InfoQ Software Architects' Newsletter
A monthly overview of things you need to know as an architect or aspiring architects.
View an example
We protect your privacy.
Facilitating the Spread of Knowledge and Innovation in Professional Software Development
- English edition
- Chinese edition
- Japanese edition
- French edition
Back to login

Login with:
Don't have an infoq account, helpful links.
- About InfoQ
- InfoQ Editors
- Write for InfoQ
- About C4Media
Choose your language
Discover transformative insights to level up your software development decisions. Register now with early bird tickets.
Get practical advice from senior developers to navigate your current dev challenges. Register now with early bird tickets.
Level up your software skills by uncovering the emerging trends you should focus on. Register now.
Your monthly guide to all the topics, technologies and techniques that every professional needs to know about. Subscribe for free.
InfoQ Homepage News Prime Video Switched from Serverless to EC2 and ECS to Save Costs
Prime Video Switched from Serverless to EC2 and ECS to Save Costs
This item in japanese
May 03, 2023 2 min read
Rafal Gancarz
Infoq article contest.
Prime Video, Amazon's video streaming service, has explained how it re-architected the audio/video quality inspection solution to reduce operational costs and address scalability problems . It moved the workload to EC2 and ECS compute services, and achieved a 90% reduction in operational costs as a result.
The Video Quality Analysis (VQA) team at Prime Video created the original tool for inspecting the quality of audio/video streams that was able to detect various user experience quality issues and trigger appropriate repair actions.
The initial architecture of the solution was based on microservices responsible for executing steps of the overall analysis process, implemented on top of the serverless infrastructure stack. The microservices included splitting audio/video streams into video frames or decrypted audio buffers as well as detecting various stream defects by analyzing frames and audio buffers using machine-learning algorithms . AWS step functions were used as a primary process orchestration mechanism, coordinating the execution of several lambda functions . All audio/video data, including intermediate work items, were stored in AWS S3 buckets and an AWS SNS topic was used to deliver analysis results.

Source: https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
The team designed the distributed architecture to allow for horizontal scalability and leveraged serverless computing and storage to achieve faster implementation timelines. After operating the solution for a while, they started running into problems as the architecture has proven to only support around 5% of the expected load.
Marcin Kolny , senior software engineer at Prime Video, shares his team's assessment of the original architecture:
While onboarding more streams to the service, we noticed that running the infrastructure at a high scale was very expensive. We also noticed scaling bottlenecks that prevented us from monitoring thousands of streams. So, we took a step back and revisited the architecture of the existing service, focusing on the cost and scaling bottlenecks.
The problem of high operational cost was caused by a high volume of read/writes to the S3 bucket storing intermediate work items (video frames and audio buffers) and a large number of step function state transitions.
The other challenge was due to reaching the account limit of the overall number of state transitions, because the orchestration of the process involved several state transitions for each second of the analyzed audio/video stream.
In the end, the team decided to consolidate all of the business logic in a single application process. Kolny summarizes the revised design:
We realized that distributed approach wasn't bringing a lot of benefits in our specific use case, so we packed all of the components into a single process. This eliminated the need for the S3 bucket as the intermediate storage for video frames because our data transfer now happens in the memory. We also implemented orchestration that controls components within a single instance.
The resulting architecture had the entire stream analysis process running in ECS on EC2, with groups of detector instances distributed across different ECS tasks to avoid hitting vertical scaling limits when adding new detector types.

After rolling out the revised architecture, the Prime Video team was able to massively reduce costs (by 90%) but also ensure future cost savings by leveraging EC2 cost savings plans. Changes to the architecture have also addressed unforeseen scalability limitations that prevented the solution from handling all streams viewed by customers.
About the Author
Rate this article, this content is in the cloud topic, related topics:.
- Architecture & Design
- Cloud Architecture
- Architecture
- Cloud Computing
Related Editorial
Related sponsored content, popular across infoq, qcon london: meta used monolithic architecture to ship threads in only five months, architecting for high availability in the cloud with cellular architecture, architectures you’ve always wondered about 2024 emag, effective performance engineering at twitter-scale, java news roundup: jobrunr 7.0, introducing the commonhaus foundation, payara platform, devnexus, using cognitive science to improve developer experience, related content, the infoq newsletter.
A round-up of last week’s content on InfoQ sent out every Tuesday. Join a community of over 250,000 senior developers. View an example
Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%
The move from a distributed microservices architecture to a monolith application helped achieve higher scale, resilience, and reduce costs..

At Prime Video, we offer thousands of live streams to our customers. To ensure that customers seamlessly receive content, Prime Video set up a tool to monitor every stream viewed by customers. This tool allows us to automatically identify perceptual quality issues (for example, block corruption or audio/video sync problems) and trigger a process to fix them.
Our Video Quality Analysis (VQA) team at Prime Video already owned a tool for audio/video quality inspection, but we never intended nor designed it to run at high scale (our target was to monitor thousands of concurrent streams and grow that number over time). While onboarding more streams to the service, we noticed that running the infrastructure at a high scale was very expensive. We also noticed scaling bottlenecks that prevented us from monitoring thousands of streams. So, we took a step back and revisited the architecture of the existing service, focusing on the cost and scaling bottlenecks.
The initial version of our service consisted of distributed components that were orchestrated by AWS Step Functions . The two most expensive operations in terms of cost were the orchestration workflow and when data passed between distributed components. To address this, we moved all components into a single process to keep the data transfer within the process memory, which also simplified the orchestration logic. Because we compiled all the operations into a single process, we could rely on scalable Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Container Service (Amazon ECS) instances for the deployment.
Distributed systems overhead
Our service consists of three major components. The media converter converts input audio/video streams to frames or decrypted audio buffers that are sent to detectors. Defect detectors execute algorithms that analyze frames and audio buffers in real-time looking for defects (such as video freeze, block corruption, or audio/video synchronization problems) and send real-time notifications whenever a defect is found. For more information about this topic, see our How Prime Video uses machine learning to ensure video quality article. The third component provides orchestration that controls the flow in the service.
We designed our initial solution as a distributed system using serverless components (for example, AWS Step Functions or AWS Lambda ), which was a good choice for building the service quickly. In theory, this would allow us to scale each service component independently. However, the way we used some components caused us to hit a hard scaling limit at around 5% of the expected load. Also, the overall cost of all the building blocks was too high to accept the solution at a large scale.
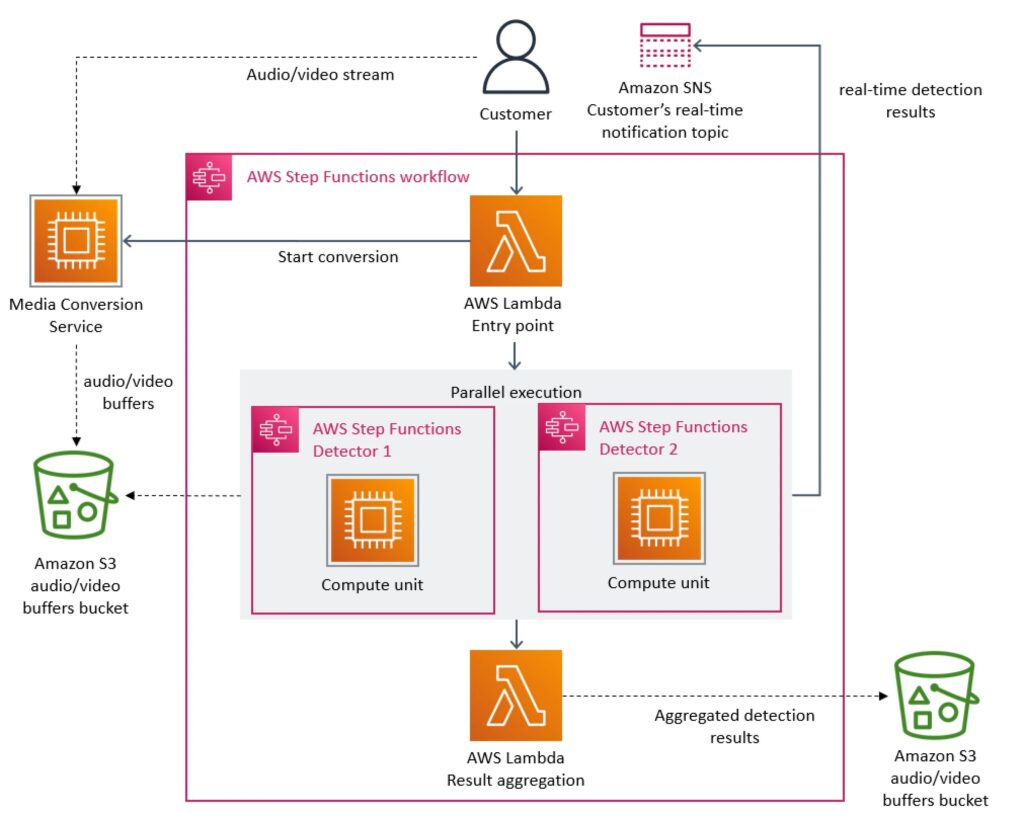
The following diagram shows the serverless architecture of our service.

The initial architecture of our defect detection system.
The main scaling bottleneck in the architecture was the orchestration management that was implemented using AWS Step Functions. Our service performed multiple state transitions for every second of the stream, so we quickly reached account limits. Besides that, AWS Step Functions charges users per state transition.
The second cost problem we discovered was about the way we were passing video frames (images) around different components. To reduce computationally expensive video conversion jobs, we built a microservice that splits videos into frames and temporarily uploads images to an Amazon Simple Storage Service (Amazon S3) bucket. Defect detectors (where each of them also runs as a separate microservice) then download images and processed it concurrently using AWS Lambda. However, the high number of Tier-1 calls to the S3 bucket was expensive.
From distributed microservices to a monolith application
To address the bottlenecks, we initially considered fixing problems separately to reduce cost and increase scaling capabilities. We experimented and took a bold decision: we decided to rearchitect our infrastructure.
We realized that distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all of the components into a single process. This eliminated the need for the S3 bucket as the intermediate storage for video frames because our data transfer now happened in the memory. We also implemented orchestration that controls components within a single instance.
The following diagram shows the architecture of the system after migrating to the monolith.

The updated architecture for monitoring a system with all components running inside a single Amazon ECS task.
Conceptually, the high-level architecture remained the same. We still have exactly the same components as we had in the initial design (media conversion, detectors, or orchestration). This allowed us to reuse a lot of code and quickly migrate to a new architecture.
In the initial design, we could scale several detectors horizontally, as each of them ran as a separate microservice (so adding a new detector required creating a new microservice and plug it in to the orchestration). However, in our new approach the number of detectors only scale vertically because they all run within the same instance. Our team regularly adds more detectors to the service and we already exceeded the capacity of a single instance. To overcome this problem, we cloned the service multiple times, parametrizing each copy with a different subset of detectors. We also implemented a lightweight orchestration layer to distribute customer requests.
The following diagram shows our solution for deploying detectors when the capacity of a single instance is exceeded.

Our approach for deploying more detectors to the service.
Results and takeaways
Microservices and serverless components are tools that do work at high scale, but whether to use them over monolith has to be made on a case-by-case basis.
Moving our service to a monolith reduced our infrastructure cost by over 90%. It also increased our scaling capabilities. Today, we’re able to handle thousands of streams and we still have capacity to scale the service even further. Moving the solution to Amazon EC2 and Amazon ECS also allowed us to use the Amazon EC2 compute saving plans that will help drive costs down even further.
Some decisions we’ve taken are not obvious but they resulted in significant improvements. For example, we replicated a computationally expensive media conversion process and placed it closer to the detectors. Whereas running media conversion once and caching its outcome might be considered to be a cheaper option, we found this not be a cost-effective approach.
The changes we’ve made allow Prime Video to monitor all streams viewed by our customers and not just the ones with the highest number of viewers. This approach results in even higher quality and an even better customer experience.
DEV Community
Posted on May 4, 2023
Microservices May Not Always Be the Answer: Lessons from Amazon Prime Video
Amazon Prime Video recently shared a case study about their decision to replace their serverless, microservices architecture with a monolith. The result? A 90% reduction in operating costs and a simpler system. This is a big win and it highlights a larger point for our industry: microservices may not always be the answer.
The Prime Video team initially designed their system as a distributed system using serverless components, with the idea that they could scale each component independently. However, they hit a hard scaling limit at around 5% of the expected load.
This experience shows that in practice, microservices can actually complicate your system unnecessarily. While service-oriented architectures like microservices make perfect sense at the scale of Amazon, it can wreak havoc when it's pushed into the internals of a single-application architecture.
It's important to note that microservices are not a one-size-fits-all solution. Instead, we should evaluate our options and choose what works best for our specific use case. In many cases, a monolith may be the way to go.
This doesn't mean we should abandon microservices altogether, but rather approach them with a critical eye. We should consider the complexity of our system, the scalability needs, and the maintenance costs when making architecture decisions.
Let's not get caught up in buzzwords or the latest trends. Instead, let's focus on finding the best solution for our unique challenges. The lessons from Amazon Prime Video show that sometimes, a simpler approach can be more effective.
Reference : Reference : https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
Top comments (0)
Templates let you quickly answer FAQs or store snippets for re-use.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment's permalink .
Hide child comments as well
For further actions, you may consider blocking this person and/or reporting abuse

Spring Boot 3 application on AWS Lambda - Part 2 Introduction to AWS Serverless Java Container
Vadym Kazulkin - Apr 1

The DevOps Basics 🚀
Tung Leo - Mar 31

A Complete Guide to Terraform Cloud Pricing
env0 Team - Apr 2

Learning AWS Day by Day — Day 24 — S3 Introduction — Part 2
Saloni Singh - Apr 2

We're a place where coders share, stay up-to-date and grow their careers.

The Amazon Prime Video Monolith Shift: Dissecting Microservices, Serverless, and the Real-World Cost
Explore amazon prime video's monolith shift, analyzing the real-world cost of microservices and serverless computing in a detailed case study..

Introduction
The Amazon Prime Video team’s recent case study has revealed an interesting shift from a serverless microservices architecture to a monolithic approach. This change resulted in a significant 90% reduction in operating expenses. This development has sparked discussions about the distinctions between serverless and microservices, and how to evaluate their respective merits and drawbacks. By examining Amazon Prime Video’s real-world experiences, we can gain valuable insights into serverless and microservices architectures, as well as their implications for system complexity and cost.
Distinguishing Between Serverless and Microservices
It is essential to understand the differences between serverless and microservices architectures. While microservices involve breaking down applications into smaller, independent services, serverless computing refers to an execution model where the cloud provider dynamically manages the allocation of resources. These two concepts can be used together, as seen in Amazon Prime Video’s initial architecture, but they can also be employed independently.
In the case study, Amazon Prime Video moved away from serverless components, not necessarily microservices. The team found that the serverless components in their architecture, such as AWS Step Functions and Lambda, were causing scaling bottlenecks and increasing costs. By removing these serverless components and simplifying their architecture, Amazon Prime Video was able to achieve significant cost savings.
Finding the Balance
The Amazon Prime Video case study demonstrates the importance of finding the right balance between serverless and microservices architectures for specific use cases. While serverless computing may offer benefits such as scalability and reduced operational overhead, it may not always be the optimal solution for every application or system. Similarly, microservices can provide increased flexibility, but they may also introduce unnecessary complexity in some situations.
Developers must carefully assess their project requirements and constraints before deciding which architectural patterns to adopt. In the Amazon Prime Video case study, the team found that removing serverless components from their architecture and transitioning to a monolithic approach led to better cost and performance optimization.
The Amazon Prime Video case study offers valuable insights into the real-world challenges and costs associated with serverless and microservices architectures. It highlights the importance of understanding the distinctions between these concepts and their suitability for various use cases. By maintaining a balanced approach and continuously evaluating the trade-offs between different architectures, developers can make well-informed decisions that optimize both cost and performance.
Thanks for reading Hacktivate! Subscribe for free to receive new posts and support my work.
🔗 Connect with me on LinkedIn! I hope you found this article helpful! If you’re interested in learning more and staying up-to-date with my latest insights and articles, don’t hesitate to connect with me on LinkedIn . Let’s grow our networks, engage in meaningful discussions, and share our experiences in the world of software development and beyond. Looking forward to connecting with you! 😊 Follow me on LinkedIn ➡️
Ready for more?
Debunking Misconceptions: Amazon Prime Video's Approach to Microservices and Serverless
Take a closer look at Amazon Prime Video's redesigned architecture, analyzing whether it heralds a shift back to monoliths or signifies a harmonious integration of different architectural styles.
This is the second blog in our deep dive series on serverless architectures. In the first installment, we explored the benefits and trade-offs of microservices and serverless architectures , highlighting the case of Amazon Prime Video's architectural redesign for cost optimization.
In this blog, we will take a closer look at Amazon Prime Video's redesigned architecture, analyzing whether it heralds a shift back to monoliths or signifies a harmonious integration of different architectural styles for optimal performance and cost efficiency. Additionally, we'll discuss the concept of a "serverless-first" mindset and the importance of considering alternative architectural approaches based on specific use cases and requirements.
Drawing from our own experience with serverless components in building a tracing collector API, we'll share the challenges we encountered and how they led us to reassess our approach. Now, let's dive into it.
Is Amazon moving away from micro-services and serverless?

Here’s how Prime Video rearchitected their system in their own words:

So clearly, Amazon Prime Video is not actually giving up on microservice-based serverless architectures. As explained in the post, they are redesigning a portion of their architecture (stream monitoring), in order to cut operational costs.
Although they removed serverless components from some places that were in the initial design (that version uses AWS Step Functions for the orchestration of detectors), they added them in other places.
Analyzing the New Design

Prime Video's new architecture design wasn't an outright reversal to the monolith but rather a thoughtful integration of different architectural styles tailored to their specific use case. The redesign combined serverless components, a monolith-style structure, and microservices. The monolithic part came into play with all of the components being compiled into a single process, eliminating the need for intermediary storage, simplifying orchestration logic, and significantly reducing operational costs.
However, certain functionalities still leveraged microservices, and AWS Lambda—a serverless component—was used to distribute incoming requests, allowing for efficient horizontal scaling. This underlines the utility and scalability of serverless components, despite the move towards a more monolithic structure for the particular problem they faced. In light of these observations, it's important to revisit the concept of a serverless-first mindset.
What about a serverless-first mindset?
Adopting a serverless-first mindset doesn't necessarily mean using serverless technology at every possible opportunity. Instead, it's about recognizing the potential benefits that serverless architectures can bring and considering them as a primary option when designing and developing new applications or services.
However, it's also crucial to understand that serverless may not always be the best fit depending on the specific use case, the nature of the workload, or the requirements of the system. Therefore, while a serverless-first approach encourages the exploration and application of serverless solutions, it also requires a balanced viewpoint and the wisdom to discern when a different architectural approach may be more suitable.
The Prime Video team's post illustrates how they applied a serverless-first mindset to build their audio and video monitoring service. Initially, they started with a serverless architecture, leveraging its benefits of scalability and reduced operational overhead.
Shipping the product faster gives some advantages:
- You will experience real cases in which some of them will be edge cases hard to predict or produce in advance.
- You will get feedback from your users quicker so it will help you to build the correct product and have product-market fit earlier.
- The sooner you ship, the more motivated your team will be and the more ownership your team will have of the product.
However, as Prime Video sought further cost optimizations, they strategically transitioned some components of their system to containers, taking advantage of the greater control over resources and potential cost savings that containers can offer. This approach exemplifies a balanced "serverless-first" mindset, where serverless solutions are considered the primary option, but the team remains open to other alternatives, such as containers, when they provide additional advantages for specific use cases or requirements.
Our Experience with Serverless Components
We had a similar experience implementing our tracing collector API, which initially, was implemented in AWS Lambda behind an AWS API Gateway. In the flow, the collector was getting the data from agents and sending them to an AWS Kinesis stream to be processed asynchronously. Building the collector API with serverless components (AWS API Gateway and AWS Lambda) helped us to ship the first version faster and let our users try and provide feedback quicker. As we worked to release this initial version, we ran into some challenges that led us to rethink our approach, as we will share in the next installment of this series.
You might also like
A gulf tale: navigating the potholes of customer experience in the digital era, the power of synthetic data to drive accurate ai and data models, the sre report 2024: essential considerations for readers.
Check out our Cloud Native Services and book a call with one of our experts today!
- Case Studies
- WTF is Cloud Native Collections
- Talk to our ChatBot

Cloud native , Microservices , Architecture
Reflections on Amazon Prime Video’s Monolith Move

Recently an Amazon Prime Video (APV) article about their move from serverless tools to ECS and EC2 did the rounds on all the tech socials. A lot of noise was made about it, initially because it was interpreted as a harbinger of the death of serverless technologies, followed by a second wave that lashed back against that narrative. This second wave argued that what had happened was not a failure of serverless, but rather a standard architectural evolution of an initial serverless microservices implementation to a ‘microservice refactoring’.
This brouhaha got me thinking about why, as an architect, I’ve never truly got onto the serverless boat, and what light this mini-drama throws on that stance. I ended up realising how Amazon and AWS had been at the centre of two computing revolutions that changed the computing paradigm we labour within.
Before I get to that, let’s recap the story so far.
The APV team had a service which monitored every stream viewed on the platform, and triggered a process to correct poorly-operating streams. This service was built using AWS’s serverless Step Functions and Lambda services, and was never intended to run at high scale.
As the service scaled, two problems were hit which together forced a re-architecture. Account limits were hit on the number of AWS Step Function transitions, and the cost of running the service was prohibitive.
In the article’s own words: ‘The move from a distributed microservices architecture to a monolith application helped achieve higher scale, resilience, and reduce costs. [...] We realised that [a] distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all of the components into a single process.’
The Reactions
There were more than a few commentators who relished the chance to herald this as the return of the monolith and/or the demise of the microservice. The New Stack led with an emotive ‘ Amazon Dumps Microservices ’ headline, while David Heinemeier Hansson, as usual, went for the jugular with ‘ Even Amazon Can’t Make Sense of Serverless or Microservices ’.
After this initial wave of ‘I told you so’ responses, a rearguard action was fought by defenders of serverless approaches to argue that reports of the death of the serverless and microservices was premature, and that others were misinterpreting the significance of the original article.
Adrian Cockroft, former AWS VP and well-known proponent of microservices fired back with ‘ So Many Bad Takes - What Is There To Learn From The Prime Video Microservices To Monolith Story ’, which argued that the original article did not describe a move from microservice to monolith, rather it was ‘clearly a microservice refactoring step’, and that the team’s evolution from serverless to microservice was a standard architectural pathway called ‘Serverless First’. In other words: nothing to see here, ‘the result isn’t a monolith’.
The Semantics
At this point, the debate has become a matter of semantics: What is a microservice? Looking at various definitions available , the essential unarguable point is that a microservice is ‘owned by a small team’. You can’t have a microservice that requires extensive coordination between teams to build or deploy.
But that can’t be the whole story, as you probably wouldn’t describe a small team that releases a single binary with an embedded database, a web server and a Ruby-on-Rails application as a microservice. A microservice implies that services are ‘fine-grained […] communicating through lightweight protocols’.
If a microservice is 'fine-grained', then there must be some element of component decomposition in a set of microservices that make up a set of applications. So what is a component? In the Amazon Prime Video case, you could argue both ways. You could say that the tool itself is a component, as it is a bounded piece of software managed by a small team, or you could say that the detectors and converters within the tool are separate components mushed into a now-monolithic application. You could even say that my imagined Ruby-on-Rails monolithic binary above is a microservice if you want to just define a component as something owned by a small team.
And what is an application? A service? A process? And on and on it goes. We can continue deconstructing terms all the way down the stack, and as we do so, we see that whether or not a piece of software is architecturally monolithic or a microservice is more or less a matter of perspective. My idea of a microservice can be the same as your idea of a monolith.
But does all this argumentation over words matter? Maybe not. Let’s ignore the question of what exactly a microservice or a monolith is for now (aside from ‘small team size’) and focus on another aspect of the story.
Easier to Scale?
The second paragraph of AWS’s definition of microservices made me raise my eyebrows:
‘Microservices architectures make applications easier to scale and faster to develop , enabling innovation and accelerating time-to-market for new features.’ Source: https://aws.amazon.com/microservices/
Regardless of what microservices were, these were their promised benefits: faster to develop, and easier to scale. What makes the AVP story so triggering to those of us who had been told we were dinosaurs is that the original serverless implementation of their tool was ludicrously un -scalable:
We designed our initial solution as a distributed system using serverless components (for example, AWS Step Functions or AWS Lambda), which was a good choice for building the service quickly. In theory, this would allow us to scale each service component independently. However, the way we used some components caused us to hit a hard scaling limit at around 5% of the expected load . Source: https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
and not just technically un-scalable, but financially too:
Also, the overall cost of all the building blocks was too high to accept the solution at a large scale. Source: https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
To me, this doesn’t sound like their approach has made it ‘easier to scale’.

Faster to Develop?
But what about the other benefit, that of being ‘faster to develop’? Adrian Cockroft’s post talks about this, and lays out this comparison table:

This is where I must protest, starting with the second line, which states that ‘traditional’, non-serverless/non-microservices development takes ‘months of work’ compared to the ‘hours of work’ microservices applications take to build.
Anyone who has actually built a serverless system in a real world context will know that it is not always, or even usually, ‘hours of work’. To take one small example of problems that can come up:

...to which you might add: difficulty of debugging, integration with other services, difficulty of testing scaling scenarios, state management, getting IAM rules right… the list goes on.
You might object to this, and argue that if your business has approved all the cloud provider’s services, and has a standard pattern for deploying them, and your staff is already well versed in the technologies and how to implement them, then yes, you can implement something in a few hours.
But this is where I’m baffled. In an analogous context, I have set up ‘traditional’ three-tier systems in a minimal and scalable way in a similar time-frame. Much of my career has been spent doing just that, and I still do that in my spare time because it’s easier for me for prototyping to do just that on a server than wiring together different cloud services.
The supposed development time difference between the two methods is not based on the technology itself, but the context in which you’re deploying it . The argument made by the table is tendentious. It’s based on comparing the worst case for ‘traditional’ application development (months of work) with the best case for ‘rapid development’ (hours of work). Similar arguments can be made for all the table’s comparisons.
The Water We Swim In
Context is everything in these debates. As all the experts point out, there is no architectural magic bullet that fits all use cases. Context is as complex as human existence itself, but here I want to focus on two areas specifically:
The governance context is the set of constraints on your freedom to build and deploy software. In a low-regulation startup these constraints are close to zero. The knowledge context is the degree to which you and your colleagues know how a set of technologies work. It’s assumptions around these contexts that make up the fault lines of most of the serverless debate. Take this tweet from AWS, which approvingly quotes the CEO of Serverless:
"The great thing about serverless is that you don't have to think about migrating a big app or building out this huge application, you just have to think about one task, one unit of work." - @austencollins , Founder & CEO @goserverless w/ @danilop . https://t.co/TVfP1CFCNS pic.twitter.com/yCuY8ChvmM — Amazon Web Services (@awscloud) January 30, 2020
The great thing about serverless is that you don't have to think about migrating a big app or building out this huge application, you just have to think about one task, one unit of work. @austencollins, Founder & CEO @goserverless
I can’t speak for other developers, but that’s almost always true for me most of the time when I write functions (or procedures) in ‘traditional’ codebases. When I’m doing that, I’m not thinking about IAM rules, how to connect to databases, the big app, the huge application. I’m just thinking about this one task, this unit of work. And conversely, if I’m working on a serverless application, I might have to think about all the problems I might run into that I listed above, starting with database connectivity.
You might object that a badly-written three-tier system makes it difficult to write such functions in isolation because of badly-structured monolithic codebases. Maybe so. But microservices architectures can be bad too, and let you ‘think about the one task’ you are doing when you should be thinking about the overall architecture. Maybe your one serverless task is going to cost a ludicrous amount of money (as with APV), or is duplicated elsewhere, or is going to bottleneck another task elsewhere.
Again: The supposed difference between the two methods is not based on the technology itself, but the context in which you’re working . If I’m fully bought into AWS as my platform from a governance and knowledge perspective, then serverless does allow me to focus on just the task I’m doing, because everything else is taken care of by the business around me. Note that this context is independent of 'the problem you are trying to solve'. That problem may or may not lend itself to a serverless architecture, but is not the context in which you're working . Here I’d like to bring up a David Foster Wallace parable about fish:
There are these two young fish swimming along and they happen to meet an older fish swimming the other way, who nods at them and says “Morning, boys. How’s the water?” And the two young fish swim on for a bit, and then eventually one of them looks over at the other and goes “What the hell is water?”
When you’re developing, you want your context to be like water to a fish: invisible, not in your way, sustaining you. But if I’m not a fish swimming in AWS’s metaphorical water, then I’m likely to splash around a lot if I dive into it.
Most advocates of serverless take it as a base assumption of the discussion that you are fully, maturely, and exclusively bought into cloud technologies, and the hyperscalers’ ecosystems. But for many more people working in software (including our customers), that’s not true, and they are wrestling with what, for them, is still a relatively unfamiliar environment.
A Confession
I want to make a confession. Based on what you’ve read so far, you might surmise I’m someone who doesn’t like the idea of serverless technology. But I’ve spent 23 years so far doing serverless work. Yes, I’m one of those people who claims to have 23 years experience in a 15-year old technology.
In fact, there’s many of us out there. This is because in those days we didn’t call these technologies ‘serverless’ or ‘Lambda’, we called them ‘stored procedures’.
https://twitter.com/ianmiell/status/921767022056345602
Serverless seems like stored procedures to me. The surrounding platform is just a cloud mainframe rather than a database. — Ian Miell (@ianmiell) October 21, 2017
I worked for a company for 15 of those years where the ‘ big iron ’ database was the water we swam in. We used it for message queues (at such a scale that IBM had to do some pretty nifty work to optimise for our specific use case and give us our own binaries off the main trunk), for our event-driven architectures (using triggers), and as our serverless platform (using stored procedures).
The joy of having a database as the platform was exactly the same then as the joys of having a serverless platform on a hyperscaler now. We didn’t have to provision compute resources for it (DBA’s problem), maintain the operating system (DBA’s problem), or worry or performance (DBA’s problem, mostly). We didn’t have to think about building a huge application, we just had to think about one task, one unit of work. And it took minutes to deploy.
People have drawn similar analogies between serverless and xinetd .
xinetd, but the daemons are containers. Not a bad idea, but certainly not the solution to everything, which is how some "serverless experts" seem to be approaching this. — Timothy Van Heest (@turtlemonvh) September 5, 2019
Serverless itself is nothing new. It’s just a name for what you’re doing when you can write code and let someone else manage the runtime environment (the ‘water’) for you. What’s new is the platform you treat as your water. For me 23 years ago, it was the database. Now it’s the cloud platform.
Mainframes, Clouds, Databases, and Lock-In
The other objection to serverless that’s often heard is that it increases your lock-in to the hyperscaler, something that many architects, CIOs, and regulators say they are concerned about. But as a colleague once quipped to me: “Lock-in? We are all locked into x86”, the point being that we’re all swimming in some kind of water, so it’s not about avoiding lock-in, but rather choosing your lock-in wisely.
It was symbolic when Amazon (not AWS) got rid of their last Oracle database in 2019, replacing them with AWS database services. In retrospect, this might be considered the point where businesses started to accept that their core platform had moved from a database to a cloud service provider. A similar inflection point where the mainframe platform was supplanted by commodity servers and PCs might be considered to be July 5, 1994, when Amazon itself was founded. Ironically, then, Amazon heralded both the death of the mainframe, and the birth of its replacement with AWS.
The Circle of Life
With this context in mind, it seems that the reason I never hopped onto the serverless train is because, to me, it’s not the software paradigm I was ushered into as a youngengineer. To me, quickly spinning up a three-tier application is as natural as throwing together an application using S3, DynamoDB, and API Gateway is for those cloud natives that cut their teeth knowing nothing else.
What strikes this old codger most about the Amazon Prime Video article is the sheer irony of serverless’s defenders saying that its lack of scalability is the reason you need to move to a more monolithic architecture. It was serverless’s very scalability and the avoidance of the need to re-architect later that was one of its key original selling points!
But when three-tier architectures started becoming popular I’m sure mainframers of the past said the same thing: “What’s the point of building software on commodity hardware, when it’ll end up on the mainframe?” Maybe they even leapt on articles describing how big businesses were moving their software back to the mainframe, having failed to make commodity servers work for them, and joyously proclaimed that rumours of the death of the mainframe was greatly exaggerated.
And in a way, maybe they were right. Amazon killed the physical mainframe, then killed the database mainframe, then created the cloud mainframe. Long live the monolith!

Engineering Ethics: It’s Not Just The Money We’re Talking Ab...
How eBPF enables Cloud Native Innovation and Performance
- Latest News
- WTF is Cloud Native
- Website terms of use
- Privacy policy
- Data Privacy for Job Seekers
- Cookie Notice
- Events Code of Conduct
Talk to sales
Stay in touch.
© 2024 Container Solutions

The Real Lesson from Prime Video’s Microservices → Monolith Story
May 10, 2023 AWS , Web App Development

The Article
Amazon Prime’s Video Quality Analysis (VCA) team went about building a tool to monitor each video stream for quality concerns. A member of their team wrote a blog post highlighting some cloud architecture decisions that were made which allowed them to scale their service while reducing costs by 90%. The TLDR summary is that they switched from an initial, serverless, microservice architecture to a more monolithic cloud architecture.
As AWS has been pitching serverless and microservice architectures for years, the internet enjoyed sounding off on this article. While it would be fun to talk about whether or not serverless/microservice architectures we find that such a discussion misses the tangible, immediately applicable lessons for designing our own infrastructure.
The Real Lesson
The real takeaway is that any potential technical solution must be evaluated against your specific use case, needs, and constraints. No solution is perfect, and tradeoffs and benefits of each option should be evaluated.
By building a cloud architecture optimized for their use case, and not for checking off buzz words, the Prime Video team saved money while implementing a better service. This is such a simple idea and takeaway that you may be asking what the point of this post is, but as always, execution itself is the tricky part. Furthermore, its worth emphasizing this key lesson when so much commentary has been given to debating the merits of microservices.
It is easy to image the Prime Video team going through a planning exercise while evaluating their cloud architecture, and saying:
1. What is the customer problem we are solving? We need robust, always on, video stream quality monitoring across so that we can identify issues and improve the customer’s streaming experience.
2. What are our target metrics for this solution? Service uptime, coverage of available streams, and cloud computing spend.
3. What restrictions exist for a potential solutions? Technical knowledge, budget, time, etc.
All three of these questions apply to any engineering team, and help guide solution development. Furthermore, when evaluating cloud architecture patterns, we can ask more specific questions applicable to virtually any organization:
Architecture Evaluation Checklist
- 1. What is the usage level and scale for this service? If the service is at an enormous scale and being utilized constantly, it might make sense to be wary of serverless. Why? Because the major cloud providers charge a slight premium on compute for the added value of abstracting away servers. For smaller applications and use cases with highly variable consumption, this is an excellent trade off vs. the cost of managing and maintaining servers or a K8s cluster. At Prime Video’s scale, however, the serverless premium was enormous.
- 2. How are individual services communicating/sharing data? Are there significant reads and write of data going on? If so, your bill may get hit with orchestration and networking fees, as we saw in the Prime Video case study. On the other hand, if communication is through message queues or pub/sub mechanisms, then this may be a less significant cost component of a potential serverless architecture.
- 2. How do you balance system complexity vs. server complexity? Coordinating a wide array of Serverless compute in a microservices architecture can lead to a higher level of complexity than a more monolithic design. Of course, the later has servers that are more difficult and expensive to manage and scale. Every organization needs to decide for their own use case which of these costs is more tolerable.
The debate around serverless microservices or a more monolithic structure is missing the forest for the trees. Any potential technical solution must be evaluated against your specific use case, needs, and constraints. The best framework, programming language, cloud computing resource, etc. for your use case…is the best one for your use case, not the one that is most “in vogue”. The Prime Video team simply used an architecture that works quite well for their use case. For teams that have lower usage demands than Prime Video, a serverless architecture’s benefits may greatly outway the costs.
dragondrop.cloud ’s mission is to automate developer best practices while working with Infrastructure as Code. Our flagship OSS product, cloud-concierge , allows developers to codify their cloud, detect drift, estimate cloud costs and security risks, and more — while delivering the results via a Pull Request. For enterprises running cloud-concierge at scale, we provide a management platform. To learn more, schedule a demo or get started today!
Learn More About Web Application Development
Firefly vs. control monkey vs. cloud-concierge in 2023.
Why a Cloud Asset Management Platform? With ever expanding cloud environments, having visiblity for and control of cloud assets is not a trivial task to perform manually. A series of offerings exist to automate this problem, providing functionality to at least: Detect...
Ripping out Python and Reducing Our Docker Image Size by ~87%
Background We built an OSS containerized tool, cloud-concierge, for automating Terraform best practices, and primarily implemented the solution in Go, given that Go generally is the “lingua franca” for Terraform tooling. With some gaps in Go, however, we built a few...
Running Remote DB Migrations via GitHub Actions
Motivation Database migrations are an essential component in the life cycle of any relational database. We needed a way to trigger database migrations in our development and production environments within our existing CI/CD pipelines running in GitHub Actions. We...
- The Register
- Blocks&Files
- The Next Platform
- Development
Reduce costs by 90% by moving from microservices to monolith: Amazon internal case study raises eyebrows

An Amazon case study from the Prime Video team has caused some surprise and amusement in the developer community, thanks to its frank assessment of how to save money by moving from a microservices architecture to a monolith, and avoiding costly services such as AWS Step Functions and Lambda serverless functions.
The requirement was for a monitoring tool to identify quality issues in “every stream viewed by customers” and therefore needed to be highly scalable, as there are “thousands of concurrent streams.” The team initially created a solution with distributed components orchestrated by AWS Step Functions, a serverless orchestration service based on state machines and tasks. It turned out though that Step Functions was a bottleneck.
“Our service performed multiple state transitions for every second of the stream, so we quickly reached account limits. Besides that, AWS Step Functions charges users per state transition,” the paper stated. There was also a “cost problem” with the “high number of tier-1 calls to the S3 bucket” used for temporary storage of captured video frames.
“We realized that distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all the components into a single process,” the paper continued, eliminating the need for S3. “We also implemented orchestration that controls components within a single instance.” The solution now runs on EC2 (Elastic Compute Cloud) and ECS (Elastic Container Service), with “a lightweight orchestration layer to distribute customer requests.”
The paper concludes that “Microservices and serverless components are tools that do work at high scale, but whether to use them over monolith has to be made on a case-by-case basis. Moving our service to a monolith reduced our infrastructure cost by over 90%. It also increased our scaling capabilities.” There is also reference to cost reduction via EC2 savings plans, suggesting that even internal AWS customers get billed according to a similar model as the rest of us.
“I’m sort of gobsmacked this article exists,” said a comment on Hacker News. Elsewhere AWS frequently touts the benefits of microservices and serverless architecture as the best way to “modernize” applications. For example, under Reliability, the AWS “Well-architected framework” advises :
“Build highly scalable and reliable workloads using a service-oriented architecture (SOA) or a microservices architecture. Service-oriented architecture (SOA) is the practice of making software components reusable via service interfaces. Microservices architecture goes further to make components smaller and simpler.”
In this “AWS Prescriptive Guidance” document for modernizing .NET applications, the company cites benefits of microservices including faster innovation, high availability and reliability, increased agility and on-demand scalability, modern CI/CD (continuous integration and deployment) pipelines, and strong module boundaries; though it also cites “operational complexity” as a disadvantage.
The new paper, though, seems to confirm a couple of suspicions among developers. One is that AWS-recommended solutions may not be the most cost-effective, as they invariably involve using multiple costly services.
Another is that the merits of microservices versus monolithic applications are frequently overstated. David Heinemeier Hansson, creator of Ruby on Rails and an advocate for reducing use of cloud services, commented on the Amazon case study saying that it “really sums up so much of the microservices craze that was tearing through the tech industry for a while: IN THEORY. Now the real-world results of all this theory are finally in, and it’s clear that in practice, microservices pose perhaps the biggest siren song for needlessly complicating your system. And serverless only makes it worse.” According to Hansson, “replacing method calls and module separations with network invocations and service partitioning within a single, coherent team and application is madness in almost all cases.”
In 2020, Sam Newman, consultant and author of books including “Building Microservices” and “Monolith to Microservices,” told a developer conference that “microservices should not be the default choice” and added advice to software architects in a comment to The Register “Have you done some value chain analysis? Have you looked at where the bottlenecks are? Have you tried modularisation? Microservices should be a last resort.”
Newman noted on Twitter today of the AWS paper: “this article is really speaking more about pricing models of functions vs long-running VMs than anything. Still a totally logical architectural driver, but the learnings from this case study likely have a more narrow range of applicability as a result.” He added that “the reason that people don’t talk publicly about walking back their foray into microservices is that it can be viewed by some as ‘they got it wrong’. Changing your mind when the situation changes is totally sane.”
The paper is not necessarily bad news for AWS. On the one hand, it goes against what the cloud giant tends to say is best practice; but on the other, it is a refreshingly honest look at how to reduce cost with a simplified architecture, as well as a case study in willingness to change track. Unlike many promotional case studies, this one looks genuinely useful to AWS customers.
DevClass is the news and analysis site covering modern software development issues, from the team behind the Continuous Lifecycle, Serverless Computing and MCubed conferences
Contact us: [email protected]
© Situation Publishing, 2018-2024
- Terms & Conditions
- Do not sell my personal information
Search the site
Amazon Prime Video team throws AWS Serverless under a bus
Monoliths are sexy again.
- Share on Twitter
- Share on Facebook
- Share on Pinterest
- Share on LinkedIn
- Share on WhatsApp
- Share via Email
Amazon Prime Video has dumped its AWS distributed serverless architecture and moved to what it describes as a “monolith” for its video quality analysis team in a move that it said has cut its cloud infrastructure costs 90%.
The shift saw the team swap an eclectic array of distributed microservices handling video/audio stream analysis processes for an architecture with all components running inside a single Amazon ECS task instead.

(Whether this constitutes a "monolith" as it is described in a Prime Video engineering blog that has triggered huge attention its or instead is now one large microservice is an open question; it has saved it a lot of money following the approach Adrian Cockcroft describes as "optimiz[ing] serverless applications by also building services using containers to solve for lower startup latency, long running compute jobs, and predictable high traffic.")
Senior software development engineer Marcin Kolny said on Prime’s technology blog that toolings built to assess every video stream and check for quality issues had initially been spun up as a “distributed system using serverless components" but that this architecture "caused us to hit a hard scaling limit at around 5% of the expected load" and the "cost of all the building blocks was too high to accept the solution at a large scale.”
This post is for subscribers only
Already have an account? Sign In
Google Cloud NEXT: AI for Workspace, BigQuery; compute, storage innovations, an Arm CPU...
Aws, google, oracle back redis fork “valkey” under the linux foundation, stick a fork in me, i'm done: redis slaps mongodb’s sspl licence on its oss core, blames cloud, complexity, scoop: fujitsu spilled private client data, passwords into the open unnoticed for a year, mona lisa rapping: microsoft’s new ai spins up convincing talking heads, grafana cofounder says community looking for flexibility, not demanding ai...yet, mod reopens £300m "human-machine teaming" framework, with a robotics focus, silly putty: ssh client hit with key-stealing bug.
IMAGES
VIDEO
COMMENTS
Prime Video, Amazon's video streaming service, has explained how it re-architected the audio/video quality inspection solution to reduce operational costs and address scalability problems. It ...
This video covers Amazon Prime Video's move towards Monolithic architecture from Serverless/Microservices based architecture to save cost and scale faster th...
A blog post from the engineering team at Amazon Prime Video has been roiling the cloud native computing community with its explanation that, at least in the case of the video monitoring, a monolithic architecture has produced superior performance over a microservices and serverless-led approach. May 4th, 2023 7:23am by Joab Jackson.
The Amazon Prime Video team's recent case study has revealed an interesting shift from a serverless microservices architecture to a monolithic approach. This change resulted in a significant 90% ...
6 takeaways IT pros should remember. There important lessons that enterprise IT leaders can learn from the Amazon Prime Video example. 1. It's not about the technology. "Don't start with ...
The second cost problem we discovered was about the way we were passing video frames (images) around different components. To reduce computationally expensive video conversion jobs, we built a microservice that splits videos into frames and temporarily uploads images to an Amazon Simple Storage Service (Amazon S3) bucket. Defect detectors ...
Amazon Prime Video uses the Amazon Web Service (AWS) Cloud as the underlying technology for all its services. "AWS gives us the flexibility, elasticity, and reliability we require," Winston says. Amazon Video also selected AWS Elemental, an Amazon Web Services company that combines deep video expertise with the power and scale of the cloud ...
The Fire TV team at Prime Video also decided to containerize its workloads and take a serverless-first approach—a decision that would help their engineers focus on feature delivery. "Instead of having engineers managing Amazon EC2 instances, we wanted them to work on features that would impact customers and add value to our business ...
A 90% reduction in operating costs and a simpler system. This is a big win and it highlights a larger point for our industry: microservices may not always be the answer. The Prime Video team initially designed their system as a distributed system using serverless components, with the idea that they could scale each component independently.
The Amazon Prime Video team's recent case study has revealed an interesting shift from a serverless microservices architecture to a monolithic approach. This change resulted in a significant 90% reduction in operating expenses. This development has sparked discussions about the distinctions between serverless and microservices, and how to ...
In this article, we will take a closer look at the case study and understand why Amazon moved from a microservices-based serverless architecture towards a monolithic architecture. We'll dissect it ...
This is the second blog in our deep dive series on serverless architectures. In the first installment, we explored the benefits and trade-offs of microservices and serverless architectures, highlighting the case of Amazon Prime Video's architectural redesign for cost optimization.. In this blog, we will take a closer look at Amazon Prime Video's redesigned architecture, analyzing whether it ...
In March, however, Prime Video's tech team stirred things up in the post "Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%," which explained how the move from a distributed microservices architecture to a monolithic approach helped achieve higher scale and resilience while lowering costs -- basically what serverless was supposed to do when replacing monoliths.
The Prime Video team simply used an architecture that works quite well for their use case. For teams that have lower usage demands than Prime Video, a serverless architecture's benefits may ...
May 30, 2023. 21 minutes Read. Recently an Amazon Prime Video (APV) articleabout their move from serverless tools to ECS and EC2 did the rounds on all the tech socials. A lot of noise was made about it, initially because it was interpreted as a harbinger of the death of serverless technologies, followed by a second wave that lashed back against ...
The Article. Amazon Prime's Video Quality Analysis (VCA) team went about building a tool to monitor each video stream for quality concerns. A member of their team wrote a blog post highlighting some cloud architecture decisions that were made which allowed them to scale their service while reducing costs by 90%. The TLDR summary is that they switched from an initial, serverless, microservice ...
Amazon Prime Video released an article explaining how they saved 90% on cloud computing costs by switching from microservices to a monolith. Let's examine th...
An Amazon case study from the Prime Video team has caused some surprise and amusement in the developer community, thanks to its frank assessment of how to save money by moving from a microservices architecture to a monolith, and avoiding costly services such as AWS Step Functions and Lambda serverless functions.
Amazon Prime Video reduced cost by 90% by switching from microservices to monolith. The initial version of our service consisted of distributed components that were orchestrated by AWS Step Functions. The two most expensive operations in terms of cost were the orchestration workflow and when data passed between distributed components.
Launched in 2006, Prime Video is a subscription-based, on-demand over-the-top streaming service, offered as part of a Prime subscription or as a stand-alone service. For years, the company has relied on dozens of personalization services to recommend new content to its customers. One of these services uses offline workflows that run periodically and provides insights and recommendations every ...
May 4, 2023 . 7:52 PM. 4 min read. Amazon Prime Video has dumped its AWS distributed serverless architecture and moved to what it describes as a "monolith" for its video quality analysis team in a move that it said has cut its cloud infrastructure costs 90%. The shift saw the team swap an eclectic array of distributed microservices handling ...
The Prime Video team at Amazon has published a rather remarkable case study on their decision to dump their serverless, microservices architecture and replace it with a monolith instead. This move saved them a staggering 90%(!!) on operating costs, and simplified the system too. What a win! But beyond celebrating their good sense, I th...
Even Amazon can't make sense of serverless or microservices. The author, David Heinemeier Hansson CTO and co-owner of Basecamp and Hey.com writes in his post that Amazon switched from a serverless, microservices architecture to a simpler monolithic system, and it resulted in a huge 90% reduction in operating costs. He uses (rightfully) this ...