding the lag in the implementation across all of the best practices requires further engagement with the community.

Improving the adoption of our guidelines is one of the goals of SciCodes ( http://scicodes.net ), a recent consortium of scientific software registries and repositories. SciCodes evolved from the Task Force as a permanent community to continue the dialogue and share information between domains, including sharing of tools and ideas. SciCodes has also prioritized improving software citation (complementary to the efforts of the FORCE11 SCIWG) and tracking the impact of metadata and interoperability. In addition, SciCodes aims to understand barriers to implementing policies, ensure consistency between various best practices, and continue advocacy for software support by continuing dialogue between registries, repositories, researchers, and other stakeholders.
Conclusions
The dissemination and preservation of research material, where repositories and registries play a key role, lies at the heart of scientific advancement. This article introduces nine best practices for research software registries and repositories. The practices are an outcome of a Task Force of the FORCE11 Software Citation Implementation Working Group and reflect the discussion, collaborative experiences, and consensus of over 30 experts and 14 resources.
The best practices are non-prescriptive, broadly applicable, and include examples and guidelines for their adoption by a community. They specify establishing the working domain (scope) and guidance for both users and software contributors, address legal concerns with privacy, use, and authorship policies, enhance usability by encouraging metadata sharing, and set expectations with retention and end-of-life policies. However, we believe additional work is needed to raise awareness and adoption across resources from different scientific disciplines. Through the SciCodes consortium, our goal is to continue implementing these practices more uniformly in our own registries and repositories and reduce the burdens of adoption. In addition to completing the adoption of these best practices, SciCodes will address topics such as tracking the impact of good metadata, improving interoperability between registries, and making our metadata discoverable by search engines and services such as Google Scholar, ORCID, and discipline indexers.
APPENDIX A: CONTRIBUTORS
The following people contributed to the development of this article through participation in the Best Practices Task Force meetings, 2019 Scientific Software Registry Collaboration Workshop, and/or SciCodes Consortium meetings:
Alain Monteil , Inria, HAL ; Software Heritage
Alejandra Gonzalez-Beltran , Science and Technology Facilities Council, UK Research and Innovation, Science and Technology Facilities Council
Alexandros Ioannidis , CERN, Zenodo
Alice Allen , University of Maryland, College Park, Astrophysics Source Code Library
Allen Lee , Arizona State University, CoMSES Net Computational Model Library
Ana Trisovic , Harvard University, DataVerse
Anita Bandrowski , UCSD, SciCrunch
Bruce E. Wilson , Oak Ridge National Laboratory, ORNL Distributed Active Archive Center for Biogeochemical Dynamics
Bryce Mecum , NCEAS, UC Santa Barbara, CodeMeta
Caifan Du , iSchool, University of Texas at Austin, CiteAs
Carly Robinson , US Department of Energy, Office of Scientific and Technical Information, DOE CODE
Daniel Garijo , Universidad Politécnica de Madrid (formerly at Information Sciences Institute, University of Southern California), Ontosoft
Daniel S. Katz , University of Illinois at Urbana-Champaign, Associate EiC for JOSS, FORCE11 Software Citation Implementation Working Group , co-chair
David Long , Brigham Young University, IEEE GRS Remote Sensing Code Library
Genevieve Milliken , NYU Bobst Library, IASGE
Hervé Ménager , Hub de Bioinformatique et Biostatistique—Département Biologie Computationnelle, Institut Pasteur, ELIXIR bio.tools
Jessica Hausman , Jet Propulsion Laboratory, PO.DAAC
Jurriaan H. Spaaks , Netherlands eScience Center, Research Software Directory
Katrina Fenlon , University of Maryland, iSchool
Kristin Vanderbilt , Environmental Data Initiative, IMCR
Lorraine Hwang , University California Davis, Computational Infrastructure for Geodynamics
Lynn Davis , US Department of Energy, Office of Scientific and Technical Information, DOE CODE
Martin Fenner , Front Matter (formerly at DataCite), FORCE11 Software Citation Implementation Working Group , co-chair
Michael R. Crusoe , CWL, Debian-Med
Michael Hucka , California Institute of Technology, SBML ; COMBINE
Mingfang Wu , Australian Research Data Commons, Australian Research Data Commons
Morane Gruenpeter , Inria, Software Heritage
Moritz Schubotz , FIZ Karlsruhe - Leibniz-Institute for Information Infrastructure, swMATH
Neil Chue Hong , Software Sustainability Institute/University of Edinburgh, Software Sustainability Institute ; FORCE11 Software Citation Implementation Working Group , co-chair
Pete Meyer , Harvard Medical School, SBGrid ; BioGrids
Peter Teuben , University of Maryland, College Park, Astrophysics Source Code Library
Piotr Sliz , Harvard Medical School, SBGrid ; BioGrids
Sara Studwell , US Department of Energy, Office of Scientific and Technical Information, DOE CODE
Shelley Stall , American Geophysical Union, AGU Data Services
Stephan Druskat , German Aerospace Center (DLR)/University Jena/Humboldt-Universität zu Berlin, Citation File Format
Ted Carnevale, Neuroscience Department, Yale University, ModelDB
Tom Morrell , Caltech Library, CaltechDATA
Tom Pollard , MIT/PhysioNet, PhysioNet
APPENDIX B: POLICY EXAMPLES
Scope statement.
- • Astrophysics Source Code Library. (n.d.). Editorial policy .
- https://ascl.net/wordpress/submissions/editiorial-policy/
- • bio.tools. (n.d.). Curators Guide .
- https://biotools.readthedocs.io/en/latest/curators_guide.html
- • Caltech Library. (2017). Terms of Deposit .
- https://data.caltech.edu/terms
- • Caltech Library. (2019). CaltechDATA FAQ .
- https://www.library.caltech.edu/caltechdata/faq
- • Computational Infrastructure for Geodynamics. (n.d.). Code Donation .
- https://geodynamics.org/cig/dev/code-donation/
- • CoMSES Net Computational Model Library. (n.d.). Frequently Asked Questions .
- https://www.comses.net/about/faq/#model-library
- • ORNL DAAC for Biogeochemical Dynamics. (n.d.). Data Scope and Acceptance Policy .
- https://daac.ornl.gov/submit/
- • RDA Registry and Research Data Australia. (2018). Collection . ARDC Intranet.
- https://intranet.ands.org.au/display/DOC/Collection
- • Remote Sensing Code Library. (n.d.). Submit .
- https://rscl-grss.org/submit.php
- • SciCrunch. (n.d.). Curation Guide for SciCrunch Registry .
- https://scicrunch.org/page/Curation%20Guidelines
- • U.S. Department of Energy: Office of Scientific and Technical Information. (n.d.-a). DOE CODE: Software Policy . https://www.osti.gov/doecode/policy
- • U.S. Department of Energy: Office of Scientific and Technical Information. (n.d.-b). FAQs . OSTI.GOV.
- https://www.osti.gov/faqs
Guidance for users
- • Astrophysics Source Code Library. (2021). Q & A
- https://ascl.net/home/getwp/898
- • bio.tools. (2021). API Reference
- https://biotools.readthedocs.io/en/latest/api_reference.html
- • Harvard Dataverse. (n.d.). Curation and Data Management Services
- https://support.dataverse.harvard.edu/curation-services
- • OntoSoft. (n.d.). An Intelligent Assistant for Software Publication
- https://ontosoft.org/users.html
- • ORNL DAAC for Biogeochemical Dynamics. (n.d.). Learning
- https://daac.ornl.gov/resources/learning/
- • U.S. Department of Energy: Office of Scientific and Technical Information. (n.d.). FAQs . OSTI.GOV.
- https://www.osti.gov/doecode/faq
Guidance for software contributors
- • Astrophysics Source Code Library. (n.d.) Submit a code .
- https://ascl.net/code/submit
- • bio.tools. (n.d.) Quick Start Guide
- https://biotools.readthedocs.io/en/latest/quickstart_guide.html
- • Computational Infrastructure for Geodynamics. Contributing Software
- https://geodynamics.org/cig/dev/code-donation/checklist/
- • CoMSES Net Computational Model Library (2019) Archiving your model: 1. Getting Started
- https://forum.comses.net/t/archiving-your-model-1-getting-started/7377
- • Harvard Dataverse. (n.d.) For Journals .
- https://support.dataverse.harvard.edu/journals
- • Committee on Publication Ethics: COPE. (2020a). Authorship and contributorship .
- https://publicationethics.org/authorship
- • Committee on Publication Ethics: COPE. (2020b). Core practices .
- https://publicationethics.org/core-practices
- • Dagstuhl EAS Specification Draft. (2016). The Software Credit Ontology .
- https://dagstuhleas.github.io/SoftwareCreditRoles/doc/index-en.html#
- • Journal of Open Source Software. (n.d.). Ethics Guidelines .
- https://joss.theoj.org/about#ethics
- • ORNL DAAC (n.d) Authorship Policy .
- • PeerJ Journals. (n.d.-a). Author Policies .
- https://peerj.com/about/policies-and-procedures/#author-policies
- • PeerJ Journals. (n.d.-b). Publication Ethics .
- https://peerj.com/about/policies-and-procedures/#publication-ethics
- • PLOS ONE. (n.d.). Authorship .
- https://journals.plos.org/plosone/s/authorship
- • National Center for Data to Health. (2019). The Contributor Role Ontology.
- https://github.com/data2health/contributor-role-ontology
Metadata schema
- • ANDS: Australian National Data Service. (n.d.). Metadata . ANDS.
- https://www.ands.org.au/working-with-data/metadata
- • ANDS: Australian National Data Service. (2016). ANDS Guide: Metadata .
- https://www.ands.org.au/data/assets/pdf_file/0004/728041/Metadata-Workinglevel.pdf
- • Bernal, I. (2019). Metadata for Data Repositories .
- https://doi.org/10.5281/zenodo.3233486
- • bio.tools. (2020). Bio-tools/biotoolsSchema [HTML].
- https://github.com/bio-tools/biotoolsSchema (Original work published 2015)
- • bio.tools. (2019). BiotoolsSchema documentation .
- https://biotoolsschema.readthedocs.io/en/latest/
- • The CodeMeta crosswalks. (n.d.)
- https://codemeta.github.io/crosswalk/
- • Citation File Format (CFF). (n.d.)
- https://doi.org/10.5281/zenodo.1003149
- • The DataVerse Project. (2020). DataVerse 4.0+ Metadata Crosswalk.
- https://docs.google.com/spreadsheets/d/10Luzti7svVTVKTA-px27oq3RxCUM-QbiTkm8iMd5C54
- • OntoSoft. (2015). OntoSoft Ontology .
- https://ontosoft.org/ontology/software/
- • Zenodo. (n.d.-a). Schema for Depositing .
- https://zenodo.org/schemas/records/record-v1.0.0.json
- • Zenodo. (n.d.-b). Schema for Published Record .
- https://zenodo.org/schemas/deposits/records/legacyrecord.json
Conditions of use policy
- • Allen Institute. (n.d.). Terms of Use .
- https://alleninstitute.org/legal/terms-use/
- • Europeana. (n.d.). Usage Guidelines for Metadata . Europeana Collections.
- https://www.europeana.eu/portal/en/rights/metadata.html
- • U.S. Department of Energy: Office of Scientific and Technical Information. (n.d.). DOE CODE FAQ: Are there restrictions on the use of the material in DOE CODE?
- https://www.osti.gov/doecode/faq#are-there-restrictions
- • Zenodo. (n.d.). Terms of Use .
- https://about.zenodo.org/terms/
Privacy policy
- • Allen Institute. (n.d.). Privacy Policy .
- https://alleninstitute.org/legal/privacy-policy/
- • CoMSES Net. (n.d.). Data Privacy Policy .
- https://www.comses.net/about/data-privacy/
- • Nature. (2020). Privacy Policy .
- https://www.nature.com/info/privacy
- • Research Data Australia. (n.d.). Privacy Policy .
- https://researchdata.ands.org.au/page/privacy
- • SciCrunch. (2018). Privacy Policy . SciCrunch.
- https://scicrunch.org/page/privacy
- • Science Repository. (n.d.). Privacy Policies .
- https://www.sciencerepository.org/privacy
- • Zenodo. (n.d.). Privacy policy .
- https://about.zenodo.org/privacy-policy/
Retention policy
- • Bioconductor. (2020). Package End of Life Policy .
- https://bioconductor.org/developers/package-end-of-life/
- • Caltech Library. (n.d.). CaltechDATA FAQ .
- • CoMSES Net Computational Model Library. (n.d.). How long will models be stored in the Computational Model Library?
- https://www.comses.net/about/faq/
- • Dryad. (2020). Dryad FAQ - Publish and Preserve your Data .
- https://datadryad.org/stash/faq#preserved
- • Software Heritage. (n.d.). Content policy .
- https://www.softwareheritage.org/legal/content-policy/
- • Zenodo. (n.d.). General Policies v1.0 .
- https://about.zenodo.org/policies/
End-of-life policy
- • Figshare. (n.d.). Preservation and Continuity of Access Policy .
- https://knowledge.figshare.com/articles/item/preservation-and-continuity-of-access-policy
- • Open Science Framework. (2019). FAQs . OSF Guides.
- http://help.osf.io/hc/en-us/articles/360019737894-FAQs
- • NASA Earth Science Data Preservation Content Specification (n.d.)
- https://earthdata.nasa.gov/esdis/eso/standards-and-references/preservation-content-spec
- • Zenodo. (n.d.). Frequently Asked Questions .
- https://help.zenodo.org/
APPENDIX C: RESOURCE INFORMATION
Since the first Task Force meeting was held in 2019, we have asked new resource representatives joining our community to provide the information shown in Table C.1 . Thanks to this effort, the group has been able to learn about each resource, identify similarities and differences, and thus better inform our meeting discussions.
Tables C.2 – C.4 provide an updated overview of the main features of all resources currently involved in the discussion and implementation of the best practices (30 resources in total as of December, 2021). Participating resources are diverse, and belong to a variety of discipline-specific ( e.g. , neurosciences, biology, geosciences, etc .) and domain generic repositories. Curated resources tend to have a lower number of software entries. Most resources have been created in the last 20 years, with the oldest resource dating from 1991. Most resources accept a software deposit, support DOIs to identify their entries, are actively curated, and can be used to cite software.
Acknowledgments
The best practices presented here were proposed and developed by a Task Force of the FORCE11 Software Citation Implementation Working Group. The following authors, randomly ordered, contributed equally to discussion, conceptualization, writing, reviewing, and editing this article: Daniel Garijo, Lorraine Hwang, Hervé Ménager, Alice Allen, Michael Hucka, Thomas Morrell, and Ana Trisovic.
Task Force on Best Practices for Software Registries participants : Alain Monteil, Alejandra Gonzalez-Beltran, Alexandros Ioannidis, Alice Allen, Allen Lee, Andre Jackson, Bryce Mecum,Caifan Du, Carly Robinson, Daniel Garijo, Daniel Katz, Genevieve Milliken, Hervé Ménager, Jurriaan Spaaks, Katrina Fenlon, Kristin Vanderbilt, Lorraine Hwang, Michael Hucka, Neil Chue Hong, P. Wesley Ryan, Peter Teuben, Shelley Stall, Stephan Druskat, Ted Carnevale, Thomas Morrell.
SciCodes Consortium participants : Alain Monteil, Alejandra Gonzalez-Beltran, Alexandros Ioannidis, Alice Allen, Allen Lee, Ana Trisovic, Anita Bandrowski, Bruce Wilson, Bryce Mecum, Carly Robinson, Celine Sarr, Colin Smith, Daniel Garijo, David Long, Harry Bhadeshia, Hervé Mé nager, Jeanette M. Sperhac, Joy Ku, Jurriaan Spaaks, Kristin Vanderbilt, Lorraine Hwang, Matt Jones, Mercé Crosas, Michael R. Crusoe, Mike Hucka, Ming Fang Wu, Morane Gruenpeter, Moritz Schubotz, Olaf Teschke, Pete Meyer, Peter Teuben, Piotr Sliz, Sara Studwell, Shelley Stall, Ted Carnevale, Tom Morrell, Tom Pollard, Wolfram Sperber.
Funding Statement
This work was supported by the Alfred P. Sloan Foundation (Grant Number G-2019-12446), and the Heidelberg Institute of Theoretical Studies. Ana Trisovic is funded by the Alfred P. Sloan Foundation (Grant Number P-2020-13988). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Additional Information and Declarations
The authors declare that they have no competing interests.
Daniel Garijo conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
Hervé Ménager conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
Lorraine Hwang conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
Ana Trisovic conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
Michael Hucka conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
Thomas Morrell conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
Alice Allen conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the article, and approved the final draft.
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
Open Data is a strategy for incorporating research data into the permanent scientific record by releasing it under an Open Access license. Whether data is deposited in a purpose-built repository or published as Supporting Information alongside a research article, Open Data practices ensure that data remains accessible and discoverable. For verification, replication, reuse, and enhanced understanding of research.
Benefits of Open Data
Readers rely on raw scientific data to enhance their understanding of published research, for purposes of verification, replication and reanalysis, and to inform future investigations.
Ensure reproducibility Proactively sharing data ensures that your work remains reproducible over the long term.
Inspire trust Sharing data demonstrates rigor and signals to the community that the work has integrity.
Receive credit Making data public opens opportunities to get academic credit for collecting and curating data during the research process.
Make a contribution Access to data accelerates progress. According to the 2019 State of Open Data report, more than 70% of researchers use open datasets to inform their future research.
Preserve the scientific record Posting datasets in a repository or uploading them as Supporting Information prevents data loss.
Why do researchers choose to make their data public?
Watch the short video that explores the top benefits of data sharing, what types of research data you should share, and how you can get it ready to help ensure more impact for your research.
PLOS Open Data policy
Publishing in a PLOS journal carries with it a commitment to make the data underlying the conclusions in your research article publicly available upon publication.
Our data policy underscores the rigor of the research we publish, and gives readers a fuller understanding of each study.
Read more about Open Data
Data sharing has long been a hallmark of high-quality reproducible research. Now, Open Data is becoming...
For PLOS, increasing data-sharing rates—and especially increasing the amount of data shared in a repository—is a high priority.
Ensure that you’re publication-ready and ensure future reproducibility through good data management How you store your data matters. Even after…
Data repositories
All methods of data sharing data facilitate reproduction, improve trust in science, ensure appropriate credit, and prevent data loss. When you choose to deposit your data in a repository, those benefits are magnified and extended.
Data posted in a repository is…
…more discoverable.
Detailed metadata and bidirectional linking to and from related articles help to make data in public repositories easily findable.
…more reusable
Machine-readable data formatting allows research in a repository to be incorporated into future systematic reviews or meta analyses more easily.
…easier to cite
Repositories assign data its own unique DOI, distinct from that of related research articles, so datasets can accumulate citations in their own right, illustrating the importance and lasting relevance of the data itself.
…more likely to earn citations
A 2020 study of more than 500,000 published research articles found articles that link to data in a public repository were likely to have a 25% higher citation rate on average than articles where data is available on request or as Supporting Information.
Open Data is more discoverable and accessible than ever
Deposit your data in a repository and earn an accessible data icon.

You already know depositing research data in a repository yields benefits like improved reproducibility, discoverability, and more attention and citations for your research.
PLOS helps to magnify these benefits even further with our Accessible Data icon. When you link to select, popular data repositories, your article earns an eye-catching graphic with a link to the associated dataset, so it’s more visible to readers.
Participating data repositories include:
- Open Science Framework (OSF)
- Gene Expression Omnibus
- NCBI Bioproject
- NCBI Sequence Read Archive
- Demographic and Health Surveys
We aim to add more repositories to the list in future. Read more
The PLOS Open Science Toolbox
The future is open
The PLOS Open Science Toolbox is your source for sci-comm tips and best-practice. Learn practical strategies and hands-on tips to improve reproducibility, increase trust, and maximize the impact of your research through Open Science.
Sign up to have new issues delivered to your inbox every week.
Learn more about the benefits of Open Science. Open Science

Explore millions of high-quality primary sources and images from around the world, including artworks, maps, photographs, and more.
Explore migration issues through a variety of media types
- Part of The Streets are Talking: Public Forms of Creative Expression from Around the World
- Part of The Journal of Economic Perspectives, Vol. 34, No. 1 (Winter 2020)
- Part of Cato Institute (Aug. 3, 2021)
- Part of University of California Press
- Part of Open: Smithsonian National Museum of African American History & Culture
- Part of Indiana Journal of Global Legal Studies, Vol. 19, No. 1 (Winter 2012)
- Part of R Street Institute (Nov. 1, 2020)
- Part of Leuven University Press
- Part of UN Secretary-General Papers: Ban Ki-moon (2007-2016)
- Part of Perspectives on Terrorism, Vol. 12, No. 4 (August 2018)
- Part of Leveraging Lives: Serbia and Illegal Tunisian Migration to Europe, Carnegie Endowment for International Peace (Mar. 1, 2023)
- Part of UCL Press
Harness the power of visual materials—explore more than 3 million images now on JSTOR.
Enhance your scholarly research with underground newspapers, magazines, and journals.
Explore collections in the arts, sciences, and literature from the world’s leading museums, archives, and scholars.
To position repositories as the foundation for a distributed, globally networked infrastructure for scholarly communication, on top of which layers of value added services will be deployed, thereby transforming the system, making it more research-centric, open to and supportive of innovation, while also collectively managed by the scholarly community.
Technical Vision
Our vision rests on making the resource, rather than the repository, the focus of services and infrastructure. Rather than relying on imprecise descriptive metadata to identify entities and the relationships between them, our vision relies on the idea inherent in the Web Architecture, where entities (known as "resources") are accessible and identified unambiguously by URLs. In this architecture, it is the references which are copied between systems, rather than (as at present) the metadata records. Furthermore we encourage repository developers to automatize the metadata extraction from the actual resources as much as possible to simplify and lower the barrier to the deposit process.
- To achieve a level of cross-repository interoperability by exposing uniform behaviours across repositories that leverage web-friendly technologies and architectures, and by integrating with existing global scholarly infrastructures specifically those aimed at identification of e.g. contributions, research data, contributors, institutions, funders, projects.
- To encourage the emergence of value added services that use these uniform behaviours to support discovery, access, annotation, real-time curation, sharing, quality assessment, content transfer, analytics, provenance tracing, etc.
- To help transform the scholarly communication system by emphasizing the benefits of collective, open and distributed management, open content, uniform behaviours, real-time dissemination, and collective innovation
Designed by Antleaf . Deployed with Hugo v. 0.124.1
- Search Search
- CN (Chinese)
- DE (German)
- ES (Spanish)
- FR (Français)
- JP (Japanese)
- Open research
- Booksellers
- Peer Reviewers
- Springer Nature Group ↗
- Publish an article
- Roles and responsibilities
- Signing your contract
- Writing your manuscript
- Submitting your manuscript
- Producing your book
- Promoting your book
- Submit your book idea
- Manuscript guidelines
- Book author services
- Publish a book
- Publish conference proceedings
- Research data policy
- Data availability statements
Data repository guidance
- Sensitive data
- Data policy FAQs
- Research data helpdesk
This resource is intended as a guide for those who are unsure where to deposit their data, and provides examples of repositories from a number of disciplines. This does not preclude the use of any data repository which does not appear in these pages. Please be aware that some repositories may charge for hosting data.
Data should be submitted to discipline-specific, community-recognised repositories where possible. In cases where a suitable discipline-specific resource does not exist, data may be submitted to a generalist data repository, including any generalist data repositories provided by universities, funders or institutions for their affiliated researchers.
Authors should consult individual journal guidance in case of more specific repository recommendations, as some Springer Nature journals maintain their own research data repositories. For more information browse our repositories FAQs .
Repository examples
- Tools & Services
- Account Development
- Sales and account contacts
- Professional
- Press office
- Locations & Contact
We are a world leading research, educational and professional publisher. Visit our main website for more information.
- © 2023 Springer Nature
- General terms and conditions
- Your US State Privacy Rights
- Your Privacy Choices / Manage Cookies
- Accessibility
- Legal notice
- Help us to improve this site, send feedback.
Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika aims to be a competitive open-source alternative to Devin by Cognition AI.
stitionai/devika
Contributors 26.
- Python 65.1%
- Svelte 17.3%
- Jinja 11.4%
- JavaScript 3.5%
- Dockerfile 1.1%
Skip navigation
- Log in to UX Certification
World Leaders in Research-Based User Experience
Design Thinking 101

July 31, 2016 2016-07-31
- Email article
- Share on LinkedIn
- Share on Twitter
In This Article:
Definition of design thinking, why — the advantage, flexibility — adapt to fit your needs, scalability — think bigger, history of design thinking.
Design thinking is an ideology supported by an accompanying process . A complete definition requires an understanding of both.
Definition: The design thinking ideology asserts that a hands-on, user-centric approach to problem solving can lead to innovation, and innovation can lead to differentiation and a competitive advantage. This hands-on, user-centric approach is defined by the design thinking process and comprises 6 distinct phases, as defined and illustrated below.
The design-thinking framework follows an overall flow of 1) understand, 2) explore, and 3) materialize. Within these larger buckets fall the 6 phases: empathize, define, ideate, prototype, test, and implement.

Conduct research in order to develop knowledge about what your users do, say, think, and feel .
Imagine your goal is to improve an onboarding experience for new users. In this phase, you talk to a range of actual users. Directly observe what they do, how they think, and what they want, asking yourself things like ‘what motivates or discourages users?’ or ‘where do they experience frustration?’ The goal is to gather enough observations that you can truly begin to empathize with your users and their perspectives.
Combine all your research and observe where your users’ problems exist. While pinpointing your users’ needs , begin to highlight opportunities for innovation.
Consider the onboarding example again. In the define phase, use the data gathered in the empathize phase to glean insights. Organize all your observations and draw parallels across your users’ current experiences. Is there a common pain point across many different users? Identify unmet user needs.
Brainstorm a range of crazy, creative ideas that address the unmet user needs identified in the define phase. Give yourself and your team total freedom; no idea is too farfetched and quantity supersedes quality.
At this phase, bring your team members together and sketch out many different ideas. Then, have them share ideas with one another, mixing and remixing, building on others' ideas.
Build real, tactile representations for a subset of your ideas. The goal of this phase is to understand what components of your ideas work, and which do not. In this phase you begin to weigh the impact vs. feasibility of your ideas through feedback on your prototypes.
Make your ideas tactile. If it is a new landing page, draw out a wireframe and get feedback internally. Change it based on feedback, then prototype it again in quick and dirty code. Then, share it with another group of people.
Return to your users for feedback. Ask yourself ‘Does this solution meet users’ needs?’ and ‘Has it improved how they feel, think, or do their tasks?’
Put your prototype in front of real customers and verify that it achieves your goals. Has the users’ perspective during onboarding improved? Does the new landing page increase time or money spent on your site? As you are executing your vision, continue to test along the way.
Put the vision into effect. Ensure that your solution is materialized and touches the lives of your end users.
This is the most important part of design thinking, but it is the one most often forgotten. As Don Norman preaches, “we need more design doing.” Design thinking does not free you from the actual design doing. It’s not magic.
“There’s no such thing as a creative type. As if creativity is a verb, a very time-consuming verb. It’s about taking an idea in your head, and transforming that idea into something real. And that’s always going to be a long and difficult process. If you’re doing it right, it’s going to feel like work.” - Milton Glaser
As impactful as design thinking can be for an organization, it only leads to true innovation if the vision is executed. The success of design thinking lies in its ability to transform an aspect of the end user’s life. This sixth step — implement — is crucial.
Why should we introduce a new way to think about product development? There are numerous reasons to engage in design thinking, enough to merit a standalone article, but in summary, design thinking achieves all these advantages at the same time.
Design thinking:
- Is a user-centered process that starts with user data, creates design artifacts that address real and not imaginary user needs, and then tests those artifacts with real users
- Leverages collective expertise and establishes a shared language, as well as buy-in amongst your team
- Encourages innovation by exploring multiple avenues for the same problem
Jakob Nielsen says “ a wonderful interface solving the wrong problem will fail ." Design thinking unfetters creative energies and focuses them on the right problem.
The above process will feel abstruse at first. Don’t think of it as if it were a prescribed step-by-step recipe for success. Instead, use it as scaffolding to support you when and where you need it. Be a master chef, not a line cook: take the recipe as a framework, then tweak as needed.
Each phase is meant to be iterative and cyclical as opposed to a strictly linear process, as depicted below. It is common to return to the two understanding phases, empathize and define, after an initial prototype is built and tested. This is because it is not until wireframes are prototyped and your ideas come to life that you are able to get a true representation of your design. For the first time, you can accurately assess if your solution really works. At this point, looping back to your user research is immensely helpful. What else do you need to know about the user in order to make decisions or to prioritize development order? What new use cases have arisen from the prototype that you didn’t previously research?
You can also repeat phases. It’s often necessary to do an exercise within a phase multiple times in order to arrive at the outcome needed to move forward. For example, in the define phase, different team members will have different backgrounds and expertise, and thus different approaches to problem identification. It’s common to spend an extended amount of time in the define phase, aligning a team to the same focus. Repetition is necessary if there are obstacles in establishing buy-in. The outcome of each phase should be sound enough to serve as a guiding principle throughout the rest of the process and to ensure that you never stray too far from your focus.

The packaged and accessible nature of design thinking makes it scalable. Organizations previously unable to shift their way of thinking now have a guide that can be comprehended regardless of expertise, mitigating the range of design talent while increasing the probability of success. This doesn’t just apply to traditional “designery” topics such as product design, but to a variety of societal, environmental, and economical issues. Design thinking is simple enough to be practiced at a range of scopes; even tough, undefined problems that might otherwise be overwhelming. While it can be applied over time to improve small functions like search, it can also be applied to design disruptive and transformative solutions, such as restructuring the career ladder for teachers in order to retain more talent.
It is a common misconception that design thinking is new. Design has been practiced for ages : monuments, bridges, automobiles, subway systems are all end-products of design processes. Throughout history, good designers have applied a human-centric creative process to build meaningful and effective solutions.
In the early 1900's husband and wife designers Charles and Ray Eames practiced “learning by doing,” exploring a range of needs and constraints before designing their Eames chairs, which continue to be in production even now, seventy years later. 1960's dressmaker Jean Muir was well known for her “common sense” approach to clothing design, placing as much emphasis on how her clothes felt to wear as they looked to others. These designers were innovators of their time. Their approaches can be viewed as early examples of design thinking — as they each developed a deep understanding of their users’ lives and unmet needs. Milton Glaser, the designer behind the famous I ♥ NY logo, describes this notion well: “We’re always looking, but we never really see…it’s the act of attention that allows you to really grasp something, to become fully conscious of it.”
Despite these (and other) early examples of human-centric products, design has historically been an afterthought in the business world, applied only to touch up a product’s aesthetics. This topical design application has resulted in corporations creating solutions which fail to meet their customers’ real needs. Consequently, some of these companies moved their designers from the end of the product-development process, where their contribution is limited, to the beginning. Their human-centric design approach proved to be a differentiator: those companies that used it have reaped the financial benefits of creating products shaped by human needs.
In order for this approach to be adopted across large organizations, it needed to be standardized. Cue design thinking, a formalized framework of applying the creative design process to traditional business problems.
The specific term "design thinking" was coined in the 1990's by David Kelley and Tim Brown of IDEO, with Roger Martin, and encapsulated methods and ideas that have been brewing for years into a single unified concept.
We live in an era of experiences , be they services or products, and we’ve come to have high expectations for these experiences. They are becoming more complex in nature as information and technology continues to evolve. With each evolution comes a new set of unmet needs. While design thinking is simply an approach to problem solving, it increases the probability of success and breakthrough innovation.
Learn more about design thinking in the full-day course Generating Big Ideas with Design Thinking .
Download the illustrations from this article from the link below in a high-resolution version that you can print as a poster or any desired size.
Free Downloads
Related courses, generating big ideas with design thinking.
Unearthing user pain points to drive breakthrough design concepts
Interaction
Service Blueprinting
Use service design to create processes that are core to your digital experience and everything that supports it
Assessing UX Designs Using Proven Principles
Generate insights, product scorecards and competitive analyses, even when you don’t have access to user data
Related Topics
- Design Process Design Process
- Managing UX Teams
Learn More:
Please accept marketing cookies to view the embedded video. https://www.youtube.com/watch?v=6lmvCqvmjfE

The Role of Design
Don Norman · 5 min

Design Thinking Activities
Sarah Gibbons · 5 min

Design Thinking: Top 3 Challenges and Solutions
Related Articles:
Design Thinking: Study Guide
Kate Moran and Megan Brown · 4 min
Service Blueprinting in Practice: Who, When, What
Alita Joyce and Sarah Gibbons · 7 min
Design Thinking Builds Strong Teams
User-Centered Intranet Redesign: Set Up for Success in 11 Steps
Kara Pernice · 10 min
UX Responsibilities in Scrum Events
Anna Kaley · 13 min
Journey Mapping: 9 Frequently Asked Questions
Alita Joyce and Kate Kaplan · 7 min
COVID-19 information and updates
- Public health information from CDC
- Grant and research information from NIH
- NIDDK COVID-19 Research Response
Home chevron_right Publications chevron_right Histologic Predictors of Improvement in Fibrosis in NASH: Results from the Clinical Research Network PIVENS Trial
Histologic predictors of improvement in fibrosis in nash: results from the clinical research network pivens trial, brunt em, kleiner de, wilson l, unalp a, tonascia j, neuschwander-tetri ba. histologic predictors of improvement in fibrosis in nash: results from the clinical research network pivens trial. hepatology 2012 oct;56(supplement s1):887a..
Public Release Type: Journal Publication Year: 2012 Authors: Kleiner DE, Brunt EM, Neuschwander-Tetri BA, Tonascia J, Unalp A, Wilson L Studies: Nonalcoholic Steatohepatitis Clinical Research Network , Pioglitazone vs Vitamin E vs Placebo for Treatment of Non-Diabetic Patients With Nonalcoholic Steatohepatitis
The primary response in the Pioglitazone v Vitamin E v Placebo for the Treatment of Nondiabetic Patients with Nonalcoholic Steatohepatitis (PIVENS) trial (NEJM 2010;18:1675) was histologic and defined as decrease in the nonalcoholic fatty liver disease activity score (NAS) =/>2 with at least one point contribution from hepatocellular ballooning and no worsening of fibrosis stage.
IMAGES
VIDEO
COMMENTS
A research repository is a shared collection of UX-research-related elements that should support the following functions at the organization level: grow UX awareness and participation in UX work among leadership, product owners, and the organization at large. support UX research work, so UX professionals may be more productive as they plan and ...
Publication of the global ResearchOps Community, sharing practical articles on research operations topics, updates from our work streams, and other community contributions. https://researchops ...
The Nielsen Norman Group (NNg) UX Podcast is a podcast on user experience research, design, strategy, and professions, hosted by Senior User Experience Specialist Therese Fessenden. Join us every month as she interviews industry experts, covering common questions, hot takes on pressing UX topics, and tips for building truly great user experiences. For free UX resources, references, and ...
A research repository is a system that stores all of your research data, notes, and documentation (such as research plans, interview guides, scripts, personas, competitor analysis, etc.) connected to the study. It allows for easy search and access by the entire team.
Abstract. For more than ten years, re3data, a global registry of research data repositories (RDRs), has been helping scientists, funding agencies, libraries, and data centers with finding ...
This repository contains the implementation of the paper: NNG-Mix: Improving Semi-supervised Anomaly Detection with Pseudo-anomaly Generation Hao Dong, Gaëtan Frusque, Yue Zhao, Eleni Chatzi and Olga Fink Link to the arXiv version of the paper is available.. We investigate improving semi-supervised anomaly detection performance from a novel viewpoint, by generating additional pseudo-anomalies ...
Saved searches Use saved searches to filter your results more quickly
Repository DescriptionThe NIH Common Fund's National Metabolomics Data Repository (NMDR) is now accepting metabolomics data for small and large studies on cells, tissues and organisms via the Metabolomics Workbench. We can accommodate a variety of metabolite analyses, including, but not limited to MS and NMR.
NNG, like its predecessors nanomsg (and to some extent ZeroMQ ), is a lightweight, broker-less library, offering a simple API to solve common recurring messaging problems, such as publish/subscribe, RPC-style request/reply, or service discovery. The API frees the programmer from worrying about details like connection management, retries, and ...
A research repository acts as a centralized database where information is gathered, stored, analyzed, and archived in one organized space. In this single source of truth, raw data, documents, reports, observations, and insights can be viewed, managed, and analyzed. This allows teams to organize raw data into themes, gather actionable insights ...
This article introduces nine best practices for research software registries and repositories. The practices are an outcome of a Task Force of the FORCE11 Software Citation Implementation Working Group and reflect the discussion, collaborative experiences, and consensus of over 30 experts and 14 resources.
Open Data is a strategy for incorporating research data into the permanent scientific record by releasing it under an Open Access license. Whether data is deposited in a purpose-built repository or published as Supporting Information alongside a research article, Open Data practices ensure that data remains accessible and discoverable.
Harness the power of visual materials—explore more than 3 million images now on JSTOR. Enhance your scholarly research with underground newspapers, magazines, and journals. Explore collections in the arts, sciences, and literature from the world's leading museums, archives, and scholars. JSTOR is a digital library of academic journals ...
Access 160+ million publications and connect with 25+ million researchers. Join for free and gain visibility by uploading your research.
ResearchOps: Scaling User Research. (This Course) Detailed coverage of topics central to ResearchOps, such as recruitment and research repositories. DesignOps: Scaling UX Design and User Research. Discussion of research repositories and ResearcOps roles with deeper dives into scaling design teams, operationalizing design systems, and defining ...
Objectives. To achieve a level of cross-repository interoperability by exposing uniform behaviours across repositories that leverage web-friendly technologies and architectures, and by integrating with existing global scholarly infrastructures specifically those aimed at identification of e.g. contributions, research data, contributors ...
Data repository guidance. This resource is intended as a guide for those who are unsure where to deposit their data, and provides examples of repositories from a number of disciplines. This does not preclude the use of any data repository which does not appear in these pages. Please be aware that some repositories may charge for hosting data.
Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika aims to be a competitive open-source alternative to Devin by Cognition AI. - stitionai/devika
Design thinking is an ideology supported by an accompanying process. A complete definition requires an understanding of both. Definition: The design thinking ideology asserts that a hands-on, user-centric approach to problem solving can lead to innovation, and innovation can lead to differentiation and a competitive advantage. This hands-on ...
Histologic Predictors of Improvement in Fibrosis in NASH: Results from the Clinical Research Network PIVENS Trial Brunt EM, Kleiner DE, Wilson L, Unalp A, Tonascia J, Neuschwander-Tetri BA. Histologic Predictors of Improvement in Fibrosis in NASH: Results from the Clinical Research Network PIVENS Trial. Hepatology 2012 Oct;56(Supplement S1):887A.