
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Afr J Emerg Med
- v.7(3); 2017 Sep

A hands-on guide to doing content analysis
Christen erlingsson.
a Department of Health and Caring Sciences, Linnaeus University, Kalmar 391 82, Sweden
Petra Brysiewicz
b School of Nursing & Public Health, University of KwaZulu-Natal, Durban 4041, South Africa
Associated Data
There is a growing recognition for the important role played by qualitative research and its usefulness in many fields, including the emergency care context in Africa. Novice qualitative researchers are often daunted by the prospect of qualitative data analysis and thus may experience much difficulty in the data analysis process. Our objective with this manuscript is to provide a practical hands-on example of qualitative content analysis to aid novice qualitative researchers in their task.
African relevance
- • Qualitative research is useful to deepen the understanding of the human experience.
- • Novice qualitative researchers may benefit from this hands-on guide to content analysis.
- • Practical tips and data analysis templates are provided to assist in the analysis process.
Introduction
There is a growing recognition for the important role played by qualitative research and its usefulness in many fields, including emergency care research. An increasing number of health researchers are currently opting to use various qualitative research approaches in exploring and describing complex phenomena, providing textual accounts of individuals’ “life worlds”, and giving voice to vulnerable populations our patients so often represent. Many articles and books are available that describe qualitative research methods and provide overviews of content analysis procedures [1] , [2] , [3] , [4] , [5] , [6] , [7] , [8] , [9] , [10] . Some articles include step-by-step directions intended to clarify content analysis methodology. What we have found in our teaching experience is that these directions are indeed very useful. However, qualitative researchers, especially novice researchers, often struggle to understand what is happening on and between steps, i.e., how the steps are taken.
As research supervisors of postgraduate health professionals, we often meet students who present brilliant ideas for qualitative studies that have potential to fill current gaps in the literature. Typically, the suggested studies aim to explore human experience. Research questions exploring human experience are expediently studied through analysing textual data e.g., collected in individual interviews, focus groups, documents, or documented participant observation. When reflecting on the proposed study aim together with the student, we often suggest content analysis methodology as the best fit for the study and the student, especially the novice researcher. The interview data are collected and the content analysis adventure begins. Students soon realise that data based on human experiences are complex, multifaceted and often carry meaning on multiple levels.
For many novice researchers, analysing qualitative data is found to be unexpectedly challenging and time-consuming. As they soon discover, there is no step-wise analysis process that can be applied to the data like a pattern cutter at a textile factory. They may become extremely annoyed and frustrated during the hands-on enterprise of qualitative content analysis.
The novice researcher may lament, “I’ve read all the methodology but don’t really know how to start and exactly what to do with my data!” They grapple with qualitative research terms and concepts, for example; differences between meaning units, codes, categories and themes, and regarding increasing levels of abstraction from raw data to categories or themes. The content analysis adventure may now seem to be a chaotic undertaking. But, life is messy, complex and utterly fascinating. Experiencing chaos during analysis is normal. Good advice for the qualitative researcher is to be open to the complexity in the data and utilise one’s flow of creativity.
Inspired primarily by descriptions of “conventional content analysis” in Hsieh and Shannon [3] , “inductive content analysis” in Elo and Kyngäs [5] and “qualitative content analysis of an interview text” in Graneheim and Lundman [1] , we have written this paper to help the novice qualitative researcher navigate the uncertainty in-between the steps of qualitative content analysis. We will provide advice and practical tips, as well as data analysis templates, to attempt to ease frustration and hopefully, inspire readers to discover how this exciting methodology contributes to developing a deeper understanding of human experience and our professional contexts.
Overview of qualitative content analysis
Synopsis of content analysis.
A common starting point for qualitative content analysis is often transcribed interview texts. The objective in qualitative content analysis is to systematically transform a large amount of text into a highly organised and concise summary of key results. Analysis of the raw data from verbatim transcribed interviews to form categories or themes is a process of further abstraction of data at each step of the analysis; from the manifest and literal content to latent meanings ( Fig. 1 and Table 1 ).

Example of analysis leading to higher levels of abstraction; from manifest to latent content.
Glossary of terms as used in this hands-on guide to doing content analysis. *
The initial step is to read and re-read the interviews to get a sense of the whole, i.e., to gain a general understanding of what your participants are talking about. At this point you may already start to get ideas of what the main points or ideas are that your participants are expressing. Then one needs to start dividing up the text into smaller parts, namely, into meaning units. One then condenses these meaning units further. While doing this, you need to ensure that the core meaning is still retained. The next step is to label condensed meaning units by formulating codes and then grouping these codes into categories. Depending on the study’s aim and quality of the collected data, one may choose categories as the highest level of abstraction for reporting results or you can go further and create themes [1] , [2] , [3] , [5] , [8] .
Content analysis as a reflective process
You must mould the clay of the data , tapping into your intuition while maintaining a reflective understanding of how your own previous knowledge is influencing your analysis, i.e., your pre-understanding. In qualitative methodology, it is imperative to vigilantly maintain an awareness of one’s pre-understanding so that this does not influence analysis and/or results. This is the difficult balancing task of keeping a firm grip on one’s assumptions, opinions, and personal beliefs, and not letting them unconsciously steer your analysis process while simultaneously, and knowingly, utilising one’s pre-understanding to facilitate a deeper understanding of the data.
Content analysis, as in all qualitative analysis, is a reflective process. There is no “step 1, 2, 3, done!” linear progression in the analysis. This means that identifying and condensing meaning units, coding, and categorising are not one-time events. It is a continuous process of coding and categorising then returning to the raw data to reflect on your initial analysis. Are you still satisfied with the length of meaning units? Do the condensed meaning units and codes still “fit” with each other? Do the codes still fit into this particular category? Typically, a fair amount of adjusting is needed after the first analysis endeavour. For example: a meaning unit might need to be split into two meaning units in order to capture an additional core meaning; a code modified to more closely match the core meaning of the condensed meaning unit; or a category name tweaked to most accurately describe the included codes. In other words, analysis is a flexible reflective process of working and re-working your data that reveals connections and relationships. Once condensed meaning units are coded it is easier to get a bigger picture and see patterns in your codes and organise codes in categories.
Content analysis exercise
The synopsis above is representative of analysis descriptions in many content analysis articles. Although correct, such method descriptions still do not provide much support for the novice researcher during the actual analysis process. Aspiring to provide guidance and direction to support the novice, a practical example of doing the actual work of content analysis is provided in the following sections. This practical example is based on a transcribed interview excerpt that was part of a study that aimed to explore patients’ experiences of being admitted into the emergency centre ( Fig. 2 ).

Excerpt from interview text exploring “Patient’s experience of being admitted into the emergency centre”
This content analysis exercise provides instructions, tips, and advice to support the content analysis novice in a) familiarising oneself with the data and the hermeneutic spiral, b) dividing up the text into meaning units and subsequently condensing these meaning units, c) formulating codes, and d) developing categories and themes.
Familiarising oneself with the data and the hermeneutic spiral
An important initial phase in the data analysis process is to read and re-read the transcribed interview while keeping your aim in focus. Write down your initial impressions. Embrace your intuition. What is the text talking about? What stands out? How did you react while reading the text? What message did the text leave you with? In this analysis phase, you are gaining a sense of the text as a whole.
You may ask why this is important. During analysis, you will be breaking down the whole text into smaller parts. Returning to your notes with your initial impressions will help you see if your “parts” analysis is matching up with your first impressions of the “whole” text. Are your initial impressions visible in your analysis of the parts? Perhaps you need to go back and check for different perspectives. This is what is referred to as the hermeneutic spiral or hermeneutic circle. It is the process of comparing the parts to the whole to determine whether impressions of the whole verify the analysis of the parts in all phases of analysis. Each part should reflect the whole and the whole should be reflected in each part. This concept will become clearer as you start working with your data.
Dividing up the text into meaning units and condensing meaning units
You have now read the interview a number of times. Keeping your research aim and question clearly in focus, divide up the text into meaning units. Located meaning units are then condensed further while keeping the central meaning intact ( Table 2 ). The condensation should be a shortened version of the same text that still conveys the essential message of the meaning unit. Sometimes the meaning unit is already so compact that no further condensation is required. Some content analysis sources warn researchers against short meaning units, claiming that this can lead to fragmentation [1] . However, our personal experience as research supervisors has shown us that a greater problem for the novice is basing analysis on meaning units that are too large and include many meanings which are then lost in the condensation process.
Suggestion for how the exemplar interview text can be divided into meaning units and condensed meaning units ( condensations are in parentheses ).
Formulating codes
The next step is to develop codes that are descriptive labels for the condensed meaning units ( Table 3 ). Codes concisely describe the condensed meaning unit and are tools to help researchers reflect on the data in new ways. Codes make it easier to identify connections between meaning units. At this stage of analysis you are still keeping very close to your data with very limited interpretation of content. You may adjust, re-do, re-think, and re-code until you get to the point where you are satisfied that your choices are reasonable. Just as in the initial phase of getting to know your data as a whole, it is also good to write notes during coding on your impressions and reactions to the text.
Suggestions for coding of condensed meaning units.
Developing categories and themes
The next step is to sort codes into categories that answer the questions who , what , when or where? One does this by comparing codes and appraising them to determine which codes seem to belong together, thereby forming a category. In other words, a category consists of codes that appear to deal with the same issue, i.e., manifest content visible in the data with limited interpretation on the part of the researcher. Category names are most often short and factual sounding.
In data that is rich with latent meaning, analysis can be carried on to create themes. In our practical example, we have continued the process of abstracting data to a higher level, from category to theme level, and developed three themes as well as an overarching theme ( Table 4 ). Themes express underlying meaning, i.e., latent content, and are formed by grouping two or more categories together. Themes are answering questions such as why , how , in what way or by what means? Therefore, theme names include verbs, adverbs and adjectives and are very descriptive or even poetic.
Suggestion for organisation of coded meaning units into categories and themes.
Some reflections and helpful tips
Understand your pre-understandings.
While conducting qualitative research, it is paramount that the researcher maintains a vigilance of non-bias during analysis. In other words, did you remain aware of your pre-understandings, i.e., your own personal assumptions, professional background, and previous experiences and knowledge? For example, did you zero in on particular aspects of the interview on account of your profession (as an emergency doctor, emergency nurse, pre-hospital professional, etc.)? Did you assume the patient’s gender? Did your assumptions affect your analysis? How about aspects of culpability; did you assume that this patient was at fault or that this patient was a victim in the crash? Did this affect how you analysed the text?
Staying aware of one’s pre-understandings is exactly as difficult as it sounds. But, it is possible and it is requisite. Focus on putting yourself and your pre-understandings in a holding pattern while you approach your data with an openness and expectation of finding new perspectives. That is the key: expect the new and be prepared to be surprised. If something in your data feels unusual, is different from what you know, atypical, or even odd – don’t by-pass it as “wrong”. Your reactions and intuitive responses are letting you know that here is something to pay extra attention to, besides the more comfortable condensing and coding of more easily recognisable meaning units.
Use your intuition
Intuition is a great asset in qualitative analysis and not to be dismissed as “unscientific”. Intuition results from tacit knowledge. Just as tacit knowledge is a hallmark of great clinicians [11] , [12] ; it is also an invaluable tool in analysis work [13] . Literally, take note of your gut reactions and intuitive guidance and remember to write these down! These notes often form a framework of possible avenues for further analysis and are especially helpful as you lift the analysis to higher levels of abstraction; from meaning units to condensed meaning units, to codes, to categories and then to the highest level of abstraction in content analysis, themes.
Aspects of coding and categorising hard to place data
All too often, the novice gets overwhelmed by interview material that deals with the general subject matter of the interview, but doesn’t seem to answer the research question. Don’t be too quick to consider such text as off topic or dross [6] . There is often data that, although not seeming to match the study aim precisely, is still important for illuminating the problem area. This can be seen in our practical example about exploring patients’ experiences of being admitted into the emergency centre. Initially the participant is describing the accident itself. While not directly answering the research question, the description is important for understanding the context of the experience of being admitted into the emergency centre. It is very common that participants will “begin at the beginning” and prologue their narratives in order to create a context that sets the scene. This type of contextual data is vital for gaining a deepened understanding of participants’ experiences.
In our practical example, the participant begins by describing the crash and the rescue, i.e., experiences leading up to and prior to admission to the emergency centre. That is why we have chosen in our analysis to code the condensed meaning unit “Ambulance staff looked worried about all the blood” as “In the ambulance” and place it in the category “Reliving the rescue”. We did not choose to include this meaning unit in the categories specifically about admission to the emergency centre itself. Do you agree with our coding choice? Would you have chosen differently?
Another common problem for the novice is deciding how to code condensed meaning units when the unit can be labelled in several different ways. At this point researchers usually groan and wish they had thought to ask one of those classic follow-up questions like “Can you tell me a little bit more about that?” We have examples of two such coding conundrums in the exemplar, as can be seen in Table 3 (codes we conferred on) and Table 4 (codes we reached consensus on). Do you agree with our choices or would you have chosen different codes? Our best advice is to go back to your impressions of the whole and lean into your intuition when choosing codes that are most reasonable and best fit your data.
A typical problem area during categorisation, especially for the novice researcher, is overlap between content in more than one initial category, i.e., codes included in one category also seem to be a fit for another category. Overlap between initial categories is very likely an indication that the jump from code to category was too big, a problem not uncommon when the data is voluminous and/or very complex. In such cases, it can be helpful to first sort codes into narrower categories, so-called subcategories. Subcategories can then be reviewed for possibilities of further aggregation into categories. In the case of a problematic coding, it is advantageous to return to the meaning unit and check if the meaning unit itself fits the category or if you need to reconsider your preliminary coding.
It is not uncommon to be faced by thorny problems such as these during coding and categorisation. Here we would like to reiterate how valuable it is to have fellow researchers with whom you can discuss and reflect together with, in order to reach consensus on the best way forward in your data analysis. It is really advantageous to compare your analysis with meaning units, condensations, coding and categorisations done by another researcher on the same text. Have you identified the same meaning units? Do you agree on coding? See similar patterns in the data? Concur on categories? Sometimes referred to as “researcher triangulation,” this is actually a key element in qualitative analysis and an important component when striving to ensure trustworthiness in your study [14] . Qualitative research is about seeking out variations and not controlling variables, as in quantitative research. Collaborating with others during analysis lets you tap into multiple perspectives and often makes it easier to see variations in the data, thereby enhancing the quality of your results as well as contributing to the rigor of your study. It is important to note that it is not necessary to force consensus in the findings but one can embrace these variations in interpretation and use that to capture the richness in the data.
Yet there are times when neither openness, pre-understanding, intuition, nor researcher triangulation does the job; for example, when analysing an interview and one is simply confused on how to code certain meaning units. At such times, there are a variety of options. A good starting place is to re-read all the interviews through the lens of this specific issue and actively search for other similar types of meaning units you might have missed. Another way to handle this is to conduct further interviews with specific queries that hopefully shed light on the issue. A third option is to have a follow-up interview with the same person and ask them to explain.
Additional tips
It is important to remember that in a typical project there are several interviews to analyse. Codes found in a single interview serve as a starting point as you then work through the remaining interviews coding all material. Form your categories and themes when all project interviews have been coded.
When submitting an article with your study results, it is a good idea to create a table or figure providing a few key examples of how you progressed from the raw data of meaning units, to condensed meaning units, coding, categorisation, and, if included, themes. Providing such a table or figure supports the rigor of your study [1] and is an element greatly appreciated by reviewers and research consumers.
During the analysis process, it can be advantageous to write down your research aim and questions on a sheet of paper that you keep nearby as you work. Frequently referring to your aim can help you keep focused and on track during analysis. Many find it helpful to colour code their transcriptions and write notes in the margins.
Having access to qualitative analysis software can be greatly helpful in organising and retrieving analysed data. Just remember, a computer does not analyse the data. As Jennings [15] has stated, “… it is ‘peopleware,’ not software, that analyses.” A major drawback is that qualitative analysis software can be prohibitively expensive. One way forward is to use table templates such as we have used in this article. (Three analysis templates, Templates A, B, and C, are provided as supplementary online material ). Additionally, the “find” function in word processing programmes such as Microsoft Word (Redmond, WA USA) facilitates locating key words, e.g., in transcribed interviews, meaning units, and codes.
Lessons learnt/key points
From our experience with content analysis we have learnt a number of important lessons that may be useful for the novice researcher. They are:
- • A method description is a guideline supporting analysis and trustworthiness. Don’t get caught up too rigidly following steps. Reflexivity and flexibility are just as important. Remember that a method description is a tool helping you in the process of making sense of your data by reducing a large amount of text to distil key results.
- • It is important to maintain a vigilant awareness of one’s own pre-understandings in order to avoid bias during analysis and in results.
- • Use and trust your own intuition during the analysis process.
- • If possible, discuss and reflect together with other researchers who have analysed the same data. Be open and receptive to new perspectives.
- • Understand that it is going to take time. Even if you are quite experienced, each set of data is different and all require time to analyse. Don’t expect to have all the data analysis done over a weekend. It may take weeks. You need time to think, reflect and then review your analysis.
- • Keep reminding yourself how excited you have felt about this area of research and how interesting it is. Embrace it with enthusiasm!
- • Let it be chaotic – have faith that some sense will start to surface. Don’t be afraid and think you will never get to the end – you will… eventually!
Peer review under responsibility of African Federation for Emergency Medicine.
Appendix A Supplementary data associated with this article can be found, in the online version, at http://dx.doi.org/10.1016/j.afjem.2017.08.001 .
Appendix A. Supplementary data
Chapter 17. Content Analysis
Introduction.
Content analysis is a term that is used to mean both a method of data collection and a method of data analysis. Archival and historical works can be the source of content analysis, but so too can the contemporary media coverage of a story, blogs, comment posts, films, cartoons, advertisements, brand packaging, and photographs posted on Instagram or Facebook. Really, almost anything can be the “content” to be analyzed. This is a qualitative research method because the focus is on the meanings and interpretations of that content rather than strictly numerical counts or variables-based causal modeling. [1] Qualitative content analysis (sometimes referred to as QCA) is particularly useful when attempting to define and understand prevalent stories or communication about a topic of interest—in other words, when we are less interested in what particular people (our defined sample) are doing or believing and more interested in what general narratives exist about a particular topic or issue. This chapter will explore different approaches to content analysis and provide helpful tips on how to collect data, how to turn that data into codes for analysis, and how to go about presenting what is found through analysis. It is also a nice segue between our data collection methods (e.g., interviewing, observation) chapters and chapters 18 and 19, whose focus is on coding, the primary means of data analysis for most qualitative data. In many ways, the methods of content analysis are quite similar to the method of coding.

Although the body of material (“content”) to be collected and analyzed can be nearly anything, most qualitative content analysis is applied to forms of human communication (e.g., media posts, news stories, campaign speeches, advertising jingles). The point of the analysis is to understand this communication, to systematically and rigorously explore its meanings, assumptions, themes, and patterns. Historical and archival sources may be the subject of content analysis, but there are other ways to analyze (“code”) this data when not overly concerned with the communicative aspect (see chapters 18 and 19). This is why we tend to consider content analysis its own method of data collection as well as a method of data analysis. Still, many of the techniques you learn in this chapter will be helpful to any “coding” scheme you develop for other kinds of qualitative data. Just remember that content analysis is a particular form with distinct aims and goals and traditions.
An Overview of the Content Analysis Process
The first step: selecting content.
Figure 17.2 is a display of possible content for content analysis. The first step in content analysis is making smart decisions about what content you will want to analyze and to clearly connect this content to your research question or general focus of research. Why are you interested in the messages conveyed in this particular content? What will the identification of patterns here help you understand? Content analysis can be fun to do, but in order to make it research, you need to fit it into a research plan.
Figure 17.1. A Non-exhaustive List of "Content" for Content Analysis
To take one example, let us imagine you are interested in gender presentations in society and how presentations of gender have changed over time. There are various forms of content out there that might help you document changes. You could, for example, begin by creating a list of magazines that are coded as being for “women” (e.g., Women’s Daily Journal ) and magazines that are coded as being for “men” (e.g., Men’s Health ). You could then select a date range that is relevant to your research question (e.g., 1950s–1970s) and collect magazines from that era. You might create a “sample” by deciding to look at three issues for each year in the date range and a systematic plan for what to look at in those issues (e.g., advertisements? Cartoons? Titles of articles? Whole articles?). You are not just going to look at some magazines willy-nilly. That would not be systematic enough to allow anyone to replicate or check your findings later on. Once you have a clear plan of what content is of interest to you and what you will be looking at, you can begin, creating a record of everything you are including as your content. This might mean a list of each advertisement you look at or each title of stories in those magazines along with its publication date. You may decide to have multiple “content” in your research plan. For each content, you want a clear plan for collecting, sampling, and documenting.
The Second Step: Collecting and Storing
Once you have a plan, you are ready to collect your data. This may entail downloading from the internet, creating a Word document or PDF of each article or picture, and storing these in a folder designated by the source and date (e.g., “ Men’s Health advertisements, 1950s”). Sølvberg ( 2021 ), for example, collected posted job advertisements for three kinds of elite jobs (economic, cultural, professional) in Sweden. But collecting might also mean going out and taking photographs yourself, as in the case of graffiti, street signs, or even what people are wearing. Chaise LaDousa, an anthropologist and linguist, took photos of “house signs,” which are signs, often creative and sometimes offensive, hung by college students living in communal off-campus houses. These signs were a focal point of college culture, sending messages about the values of the students living in them. Some of the names will give you an idea: “Boot ’n Rally,” “The Plantation,” “Crib of the Rib.” The students might find these signs funny and benign, but LaDousa ( 2011 ) argued convincingly that they also reproduced racial and gender inequalities. The data here already existed—they were big signs on houses—but the researcher had to collect the data by taking photographs.
In some cases, your content will be in physical form but not amenable to photographing, as in the case of films or unwieldy physical artifacts you find in the archives (e.g., undigitized meeting minutes or scrapbooks). In this case, you need to create some kind of detailed log (fieldnotes even) of the content that you can reference. In the case of films, this might mean watching the film and writing down details for key scenes that become your data. [2] For scrapbooks, it might mean taking notes on what you are seeing, quoting key passages, describing colors or presentation style. As you might imagine, this can take a lot of time. Be sure you budget this time into your research plan.
Researcher Note
A note on data scraping : Data scraping, sometimes known as screen scraping or frame grabbing, is a way of extracting data generated by another program, as when a scraping tool grabs information from a website. This may help you collect data that is on the internet, but you need to be ethical in how to employ the scraper. A student once helped me scrape thousands of stories from the Time magazine archives at once (although it took several hours for the scraping process to complete). These stories were freely available, so the scraping process simply sped up the laborious process of copying each article of interest and saving it to my research folder. Scraping tools can sometimes be used to circumvent paywalls. Be careful here!
The Third Step: Analysis
There is often an assumption among novice researchers that once you have collected your data, you are ready to write about what you have found. Actually, you haven’t yet found anything, and if you try to write up your results, you will probably be staring sadly at a blank page. Between the collection and the writing comes the difficult task of systematically and repeatedly reviewing the data in search of patterns and themes that will help you interpret the data, particularly its communicative aspect (e.g., What is it that is being communicated here, with these “house signs” or in the pages of Men’s Health ?).
The first time you go through the data, keep an open mind on what you are seeing (or hearing), and take notes about your observations that link up to your research question. In the beginning, it can be difficult to know what is relevant and what is extraneous. Sometimes, your research question changes based on what emerges from the data. Use the first round of review to consider this possibility, but then commit yourself to following a particular focus or path. If you are looking at how gender gets made or re-created, don’t follow the white rabbit down a hole about environmental injustice unless you decide that this really should be the focus of your study or that issues of environmental injustice are linked to gender presentation. In the second round of review, be very clear about emerging themes and patterns. Create codes (more on these in chapters 18 and 19) that will help you simplify what you are noticing. For example, “men as outdoorsy” might be a common trope you see in advertisements. Whenever you see this, mark the passage or picture. In your third (or fourth or fifth) round of review, begin to link up the tropes you’ve identified, looking for particular patterns and assumptions. You’ve drilled down to the details, and now you are building back up to figure out what they all mean. Start thinking about theory—either theories you have read about and are using as a frame of your study (e.g., gender as performance theory) or theories you are building yourself, as in the Grounded Theory tradition. Once you have a good idea of what is being communicated and how, go back to the data at least one more time to look for disconfirming evidence. Maybe you thought “men as outdoorsy” was of importance, but when you look hard, you note that women are presented as outdoorsy just as often. You just hadn’t paid attention. It is very important, as any kind of researcher but particularly as a qualitative researcher, to test yourself and your emerging interpretations in this way.
The Fourth and Final Step: The Write-Up
Only after you have fully completed analysis, with its many rounds of review and analysis, will you be able to write about what you found. The interpretation exists not in the data but in your analysis of the data. Before writing your results, you will want to very clearly describe how you chose the data here and all the possible limitations of this data (e.g., historical-trace problem or power problem; see chapter 16). Acknowledge any limitations of your sample. Describe the audience for the content, and discuss the implications of this. Once you have done all of this, you can put forth your interpretation of the communication of the content, linking to theory where doing so would help your readers understand your findings and what they mean more generally for our understanding of how the social world works. [3]
Analyzing Content: Helpful Hints and Pointers
Although every data set is unique and each researcher will have a different and unique research question to address with that data set, there are some common practices and conventions. When reviewing your data, what do you look at exactly? How will you know if you have seen a pattern? How do you note or mark your data?
Let’s start with the last question first. If your data is stored digitally, there are various ways you can highlight or mark up passages. You can, of course, do this with literal highlighters, pens, and pencils if you have print copies. But there are also qualitative software programs to help you store the data, retrieve the data, and mark the data. This can simplify the process, although it cannot do the work of analysis for you.
Qualitative software can be very expensive, so the first thing to do is to find out if your institution (or program) has a universal license its students can use. If they do not, most programs have special student licenses that are less expensive. The two most used programs at this moment are probably ATLAS.ti and NVivo. Both can cost more than $500 [4] but provide everything you could possibly need for storing data, content analysis, and coding. They also have a lot of customer support, and you can find many official and unofficial tutorials on how to use the programs’ features on the web. Dedoose, created by academic researchers at UCLA, is a decent program that lacks many of the bells and whistles of the two big programs. Instead of paying all at once, you pay monthly, as you use the program. The monthly fee is relatively affordable (less than $15), so this might be a good option for a small project. HyperRESEARCH is another basic program created by academic researchers, and it is free for small projects (those that have limited cases and material to import). You can pay a monthly fee if your project expands past the free limits. I have personally used all four of these programs, and they each have their pluses and minuses.
Regardless of which program you choose, you should know that none of them will actually do the hard work of analysis for you. They are incredibly useful for helping you store and organize your data, and they provide abundant tools for marking, comparing, and coding your data so you can make sense of it. But making sense of it will always be your job alone.
So let’s say you have some software, and you have uploaded all of your content into the program: video clips, photographs, transcripts of news stories, articles from magazines, even digital copies of college scrapbooks. Now what do you do? What are you looking for? How do you see a pattern? The answers to these questions will depend partially on the particular research question you have, or at least the motivation behind your research. Let’s go back to the idea of looking at gender presentations in magazines from the 1950s to the 1970s. Here are some things you can look at and code in the content: (1) actions and behaviors, (2) events or conditions, (3) activities, (4) strategies and tactics, (5) states or general conditions, (6) meanings or symbols, (7) relationships/interactions, (8) consequences, and (9) settings. Table 17.1 lists these with examples from our gender presentation study.
Table 17.1. Examples of What to Note During Content Analysis
One thing to note about the examples in table 17.1: sometimes we note (mark, record, code) a single example, while other times, as in “settings,” we are recording a recurrent pattern. To help you spot patterns, it is useful to mark every setting, including a notation on gender. Using software can help you do this efficiently. You can then call up “setting by gender” and note this emerging pattern. There’s an element of counting here, which we normally think of as quantitative data analysis, but we are using the count to identify a pattern that will be used to help us interpret the communication. Content analyses often include counting as part of the interpretive (qualitative) process.
In your own study, you may not need or want to look at all of the elements listed in table 17.1. Even in our imagined example, some are more useful than others. For example, “strategies and tactics” is a bit of a stretch here. In studies that are looking specifically at, say, policy implementation or social movements, this category will prove much more salient.
Another way to think about “what to look at” is to consider aspects of your content in terms of units of analysis. You can drill down to the specific words used (e.g., the adjectives commonly used to describe “men” and “women” in your magazine sample) or move up to the more abstract level of concepts used (e.g., the idea that men are more rational than women). Counting for the purpose of identifying patterns is particularly useful here. How many times is that idea of women’s irrationality communicated? How is it is communicated (in comic strips, fictional stories, editorials, etc.)? Does the incidence of the concept change over time? Perhaps the “irrational woman” was everywhere in the 1950s, but by the 1970s, it is no longer showing up in stories and comics. By tracing its usage and prevalence over time, you might come up with a theory or story about gender presentation during the period. Table 17.2 provides more examples of using different units of analysis for this work along with suggestions for effective use.
Table 17.2. Examples of Unit of Analysis in Content Analysis
Every qualitative content analysis is unique in its particular focus and particular data used, so there is no single correct way to approach analysis. You should have a better idea, however, of what kinds of things to look for and what to look for. The next two chapters will take you further into the coding process, the primary analytical tool for qualitative research in general.
Further Readings
Cidell, Julie. 2010. “Content Clouds as Exploratory Qualitative Data Analysis.” Area 42(4):514–523. A demonstration of using visual “content clouds” as a form of exploratory qualitative data analysis using transcripts of public meetings and content of newspaper articles.
Hsieh, Hsiu-Fang, and Sarah E. Shannon. 2005. “Three Approaches to Qualitative Content Analysis.” Qualitative Health Research 15(9):1277–1288. Distinguishes three distinct approaches to QCA: conventional, directed, and summative. Uses hypothetical examples from end-of-life care research.
Jackson, Romeo, Alex C. Lange, and Antonio Duran. 2021. “A Whitened Rainbow: The In/Visibility of Race and Racism in LGBTQ Higher Education Scholarship.” Journal Committed to Social Change on Race and Ethnicity (JCSCORE) 7(2):174–206.* Using a “critical summative content analysis” approach, examines research published on LGBTQ people between 2009 and 2019.
Krippendorff, Klaus. 2018. Content Analysis: An Introduction to Its Methodology . 4th ed. Thousand Oaks, CA: SAGE. A very comprehensive textbook on both quantitative and qualitative forms of content analysis.
Mayring, Philipp. 2022. Qualitative Content Analysis: A Step-by-Step Guide . Thousand Oaks, CA: SAGE. Formulates an eight-step approach to QCA.
Messinger, Adam M. 2012. “Teaching Content Analysis through ‘Harry Potter.’” Teaching Sociology 40(4):360–367. This is a fun example of a relatively brief foray into content analysis using the music found in Harry Potter films.
Neuendorft, Kimberly A. 2002. The Content Analysis Guidebook . Thousand Oaks, CA: SAGE. Although a helpful guide to content analysis in general, be warned that this textbook definitely favors quantitative over qualitative approaches to content analysis.
Schrier, Margrit. 2012. Qualitative Content Analysis in Practice . Thousand Okas, CA: SAGE. Arguably the most accessible guidebook for QCA, written by a professor based in Germany.
Weber, Matthew A., Shannon Caplan, Paul Ringold, and Karen Blocksom. 2017. “Rivers and Streams in the Media: A Content Analysis of Ecosystem Services.” Ecology and Society 22(3).* Examines the content of a blog hosted by National Geographic and articles published in The New York Times and the Wall Street Journal for stories on rivers and streams (e.g., water-quality flooding).
- There are ways of handling content analysis quantitatively, however. Some practitioners therefore specify qualitative content analysis (QCA). In this chapter, all content analysis is QCA unless otherwise noted. ↵
- Note that some qualitative software allows you to upload whole films or film clips for coding. You will still have to get access to the film, of course. ↵
- See chapter 20 for more on the final presentation of research. ↵
- . Actually, ATLAS.ti is an annual license, while NVivo is a perpetual license, but both are going to cost you at least $500 to use. Student rates may be lower. And don’t forget to ask your institution or program if they already have a software license you can use. ↵
A method of both data collection and data analysis in which a given content (textual, visual, graphic) is examined systematically and rigorously to identify meanings, themes, patterns and assumptions. Qualitative content analysis (QCA) is concerned with gathering and interpreting an existing body of material.
Introduction to Qualitative Research Methods Copyright © 2023 by Allison Hurst is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
Qualitative Data Analysis Methods 101:
The “big 6” methods + examples.
By: Kerryn Warren (PhD) | Reviewed By: Eunice Rautenbach (D.Tech) | May 2020 (Updated April 2023)
Qualitative data analysis methods. Wow, that’s a mouthful.
If you’re new to the world of research, qualitative data analysis can look rather intimidating. So much bulky terminology and so many abstract, fluffy concepts. It certainly can be a minefield!
Don’t worry – in this post, we’ll unpack the most popular analysis methods , one at a time, so that you can approach your analysis with confidence and competence – whether that’s for a dissertation, thesis or really any kind of research project.

What (exactly) is qualitative data analysis?
To understand qualitative data analysis, we need to first understand qualitative data – so let’s step back and ask the question, “what exactly is qualitative data?”.
Qualitative data refers to pretty much any data that’s “not numbers” . In other words, it’s not the stuff you measure using a fixed scale or complex equipment, nor do you analyse it using complex statistics or mathematics.
So, if it’s not numbers, what is it?
Words, you guessed? Well… sometimes , yes. Qualitative data can, and often does, take the form of interview transcripts, documents and open-ended survey responses – but it can also involve the interpretation of images and videos. In other words, qualitative isn’t just limited to text-based data.
So, how’s that different from quantitative data, you ask?
Simply put, qualitative research focuses on words, descriptions, concepts or ideas – while quantitative research focuses on numbers and statistics . Qualitative research investigates the “softer side” of things to explore and describe , while quantitative research focuses on the “hard numbers”, to measure differences between variables and the relationships between them. If you’re keen to learn more about the differences between qual and quant, we’ve got a detailed post over here .

So, qualitative analysis is easier than quantitative, right?
Not quite. In many ways, qualitative data can be challenging and time-consuming to analyse and interpret. At the end of your data collection phase (which itself takes a lot of time), you’ll likely have many pages of text-based data or hours upon hours of audio to work through. You might also have subtle nuances of interactions or discussions that have danced around in your mind, or that you scribbled down in messy field notes. All of this needs to work its way into your analysis.
Making sense of all of this is no small task and you shouldn’t underestimate it. Long story short – qualitative analysis can be a lot of work! Of course, quantitative analysis is no piece of cake either, but it’s important to recognise that qualitative analysis still requires a significant investment in terms of time and effort.
Need a helping hand?
In this post, we’ll explore qualitative data analysis by looking at some of the most common analysis methods we encounter. We’re not going to cover every possible qualitative method and we’re not going to go into heavy detail – we’re just going to give you the big picture. That said, we will of course includes links to loads of extra resources so that you can learn more about whichever analysis method interests you.
Without further delay, let’s get into it.
The “Big 6” Qualitative Analysis Methods
There are many different types of qualitative data analysis, all of which serve different purposes and have unique strengths and weaknesses . We’ll start by outlining the analysis methods and then we’ll dive into the details for each.
The 6 most popular methods (or at least the ones we see at Grad Coach) are:
- Content analysis
- Narrative analysis
- Discourse analysis
- Thematic analysis
- Grounded theory (GT)
- Interpretive phenomenological analysis (IPA)
Let’s take a look at each of them…
QDA Method #1: Qualitative Content Analysis
Content analysis is possibly the most common and straightforward QDA method. At the simplest level, content analysis is used to evaluate patterns within a piece of content (for example, words, phrases or images) or across multiple pieces of content or sources of communication. For example, a collection of newspaper articles or political speeches.
With content analysis, you could, for instance, identify the frequency with which an idea is shared or spoken about – like the number of times a Kardashian is mentioned on Twitter. Or you could identify patterns of deeper underlying interpretations – for instance, by identifying phrases or words in tourist pamphlets that highlight India as an ancient country.
Because content analysis can be used in such a wide variety of ways, it’s important to go into your analysis with a very specific question and goal, or you’ll get lost in the fog. With content analysis, you’ll group large amounts of text into codes , summarise these into categories, and possibly even tabulate the data to calculate the frequency of certain concepts or variables. Because of this, content analysis provides a small splash of quantitative thinking within a qualitative method.
Naturally, while content analysis is widely useful, it’s not without its drawbacks . One of the main issues with content analysis is that it can be very time-consuming , as it requires lots of reading and re-reading of the texts. Also, because of its multidimensional focus on both qualitative and quantitative aspects, it is sometimes accused of losing important nuances in communication.
Content analysis also tends to concentrate on a very specific timeline and doesn’t take into account what happened before or after that timeline. This isn’t necessarily a bad thing though – just something to be aware of. So, keep these factors in mind if you’re considering content analysis. Every analysis method has its limitations , so don’t be put off by these – just be aware of them ! If you’re interested in learning more about content analysis, the video below provides a good starting point.
QDA Method #2: Narrative Analysis
As the name suggests, narrative analysis is all about listening to people telling stories and analysing what that means . Since stories serve a functional purpose of helping us make sense of the world, we can gain insights into the ways that people deal with and make sense of reality by analysing their stories and the ways they’re told.
You could, for example, use narrative analysis to explore whether how something is being said is important. For instance, the narrative of a prisoner trying to justify their crime could provide insight into their view of the world and the justice system. Similarly, analysing the ways entrepreneurs talk about the struggles in their careers or cancer patients telling stories of hope could provide powerful insights into their mindsets and perspectives . Simply put, narrative analysis is about paying attention to the stories that people tell – and more importantly, the way they tell them.
Of course, the narrative approach has its weaknesses , too. Sample sizes are generally quite small due to the time-consuming process of capturing narratives. Because of this, along with the multitude of social and lifestyle factors which can influence a subject, narrative analysis can be quite difficult to reproduce in subsequent research. This means that it’s difficult to test the findings of some of this research.
Similarly, researcher bias can have a strong influence on the results here, so you need to be particularly careful about the potential biases you can bring into your analysis when using this method. Nevertheless, narrative analysis is still a very useful qualitative analysis method – just keep these limitations in mind and be careful not to draw broad conclusions . If you’re keen to learn more about narrative analysis, the video below provides a great introduction to this qualitative analysis method.
QDA Method #3: Discourse Analysis
Discourse is simply a fancy word for written or spoken language or debate . So, discourse analysis is all about analysing language within its social context. In other words, analysing language – such as a conversation, a speech, etc – within the culture and society it takes place. For example, you could analyse how a janitor speaks to a CEO, or how politicians speak about terrorism.
To truly understand these conversations or speeches, the culture and history of those involved in the communication are important factors to consider. For example, a janitor might speak more casually with a CEO in a company that emphasises equality among workers. Similarly, a politician might speak more about terrorism if there was a recent terrorist incident in the country.
So, as you can see, by using discourse analysis, you can identify how culture , history or power dynamics (to name a few) have an effect on the way concepts are spoken about. So, if your research aims and objectives involve understanding culture or power dynamics, discourse analysis can be a powerful method.
Because there are many social influences in terms of how we speak to each other, the potential use of discourse analysis is vast . Of course, this also means it’s important to have a very specific research question (or questions) in mind when analysing your data and looking for patterns and themes, or you might land up going down a winding rabbit hole.
Discourse analysis can also be very time-consuming as you need to sample the data to the point of saturation – in other words, until no new information and insights emerge. But this is, of course, part of what makes discourse analysis such a powerful technique. So, keep these factors in mind when considering this QDA method. Again, if you’re keen to learn more, the video below presents a good starting point.
QDA Method #4: Thematic Analysis
Thematic analysis looks at patterns of meaning in a data set – for example, a set of interviews or focus group transcripts. But what exactly does that… mean? Well, a thematic analysis takes bodies of data (which are often quite large) and groups them according to similarities – in other words, themes . These themes help us make sense of the content and derive meaning from it.
Let’s take a look at an example.
With thematic analysis, you could analyse 100 online reviews of a popular sushi restaurant to find out what patrons think about the place. By reviewing the data, you would then identify the themes that crop up repeatedly within the data – for example, “fresh ingredients” or “friendly wait staff”.
So, as you can see, thematic analysis can be pretty useful for finding out about people’s experiences , views, and opinions . Therefore, if your research aims and objectives involve understanding people’s experience or view of something, thematic analysis can be a great choice.
Since thematic analysis is a bit of an exploratory process, it’s not unusual for your research questions to develop , or even change as you progress through the analysis. While this is somewhat natural in exploratory research, it can also be seen as a disadvantage as it means that data needs to be re-reviewed each time a research question is adjusted. In other words, thematic analysis can be quite time-consuming – but for a good reason. So, keep this in mind if you choose to use thematic analysis for your project and budget extra time for unexpected adjustments.
")
QDA Method #5: Grounded theory (GT)
Grounded theory is a powerful qualitative analysis method where the intention is to create a new theory (or theories) using the data at hand, through a series of “ tests ” and “ revisions ”. Strictly speaking, GT is more a research design type than an analysis method, but we’ve included it here as it’s often referred to as a method.
What’s most important with grounded theory is that you go into the analysis with an open mind and let the data speak for itself – rather than dragging existing hypotheses or theories into your analysis. In other words, your analysis must develop from the ground up (hence the name).
Let’s look at an example of GT in action.
Assume you’re interested in developing a theory about what factors influence students to watch a YouTube video about qualitative analysis. Using Grounded theory , you’d start with this general overarching question about the given population (i.e., graduate students). First, you’d approach a small sample – for example, five graduate students in a department at a university. Ideally, this sample would be reasonably representative of the broader population. You’d interview these students to identify what factors lead them to watch the video.
After analysing the interview data, a general pattern could emerge. For example, you might notice that graduate students are more likely to read a post about qualitative methods if they are just starting on their dissertation journey, or if they have an upcoming test about research methods.
From here, you’ll look for another small sample – for example, five more graduate students in a different department – and see whether this pattern holds true for them. If not, you’ll look for commonalities and adapt your theory accordingly. As this process continues, the theory would develop . As we mentioned earlier, what’s important with grounded theory is that the theory develops from the data – not from some preconceived idea.
So, what are the drawbacks of grounded theory? Well, some argue that there’s a tricky circularity to grounded theory. For it to work, in principle, you should know as little as possible regarding the research question and population, so that you reduce the bias in your interpretation. However, in many circumstances, it’s also thought to be unwise to approach a research question without knowledge of the current literature . In other words, it’s a bit of a “chicken or the egg” situation.
Regardless, grounded theory remains a popular (and powerful) option. Naturally, it’s a very useful method when you’re researching a topic that is completely new or has very little existing research about it, as it allows you to start from scratch and work your way from the ground up .
")
QDA Method #6: Interpretive Phenomenological Analysis (IPA)
Interpretive. Phenomenological. Analysis. IPA . Try saying that three times fast…
Let’s just stick with IPA, okay?
IPA is designed to help you understand the personal experiences of a subject (for example, a person or group of people) concerning a major life event, an experience or a situation . This event or experience is the “phenomenon” that makes up the “P” in IPA. Such phenomena may range from relatively common events – such as motherhood, or being involved in a car accident – to those which are extremely rare – for example, someone’s personal experience in a refugee camp. So, IPA is a great choice if your research involves analysing people’s personal experiences of something that happened to them.
It’s important to remember that IPA is subject – centred . In other words, it’s focused on the experiencer . This means that, while you’ll likely use a coding system to identify commonalities, it’s important not to lose the depth of experience or meaning by trying to reduce everything to codes. Also, keep in mind that since your sample size will generally be very small with IPA, you often won’t be able to draw broad conclusions about the generalisability of your findings. But that’s okay as long as it aligns with your research aims and objectives.
Another thing to be aware of with IPA is personal bias . While researcher bias can creep into all forms of research, self-awareness is critically important with IPA, as it can have a major impact on the results. For example, a researcher who was a victim of a crime himself could insert his own feelings of frustration and anger into the way he interprets the experience of someone who was kidnapped. So, if you’re going to undertake IPA, you need to be very self-aware or you could muddy the analysis.

How to choose the right analysis method
In light of all of the qualitative analysis methods we’ve covered so far, you’re probably asking yourself the question, “ How do I choose the right one? ”
Much like all the other methodological decisions you’ll need to make, selecting the right qualitative analysis method largely depends on your research aims, objectives and questions . In other words, the best tool for the job depends on what you’re trying to build. For example:
- Perhaps your research aims to analyse the use of words and what they reveal about the intention of the storyteller and the cultural context of the time.
- Perhaps your research aims to develop an understanding of the unique personal experiences of people that have experienced a certain event, or
- Perhaps your research aims to develop insight regarding the influence of a certain culture on its members.
As you can probably see, each of these research aims are distinctly different , and therefore different analysis methods would be suitable for each one. For example, narrative analysis would likely be a good option for the first aim, while grounded theory wouldn’t be as relevant.
It’s also important to remember that each method has its own set of strengths, weaknesses and general limitations. No single analysis method is perfect . So, depending on the nature of your research, it may make sense to adopt more than one method (this is called triangulation ). Keep in mind though that this will of course be quite time-consuming.
As we’ve seen, all of the qualitative analysis methods we’ve discussed make use of coding and theme-generating techniques, but the intent and approach of each analysis method differ quite substantially. So, it’s very important to come into your research with a clear intention before you decide which analysis method (or methods) to use.
Start by reviewing your research aims , objectives and research questions to assess what exactly you’re trying to find out – then select a qualitative analysis method that fits. Never pick a method just because you like it or have experience using it – your analysis method (or methods) must align with your broader research aims and objectives.

Let’s recap on QDA methods…
In this post, we looked at six popular qualitative data analysis methods:
- First, we looked at content analysis , a straightforward method that blends a little bit of quant into a primarily qualitative analysis.
- Then we looked at narrative analysis , which is about analysing how stories are told.
- Next up was discourse analysis – which is about analysing conversations and interactions.
- Then we moved on to thematic analysis – which is about identifying themes and patterns.
- From there, we went south with grounded theory – which is about starting from scratch with a specific question and using the data alone to build a theory in response to that question.
- And finally, we looked at IPA – which is about understanding people’s unique experiences of a phenomenon.
Of course, these aren’t the only options when it comes to qualitative data analysis, but they’re a great starting point if you’re dipping your toes into qualitative research for the first time.
If you’re still feeling a bit confused, consider our private coaching service , where we hold your hand through the research process to help you develop your best work.

Psst… there’s more (for free)
This post is part of our dissertation mini-course, which covers everything you need to get started with your dissertation, thesis or research project.
You Might Also Like:

84 Comments

This has been very helpful. Thank you.

Thank you madam,

Thank you so much for this information

I wonder it so clear for understand and good for me. can I ask additional query?

Very insightful and useful

Good work done with clear explanations. Thank you.

Thanks so much for the write-up, it’s really good.

Thanks madam . It is very important .

thank you very good

This has been very well explained in simple language . It is useful even for a new researcher.

Great to hear that. Good luck with your qualitative data analysis, Pramod!

This is very useful information. And it was very a clear language structured presentation. Thanks a lot.

Thank you so much.

very informative sequential presentation

Precise explanation of method.

Hi, may we use 2 data analysis methods in our qualitative research?
Thanks for your comment. Most commonly, one would use one type of analysis method, but it depends on your research aims and objectives.

You explained it in very simple language, everyone can understand it. Thanks so much.

Thank you very much, this is very helpful. It has been explained in a very simple manner that even a layman understands

Thank nicely explained can I ask is Qualitative content analysis the same as thematic analysis?
Thanks for your comment. No, QCA and thematic are two different types of analysis. This article might help clarify – https://onlinelibrary.wiley.com/doi/10.1111/nhs.12048

This is my first time to come across a well explained data analysis. so helpful.

I have thoroughly enjoyed your explanation of the six qualitative analysis methods. This is very helpful. Thank you!

Thank you very much, this is well explained and useful

i need a citation of your book.

Thanks a lot , remarkable indeed, enlighting to the best

Hi Derek, What other theories/methods would you recommend when the data is a whole speech?

Keep writing useful artikel.

It is important concept about QDA and also the way to express is easily understandable, so thanks for all.

Thank you, this is well explained and very useful.

Very helpful .Thanks.

Hi there! Very well explained. Simple but very useful style of writing. Please provide the citation of the text. warm regards

The session was very helpful and insightful. Thank you
This was very helpful and insightful. Easy to read and understand

As a professional academic writer, this has been so informative and educative. Keep up the good work Grad Coach you are unmatched with quality content for sure.
Keep up the good work Grad Coach you are unmatched with quality content for sure.

Its Great and help me the most. A Million Thanks you Dr.

It is a very nice work

Very insightful. Please, which of this approach could be used for a research that one is trying to elicit students’ misconceptions in a particular concept ?

This is Amazing and well explained, thanks

great overview

What do we call a research data analysis method that one use to advise or determining the best accounting tool or techniques that should be adopted in a company.

Informative video, explained in a clear and simple way. Kudos

Waoo! I have chosen method wrong for my data analysis. But I can revise my work according to this guide. Thank you so much for this helpful lecture.

This has been very helpful. It gave me a good view of my research objectives and how to choose the best method. Thematic analysis it is.

Very helpful indeed. Thanku so much for the insight.

This was incredibly helpful.

Very helpful.

very educative

Nicely written especially for novice academic researchers like me! Thank you.

choosing a right method for a paper is always a hard job for a student, this is a useful information, but it would be more useful personally for me, if the author provide me with a little bit more information about the data analysis techniques in type of explanatory research. Can we use qualitative content analysis technique for explanatory research ? or what is the suitable data analysis method for explanatory research in social studies?

that was very helpful for me. because these details are so important to my research. thank you very much

I learnt a lot. Thank you

Relevant and Informative, thanks !

Well-planned and organized, thanks much! 🙂

I have reviewed qualitative data analysis in a simplest way possible. The content will highly be useful for developing my book on qualitative data analysis methods. Cheers!

Clear explanation on qualitative and how about Case study

This was helpful. Thank you

This was really of great assistance, it was just the right information needed. Explanation very clear and follow.
Wow, Thanks for making my life easy

This was helpful thanks .

Very helpful…. clear and written in an easily understandable manner. Thank you.

This was so helpful as it was easy to understand. I’m a new to research thank you so much.

so educative…. but Ijust want to know which method is coding of the qualitative or tallying done?

Thank you for the great content, I have learnt a lot. So helpful

precise and clear presentation with simple language and thank you for that.

very informative content, thank you.

You guys are amazing on YouTube on this platform. Your teachings are great, educative, and informative. kudos!

Brilliant Delivery. You made a complex subject seem so easy. Well done.

Beautifully explained.
Thanks a lot

Is there a video the captures the practical process of coding using automated applications?
Thanks for the comment. We don’t recommend using automated applications for coding, as they are not sufficiently accurate in our experience.

content analysis can be qualitative research?

THANK YOU VERY MUCH.

Thank you very much for such a wonderful content

do you have any material on Data collection

What a powerful explanation of the QDA methods. Thank you.

Great explanation both written and Video. i have been using of it on a day to day working of my thesis project in accounting and finance. Thank you very much for your support.

very helpful, thank you so much
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
Content Analysis | A Step-by-Step Guide with Examples
Published on 5 May 2022 by Amy Luo . Revised on 5 December 2022.
Content analysis is a research method used to identify patterns in recorded communication. To conduct content analysis, you systematically collect data from a set of texts, which can be written, oral, or visual:
- Books, newspapers, and magazines
- Speeches and interviews
- Web content and social media posts
- Photographs and films
Content analysis can be both quantitative (focused on counting and measuring) and qualitative (focused on interpreting and understanding). In both types, you categorise or ‘code’ words, themes, and concepts within the texts and then analyse the results.
Table of contents
What is content analysis used for, advantages of content analysis, disadvantages of content analysis, how to conduct content analysis.
Researchers use content analysis to find out about the purposes, messages, and effects of communication content. They can also make inferences about the producers and audience of the texts they analyse.
Content analysis can be used to quantify the occurrence of certain words, phrases, subjects, or concepts in a set of historical or contemporary texts.
In addition, content analysis can be used to make qualitative inferences by analysing the meaning and semantic relationship of words and concepts.
Because content analysis can be applied to a broad range of texts, it is used in a variety of fields, including marketing, media studies, anthropology, cognitive science, psychology, and many social science disciplines. It has various possible goals:
- Finding correlations and patterns in how concepts are communicated
- Understanding the intentions of an individual, group, or institution
- Identifying propaganda and bias in communication
- Revealing differences in communication in different contexts
- Analysing the consequences of communication content, such as the flow of information or audience responses
Prevent plagiarism, run a free check.
- Unobtrusive data collection
You can analyse communication and social interaction without the direct involvement of participants, so your presence as a researcher doesn’t influence the results.
- Transparent and replicable
When done well, content analysis follows a systematic procedure that can easily be replicated by other researchers, yielding results with high reliability .
- Highly flexible
You can conduct content analysis at any time, in any location, and at low cost. All you need is access to the appropriate sources.
Focusing on words or phrases in isolation can sometimes be overly reductive, disregarding context, nuance, and ambiguous meanings.
Content analysis almost always involves some level of subjective interpretation, which can affect the reliability and validity of the results and conclusions.
- Time intensive
Manually coding large volumes of text is extremely time-consuming, and it can be difficult to automate effectively.
If you want to use content analysis in your research, you need to start with a clear, direct research question .
Next, you follow these five steps.
Step 1: Select the content you will analyse
Based on your research question, choose the texts that you will analyse. You need to decide:
- The medium (e.g., newspapers, speeches, or websites) and genre (e.g., opinion pieces, political campaign speeches, or marketing copy)
- The criteria for inclusion (e.g., newspaper articles that mention a particular event, speeches by a certain politician, or websites selling a specific type of product)
- The parameters in terms of date range, location, etc.
If there are only a small number of texts that meet your criteria, you might analyse all of them. If there is a large volume of texts, you can select a sample .
Step 2: Define the units and categories of analysis
Next, you need to determine the level at which you will analyse your chosen texts. This means defining:
- The unit(s) of meaning that will be coded. For example, are you going to record the frequency of individual words and phrases, the characteristics of people who produced or appear in the texts, the presence and positioning of images, or the treatment of themes and concepts?
- The set of categories that you will use for coding. Categories can be objective characteristics (e.g., aged 30–40, lawyer, parent) or more conceptual (e.g., trustworthy, corrupt, conservative, family-oriented).
Step 3: Develop a set of rules for coding
Coding involves organising the units of meaning into the previously defined categories. Especially with more conceptual categories, it’s important to clearly define the rules for what will and won’t be included to ensure that all texts are coded consistently.
Coding rules are especially important if multiple researchers are involved, but even if you’re coding all of the text by yourself, recording the rules makes your method more transparent and reliable.
Step 4: Code the text according to the rules
You go through each text and record all relevant data in the appropriate categories. This can be done manually or aided with computer programs, such as QSR NVivo , Atlas.ti , and Diction , which can help speed up the process of counting and categorising words and phrases.
Step 5: Analyse the results and draw conclusions
Once coding is complete, the collected data is examined to find patterns and draw conclusions in response to your research question. You might use statistical analysis to find correlations or trends, discuss your interpretations of what the results mean, and make inferences about the creators, context, and audience of the texts.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Luo, A. (2022, December 05). Content Analysis | A Step-by-Step Guide with Examples. Scribbr. Retrieved 2 April 2024, from https://www.scribbr.co.uk/research-methods/content-analysis-explained/
Is this article helpful?

Other students also liked
How to do thematic analysis | guide & examples, data collection methods | step-by-step guide & examples, qualitative vs quantitative research | examples & methods.
Qualitative Research and Content Analysis
- First Online: 01 November 2019
Cite this chapter

- Helvi Kyngäs 4
8696 Accesses
39 Citations
This chapter presents a general overview of qualitative research. Scholars can employ diverse quantitative and qualitative research designs to investigate a phenomenon of interest. However, thorough descriptions of these methods are beyond the scope of this book. Rather, the aim is to provide a general picture of qualitative research and an accurate, comprehensible explanation of content analysis and its potential applications, e.g., in systematic literature review and theory development. Research areas within nursing science are multi-faceted and focus on the human being, environment, health and nursing. Hence, different research designs are needed to answer distinct research questions. Qualitative research approaches are commonly used when there is little current understanding of a complex phenomenon (which cannot be addressed simply by taking physical measurements), if an issue is being considered from a new perspective, or if current knowledge is fragmented. Content analysis is one of the many methods used in qualitative research. The main advantages of content analysis are that it is content-sensitive, can be applied in highly flexible research designs, and used to analyse many types of qualitative data.
- Qualitative research
- Quantitative research
- Research approaches
- Qualitative analysis methods
- Inductive approach
- Deductive approach
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Polit D, Beck C. Nursing research: generating and assessing evidence for nursing practice. 9th ed. Philadelphia: Wolters Kluwer Health; Lippincott Williams & Wilkins; 2012.
Google Scholar
Robson C. Real world research: a resource for social scientists and practitioner-researchers. Oxford: Blackwell; 1993.
Green J, Thorogood N. Qualitative methods for health research. In: Denzin NK, Lincoln YS, editors. The SAGE handbook of qualitative research. 4th ed. Los Angeles: SAGE Publications; 2011. p. 387–400.
Creswell JW. Qualitative inquiry and research design. Choosing among five approaches. California: SAGE Publications; 2013.
Allmark P, Machaczek K. Realism and Pragmatism in a mixed methods study. J Adv Nurs. 2018;74:1301–9. https://doi.org/10.1111/jan.13523 .
Article PubMed Google Scholar
Neuman WL. Social research methods: qualitative and quantitative approaches. 5th ed. Boston: Allyn and Bacon; 2003.
Sarantakos S. Social research. 3rd ed. Melbourne: Macmillan Education; 2005.
Book Google Scholar
Elo S, Kyngäs H. The qualitative content analysis process. J Adv Nurs. 2008;62:107–15.
Article Google Scholar
Sandelowski M. Qualitative analysis: what it is and how to begin. Res Nurs Health. 1995;18:371–5.
Article CAS Google Scholar
Sandelowski M. Real qualitative researchers do not count: the use of numbers in qualitative research. Res Nurs Health. 2001;24:230–40.
Holloway I, Wheeler S. Qualitative research in nursing and healthcare. Oxford: Blackwell Publishing; 2010.
Pyett PM. Validation of qualitative research in the “real world”. Qual Health Res. 2004;13:1170–9.
Hastings J. Qualitative data analysis from start to finish. Los Angles: SAGE Publications; 2013.
Sandelowski M, Leeman J. Writing usable qualitative health research findings. Qual Health Res. 2011;22:1404–13.
Download references
Author information
Authors and affiliations.
Research Unit of Nursing Science and Health Management, Oulu University, Oulu, Finland
Helvi Kyngäs
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Helvi Kyngäs .
Editor information
Editors and affiliations.
Research Unit of Nursing Science and Health Management, University of Oulu, Oulu, Finland
Kristina Mikkonen
Maria Kääriäinen
Rights and permissions
Reprints and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this chapter
Kyngäs, H. (2020). Qualitative Research and Content Analysis. In: Kyngäs, H., Mikkonen, K., Kääriäinen, M. (eds) The Application of Content Analysis in Nursing Science Research. Springer, Cham. https://doi.org/10.1007/978-3-030-30199-6_1
Download citation
DOI : https://doi.org/10.1007/978-3-030-30199-6_1
Published : 01 November 2019
Publisher Name : Springer, Cham
Print ISBN : 978-3-030-30198-9
Online ISBN : 978-3-030-30199-6
eBook Packages : Medicine Medicine (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Skip to content
Read the latest news stories about Mailman faculty, research, and events.
Departments
We integrate an innovative skills-based curriculum, research collaborations, and hands-on field experience to prepare students.
Learn more about our research centers, which focus on critical issues in public health.
Our Faculty
Meet the faculty of the Mailman School of Public Health.
Become a Student
Life and community, how to apply.
Learn how to apply to the Mailman School of Public Health.
Content Analysis
Content analysis is a research tool used to determine the presence of certain words, themes, or concepts within some given qualitative data (i.e. text). Using content analysis, researchers can quantify and analyze the presence, meanings, and relationships of such certain words, themes, or concepts. As an example, researchers can evaluate language used within a news article to search for bias or partiality. Researchers can then make inferences about the messages within the texts, the writer(s), the audience, and even the culture and time of surrounding the text.
Description
Sources of data could be from interviews, open-ended questions, field research notes, conversations, or literally any occurrence of communicative language (such as books, essays, discussions, newspaper headlines, speeches, media, historical documents). A single study may analyze various forms of text in its analysis. To analyze the text using content analysis, the text must be coded, or broken down, into manageable code categories for analysis (i.e. “codes”). Once the text is coded into code categories, the codes can then be further categorized into “code categories” to summarize data even further.
Three different definitions of content analysis are provided below.
Definition 1: “Any technique for making inferences by systematically and objectively identifying special characteristics of messages.” (from Holsti, 1968)
Definition 2: “An interpretive and naturalistic approach. It is both observational and narrative in nature and relies less on the experimental elements normally associated with scientific research (reliability, validity, and generalizability) (from Ethnography, Observational Research, and Narrative Inquiry, 1994-2012).
Definition 3: “A research technique for the objective, systematic and quantitative description of the manifest content of communication.” (from Berelson, 1952)
Uses of Content Analysis
Identify the intentions, focus or communication trends of an individual, group or institution
Describe attitudinal and behavioral responses to communications
Determine the psychological or emotional state of persons or groups
Reveal international differences in communication content
Reveal patterns in communication content
Pre-test and improve an intervention or survey prior to launch
Analyze focus group interviews and open-ended questions to complement quantitative data
Types of Content Analysis
There are two general types of content analysis: conceptual analysis and relational analysis. Conceptual analysis determines the existence and frequency of concepts in a text. Relational analysis develops the conceptual analysis further by examining the relationships among concepts in a text. Each type of analysis may lead to different results, conclusions, interpretations and meanings.
Conceptual Analysis
Typically people think of conceptual analysis when they think of content analysis. In conceptual analysis, a concept is chosen for examination and the analysis involves quantifying and counting its presence. The main goal is to examine the occurrence of selected terms in the data. Terms may be explicit or implicit. Explicit terms are easy to identify. Coding of implicit terms is more complicated: you need to decide the level of implication and base judgments on subjectivity (an issue for reliability and validity). Therefore, coding of implicit terms involves using a dictionary or contextual translation rules or both.
To begin a conceptual content analysis, first identify the research question and choose a sample or samples for analysis. Next, the text must be coded into manageable content categories. This is basically a process of selective reduction. By reducing the text to categories, the researcher can focus on and code for specific words or patterns that inform the research question.
General steps for conducting a conceptual content analysis:
1. Decide the level of analysis: word, word sense, phrase, sentence, themes
2. Decide how many concepts to code for: develop a pre-defined or interactive set of categories or concepts. Decide either: A. to allow flexibility to add categories through the coding process, or B. to stick with the pre-defined set of categories.
Option A allows for the introduction and analysis of new and important material that could have significant implications to one’s research question.
Option B allows the researcher to stay focused and examine the data for specific concepts.
3. Decide whether to code for existence or frequency of a concept. The decision changes the coding process.
When coding for the existence of a concept, the researcher would count a concept only once if it appeared at least once in the data and no matter how many times it appeared.
When coding for the frequency of a concept, the researcher would count the number of times a concept appears in a text.
4. Decide on how you will distinguish among concepts:
Should text be coded exactly as they appear or coded as the same when they appear in different forms? For example, “dangerous” vs. “dangerousness”. The point here is to create coding rules so that these word segments are transparently categorized in a logical fashion. The rules could make all of these word segments fall into the same category, or perhaps the rules can be formulated so that the researcher can distinguish these word segments into separate codes.
What level of implication is to be allowed? Words that imply the concept or words that explicitly state the concept? For example, “dangerous” vs. “the person is scary” vs. “that person could cause harm to me”. These word segments may not merit separate categories, due the implicit meaning of “dangerous”.
5. Develop rules for coding your texts. After decisions of steps 1-4 are complete, a researcher can begin developing rules for translation of text into codes. This will keep the coding process organized and consistent. The researcher can code for exactly what he/she wants to code. Validity of the coding process is ensured when the researcher is consistent and coherent in their codes, meaning that they follow their translation rules. In content analysis, obeying by the translation rules is equivalent to validity.
6. Decide what to do with irrelevant information: should this be ignored (e.g. common English words like “the” and “and”), or used to reexamine the coding scheme in the case that it would add to the outcome of coding?
7. Code the text: This can be done by hand or by using software. By using software, researchers can input categories and have coding done automatically, quickly and efficiently, by the software program. When coding is done by hand, a researcher can recognize errors far more easily (e.g. typos, misspelling). If using computer coding, text could be cleaned of errors to include all available data. This decision of hand vs. computer coding is most relevant for implicit information where category preparation is essential for accurate coding.
8. Analyze your results: Draw conclusions and generalizations where possible. Determine what to do with irrelevant, unwanted, or unused text: reexamine, ignore, or reassess the coding scheme. Interpret results carefully as conceptual content analysis can only quantify the information. Typically, general trends and patterns can be identified.
Relational Analysis
Relational analysis begins like conceptual analysis, where a concept is chosen for examination. However, the analysis involves exploring the relationships between concepts. Individual concepts are viewed as having no inherent meaning and rather the meaning is a product of the relationships among concepts.
To begin a relational content analysis, first identify a research question and choose a sample or samples for analysis. The research question must be focused so the concept types are not open to interpretation and can be summarized. Next, select text for analysis. Select text for analysis carefully by balancing having enough information for a thorough analysis so results are not limited with having information that is too extensive so that the coding process becomes too arduous and heavy to supply meaningful and worthwhile results.
There are three subcategories of relational analysis to choose from prior to going on to the general steps.
Affect extraction: an emotional evaluation of concepts explicit in a text. A challenge to this method is that emotions can vary across time, populations, and space. However, it could be effective at capturing the emotional and psychological state of the speaker or writer of the text.
Proximity analysis: an evaluation of the co-occurrence of explicit concepts in the text. Text is defined as a string of words called a “window” that is scanned for the co-occurrence of concepts. The result is the creation of a “concept matrix”, or a group of interrelated co-occurring concepts that would suggest an overall meaning.
Cognitive mapping: a visualization technique for either affect extraction or proximity analysis. Cognitive mapping attempts to create a model of the overall meaning of the text such as a graphic map that represents the relationships between concepts.
General steps for conducting a relational content analysis:
1. Determine the type of analysis: Once the sample has been selected, the researcher needs to determine what types of relationships to examine and the level of analysis: word, word sense, phrase, sentence, themes. 2. Reduce the text to categories and code for words or patterns. A researcher can code for existence of meanings or words. 3. Explore the relationship between concepts: once the words are coded, the text can be analyzed for the following:
Strength of relationship: degree to which two or more concepts are related.
Sign of relationship: are concepts positively or negatively related to each other?
Direction of relationship: the types of relationship that categories exhibit. For example, “X implies Y” or “X occurs before Y” or “if X then Y” or if X is the primary motivator of Y.
4. Code the relationships: a difference between conceptual and relational analysis is that the statements or relationships between concepts are coded. 5. Perform statistical analyses: explore differences or look for relationships among the identified variables during coding. 6. Map out representations: such as decision mapping and mental models.
Reliability and Validity
Reliability : Because of the human nature of researchers, coding errors can never be eliminated but only minimized. Generally, 80% is an acceptable margin for reliability. Three criteria comprise the reliability of a content analysis:
Stability: the tendency for coders to consistently re-code the same data in the same way over a period of time.
Reproducibility: tendency for a group of coders to classify categories membership in the same way.
Accuracy: extent to which the classification of text corresponds to a standard or norm statistically.
Validity : Three criteria comprise the validity of a content analysis:
Closeness of categories: this can be achieved by utilizing multiple classifiers to arrive at an agreed upon definition of each specific category. Using multiple classifiers, a concept category that may be an explicit variable can be broadened to include synonyms or implicit variables.
Conclusions: What level of implication is allowable? Do conclusions correctly follow the data? Are results explainable by other phenomena? This becomes especially problematic when using computer software for analysis and distinguishing between synonyms. For example, the word “mine,” variously denotes a personal pronoun, an explosive device, and a deep hole in the ground from which ore is extracted. Software can obtain an accurate count of that word’s occurrence and frequency, but not be able to produce an accurate accounting of the meaning inherent in each particular usage. This problem could throw off one’s results and make any conclusion invalid.
Generalizability of the results to a theory: dependent on the clear definitions of concept categories, how they are determined and how reliable they are at measuring the idea one is seeking to measure. Generalizability parallels reliability as much of it depends on the three criteria for reliability.
Advantages of Content Analysis
Directly examines communication using text
Allows for both qualitative and quantitative analysis
Provides valuable historical and cultural insights over time
Allows a closeness to data
Coded form of the text can be statistically analyzed
Unobtrusive means of analyzing interactions
Provides insight into complex models of human thought and language use
When done well, is considered a relatively “exact” research method
Content analysis is a readily-understood and an inexpensive research method
A more powerful tool when combined with other research methods such as interviews, observation, and use of archival records. It is very useful for analyzing historical material, especially for documenting trends over time.
Disadvantages of Content Analysis
Can be extremely time consuming
Is subject to increased error, particularly when relational analysis is used to attain a higher level of interpretation
Is often devoid of theoretical base, or attempts too liberally to draw meaningful inferences about the relationships and impacts implied in a study
Is inherently reductive, particularly when dealing with complex texts
Tends too often to simply consist of word counts
Often disregards the context that produced the text, as well as the state of things after the text is produced
Can be difficult to automate or computerize
Textbooks & Chapters
Berelson, Bernard. Content Analysis in Communication Research.New York: Free Press, 1952.
Busha, Charles H. and Stephen P. Harter. Research Methods in Librarianship: Techniques and Interpretation.New York: Academic Press, 1980.
de Sola Pool, Ithiel. Trends in Content Analysis. Urbana: University of Illinois Press, 1959.
Krippendorff, Klaus. Content Analysis: An Introduction to its Methodology. Beverly Hills: Sage Publications, 1980.
Fielding, NG & Lee, RM. Using Computers in Qualitative Research. SAGE Publications, 1991. (Refer to Chapter by Seidel, J. ‘Method and Madness in the Application of Computer Technology to Qualitative Data Analysis’.)
Methodological Articles
Hsieh HF & Shannon SE. (2005). Three Approaches to Qualitative Content Analysis.Qualitative Health Research. 15(9): 1277-1288.
Elo S, Kaarianinen M, Kanste O, Polkki R, Utriainen K, & Kyngas H. (2014). Qualitative Content Analysis: A focus on trustworthiness. Sage Open. 4:1-10.
Application Articles
Abroms LC, Padmanabhan N, Thaweethai L, & Phillips T. (2011). iPhone Apps for Smoking Cessation: A content analysis. American Journal of Preventive Medicine. 40(3):279-285.
Ullstrom S. Sachs MA, Hansson J, Ovretveit J, & Brommels M. (2014). Suffering in Silence: a qualitative study of second victims of adverse events. British Medical Journal, Quality & Safety Issue. 23:325-331.
Owen P. (2012).Portrayals of Schizophrenia by Entertainment Media: A Content Analysis of Contemporary Movies. Psychiatric Services. 63:655-659.
Choosing whether to conduct a content analysis by hand or by using computer software can be difficult. Refer to ‘Method and Madness in the Application of Computer Technology to Qualitative Data Analysis’ listed above in “Textbooks and Chapters” for a discussion of the issue.
QSR NVivo: http://www.qsrinternational.com/products.aspx
Atlas.ti: http://www.atlasti.com/webinars.html
R- RQDA package: http://rqda.r-forge.r-project.org/
Rolly Constable, Marla Cowell, Sarita Zornek Crawford, David Golden, Jake Hartvigsen, Kathryn Morgan, Anne Mudgett, Kris Parrish, Laura Thomas, Erika Yolanda Thompson, Rosie Turner, and Mike Palmquist. (1994-2012). Ethnography, Observational Research, and Narrative Inquiry. Writing@CSU. Colorado State University. Available at: https://writing.colostate.edu/guides/guide.cfm?guideid=63 .
As an introduction to Content Analysis by Michael Palmquist, this is the main resource on Content Analysis on the Web. It is comprehensive, yet succinct. It includes examples and an annotated bibliography. The information contained in the narrative above draws heavily from and summarizes Michael Palmquist’s excellent resource on Content Analysis but was streamlined for the purpose of doctoral students and junior researchers in epidemiology.
At Columbia University Mailman School of Public Health, more detailed training is available through the Department of Sociomedical Sciences- P8785 Qualitative Research Methods.
Join the Conversation
Have a question about methods? Join us on Facebook

The Ultimate Guide to Qualitative Research - Part 2: Handling Qualitative Data

- Handling qualitative data
- Transcripts
- Field notes
- Survey data and responses
- Visual and audio data
- Data organization
- Data coding
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Introduction
What is meant by content analysis?
Quantitative content analysis, practical examples of quantitative content analysis, using atlas.ti for content analysis.
- Thematic analysis
- Thematic analysis vs. content analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
- Qualitative data interpretation
- Qualitative analysis software
Content analysis
Qualitative data collection usually leads to a strictly qualitative data analysis , but that need not always be the case. If a required analysis involves quantifying data , there are a number of data organization and data analysis methods that might be helpful in giving structure to raw data for frequency or statistical analysis.

This part of the guide will explore the idea of quantitative content analysis. Where quantitative analysis is useful, there are tools in qualitative data analysis software like ATLAS.ti that can reorganize your data for a content analysis that can supplement your use of qualitative research methods. Let's explore content analysis by providing a brief overview of this approach, then by looking at the quantitative aspects of content analysis.
Content analysis, in its simplest form, is a research method for interpreting and quantifying textual data , such as speeches, interviews , articles, social media posts , and so on. It allows researchers to sift through large volumes of data to identify patterns, themes, or biases and turn these into quantifiable variables that can be further analyzed.
At its core, content analysis combines elements of both qualitative and quantitative research methods . The method itself is systematic and replicable, aiming to condense a significant amount of text into fewer content categories based on explicit rules of coding. Yet, the interpretive component of understanding the context, nuances, and underlying meanings of the content being analyzed remains essential, borrowing heavily from qualitative research traditions.
This flexibility makes content analysis a versatile research approach applicable to numerous disciplines, such as communication, marketing, sociology, psychology, and political science, among others. Its uses range from studying cultural shifts over time, media representation of specific groups, political speeches, sentiments expressed in social media, and much more.
Differences from other research methods
The uniqueness of content analysis primarily stems from its ability to convert qualitative textual data into quantitative data , which can then be systematically examined. This capability sets it apart from many other research methodologies, each of which has its strengths and weaknesses.
Content analysis offers a less intrusive way of understanding a subject matter or phenomenon than more interpretive approaches. Unlike with an ethnographic or observational approach , there's no direct involvement with the study's subjects. Instead, the researcher examines texts and communications to uncover patterns, themes, or biases. This can be especially advantageous when researching sensitive topics or populations that are difficult to access.
Contrasting with quantitative methods associated with surveys and experiments, content analysis allows for a more contextual and nuanced understanding of data. While surveys and experiments can yield numerical data about attitudes, behaviors, and opinions, they often lack depth and fail to capture the richness of subjective experiences. Content analysis, on the other hand, provides more depth by enabling the researcher to delve into the intricacies of language and communication.
In comparison to discourse analysis , another method for studying a text, content analysis is more focused on the manifest content - the actual text - rather than the underlying discourses or power dynamics. Discourse analysis typically explores the relationships between text, context, and societal structures.
Lastly, unlike thematic analysis, which identifies, analyzes, and reports themes within data, content analysis goes a step further by transforming these themes into measurable variables. This quantification allows researchers to perform statistical analyses, giving content analysis an edge in examining the relationships between variables.
In essence, content analysis straddles the line between qualitative and quantitative methodologies, extracting the best of both worlds. It allows researchers to maintain the depth and richness of qualitative data while taking advantage of the numerical robustness of quantitative analysis. This makes content analysis a valuable addition to the researcher's toolkit.
Advantages of content analysis
Content analysis offers several advantages that make it a valuable tool for researchers in various disciplines. These advantages extend across its methodological flexibility, analytical depth, and practical adaptability.
- Methodological flexibility : Content analysis allows for both qualitative and quantitative research, enabling researchers to explore themes in-depth while also making quantifiable comparisons. It's a versatile method, adaptable to a variety of research questions and data sources.
- Rich, in-depth analysis : Content analysis provides a rich, textured understanding of data. Coding and categorizing allow researchers to delve into the complexities of language and communication, exploring nuanced meanings and connotations.
- Unobtrusive method : As content analysis involves studying existing texts and communications, it is an unobtrusive method that does not require interaction with research participants. This can make it an excellent choice for sensitive research topics.
- Ability to handle large data sets : Content analysis can manage large volumes of textual data, making it suitable for studies involving extensive texts or long timeframes. As we will see later in this section, the coding process in a content analysis approach can thus be relatively more straightforward.
- Replicability : The systematic nature of content analysis lends itself to replicability. By creating explicit rules for coding and categorizing, other researchers can reproduce the study, enhancing its reliability.
- Longitudinal analysis : Content analysis allows for longitudinal studies , as it can examine texts and communication over extended periods. This ability can be invaluable for tracking changes and trends over time.
- Cost-effective : Compared to many other research methods , content analysis can be a cost-effective approach. Since it primarily involves analyzing existing texts, it often requires fewer resources than methods involving primary data collection .
The flexibility, depth, and practicality of content analysis make it a powerful tool for answering a range of research questions. Despite some limitations, which we will explore in the next section, the advantages of content analysis often make it an appealing choice for researchers.
Disadvantages of content analysis
While content analysis is a valuable tool, it's essential to acknowledge its limitations. These include:
- Dependence on the quality of source materials : Content analysis relies on the quality of the source materials. If the documents or texts used for analysis are biased, incomplete, or inaccurate, it can lead to skewed results.
- Contextual understanding : Texts often derive their meaning from context. Isolating texts for analysis can sometimes result in the loss of crucial contextual information, which may affect the overall interpretation of the results.
- Coding and categorization limitations: The process of coding and categorizing can be time-consuming and prone to bias or error, potentially affecting the reliability and validity of the results.
- Lack of depth compared to other qualitative methods : While content analysis allows for in-depth analysis, it may not reach the same level of depth as methods such as interviews or participant observations, particularly when exploring participants' feelings, thoughts, or motivations.
- Difficulty in establishing causality : Content analysis can identify patterns and associations in the data but establishing causality can be challenging due to its primarily descriptive nature. As a result, conducting conceptual and relational analysis can prove challenging.
- Focus on manifest content : Content analysis typically focuses on manifest content - the visible, surface content. Latent content, which refers to the underlying meanings or connotations, can sometimes be overlooked, limiting the depth of analysis.
Despite these limitations, with careful consideration and thoughtful application, content analysis remains a useful method. Understanding its potential drawbacks helps researchers apply the method more effectively and interpret their findings with due consideration. The next section will introduce qualitative content analysis, a specific type of content analysis that, while sharing some of the limitations mentioned here, offers unique advantages of its own.
What is qualitative content analysis?
Qualitative content analysis is a specific type of content analysis that primarily focuses on the interpretation and understanding of textual data. While it shares some similarities with its quantitative counterpart—such as the use of systematic and replicable methods—qualitative content analysis tends to dive deeper into the nuances, meanings, and contexts of the data.
At the heart of a qualitative analysis is the process of categorizing and coding data to identify patterns, themes, and relationships. The categories are usually derived inductively—that is, they emerge from the data itself rather than being pre-established. This approach offers a higher degree of flexibility and is especially beneficial when exploring a new or under-researched area.
An excellent example of the application of qualitative content analysis can be seen in qualitative health research. Consider a study examining patients' experiences with a chronic disease, such as diabetes. Here, qualitative content analysis would not only identify and categorize themes related to the disease experience, such as challenges in managing the condition, the impact on daily life, or interactions with healthcare professionals. It could also delve into the patients' psychological or emotional state regarding the management of their condition, as well as their attitudinal and behavioral responses to their condition and the healthcare system. For instance, the analysis might uncover feelings of frustration or resignation, proactive strategies for disease management, or attitudes toward healthcare advice.
Another distinctive characteristic of qualitative content analysis is its emphasis on context. Rather than viewing data in isolation, it considers the broader context in which the communication occurs. It takes into account aspects like the social, cultural, and historical background, the intention of the speaker, and the perception of the audience. This contextual understanding provides a richer, more nuanced analysis.
Also noteworthy is the iterative nature of qualitative content analysis. The process of coding, categorizing, and interpreting the data is not linear but recursive. As the analysis progresses, the researcher may revise the coding scheme, refine categories, and re-interpret the data, gradually enhancing the depth and precision of the analysis.
While qualitative content analysis provides an in-depth understanding of textual data, it can be more time-consuming and require more interpretative skill than quantitative content analysis. However, as we will explore in the next sections, both methods have their unique strengths and can complement each other in providing a comprehensive understanding of the data.
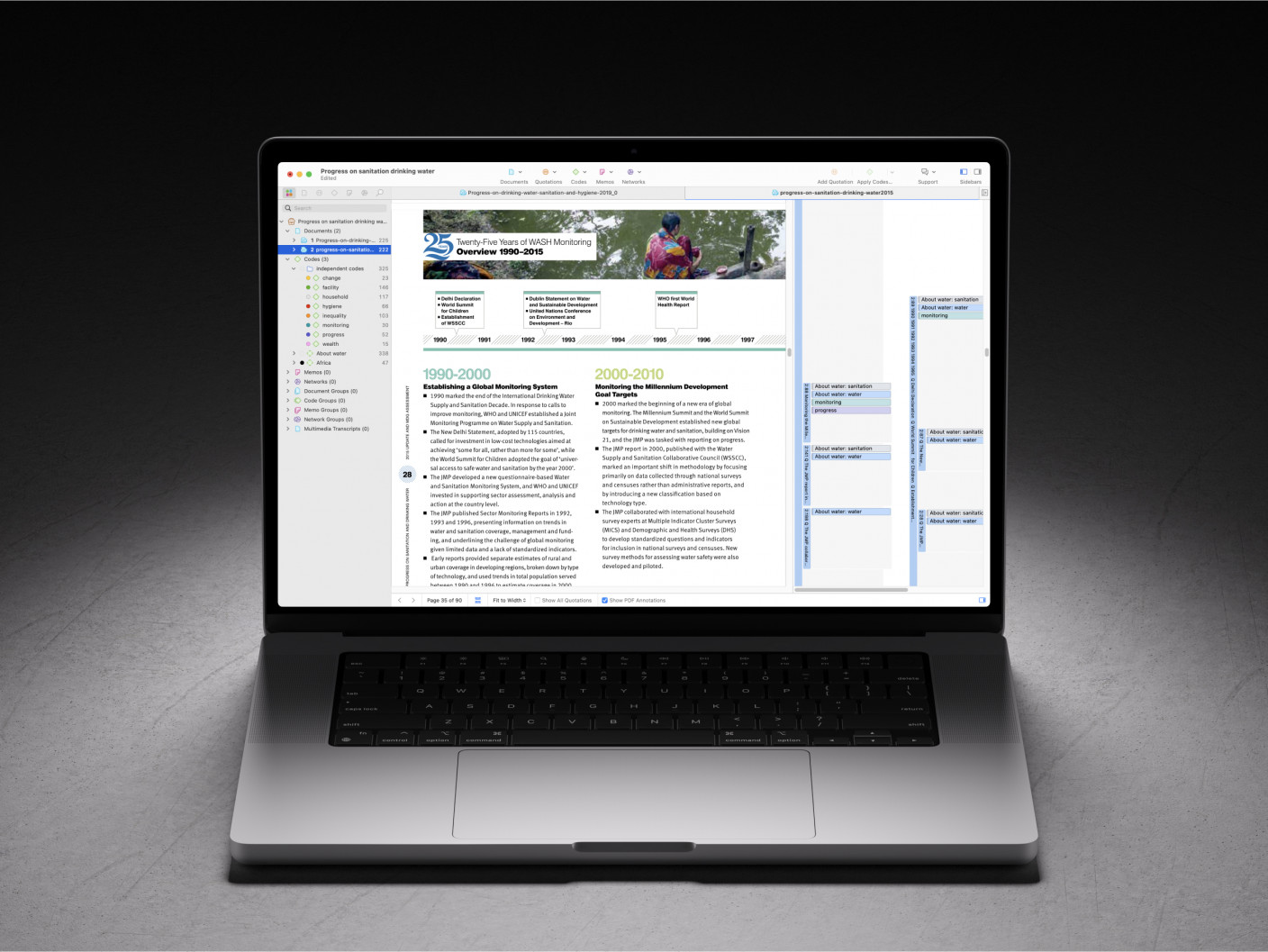
Textual analysis made easy with ATLAS.ti
Get the deepest insights through analysis with ATLAS.ti. Download a free trial today.
Having explored content analysis in its broad scope and delved into qualitative analysis methods behind content analysis, we now shift our focus to quantitative content analysis. This approach retains the systematic, objective nature of content analysis but introduces a more numerical, count-based method of analyzing textual data . As such, it stands at the intersection of qualitative and quantitative research paradigms, offering the opportunity to transform the same data used in a qualitative analysis into a form that can be statistically analyzed.
In the subsequent subsections, we will define this research technique, detail the steps involved in its implementation, discuss its benefits and limitations, and illustrate its practical application with some examples. By the end of this section, you should have a solid understanding of quantitative content analysis and its role in your research toolkit.
Defining quantitative content analysis
This research approach, also known as deductive or 'classical' content analysis, is used to quantify patterns in textual data. This approach systematically transforms a text into numerical data, allowing for statistical analysis. This means that the content is categorized and counted to provide an objective, quantifiable overview of its characteristics.
Quantitative content analysis is predominantly concerned with manifest content—the visible, obvious components of the text. It examines what the text explicitly says rather than delving into possible latent meanings or underlying connotations. The text's elements—such as words, phrases, sentences, or specific themes—are coded into predefined categories, and the frequency of these categories is then quantified. This quantification allows for a more precise and broad-scale analysis of the data.
It's important to note that while quantification is a fundamental aspect of this approach, quantitative analysis still involves an element of interpretation. For instance, the development of coding schemes and the categorization of data require the researcher to understand and interpret the content. As such, even though it's labeled as 'quantitative,' this approach maintains a crucial qualitative component.
Despite this, the predominant focus of a quantitative approach is on the numerical, allowing it to provide a structured, replicable, and count-based exploration of textual data. The value of this approach lies in its ability to deliver an empirical, data-driven understanding of the content, enabling researchers to make statistical inferences and comparisons. In the next subsection, we will discuss the steps involved in conducting quantitative content analysis.
Steps in conducting quantitative analysis
The process typically involves several key steps:
- Define the research question : The research question should be suitable for a quantitative approach. It should examine the frequency or patterns of certain aspects in a body of text.
- Select the sample : Based on the research question, decide what texts to analyze. The texts could be anything from newspaper articles, social media posts , and speeches to transcripts of interviews or focus groups . Make sure to define a clear and replicable strategy for sample selection.
- Define categories and develop a coding scheme : This step involves identifying the aspects of the text you are interested in and developing a set of categories to classify these aspects. Each category should be clearly defined, mutually exclusive, and collectively exhaustive.
- Pilot-test the coding scheme : Before you start the actual analysis, it is advisable to pilot-test the coding scheme on a smaller subset of the sample. This helps ensure that your categories cover all relevant aspects of the content and that the coding scheme is reliable.
- Code the content : In this step, the selected content is coded according to the coding scheme. Each part of the content that corresponds to a category is counted as a 'unit.' The units could be individual words, phrases, sentences, paragraphs, or even entire documents, depending on the research question and the nature of the categories.
- Analyze and interpret the data : The coded data is then analyzed, often using statistical methods. You can calculate the frequencies of each category, compare frequencies between different parts of the text or different texts, or examine the relationships between categories. The analysis should be linked back to the research question and the wider context of the research.
- Present the findings : Finally, the findings are reported in a clear and comprehensible manner, often using tables or graphs to display the frequencies of categories. It's also important to discuss the findings in the context of the research question and existing literature.
These steps provide a general framework for conducting quantitative content analysis. However, depending on the specifics of your research project, you may need to adapt or expand on these steps. For instance, if your research involves a large volume of text or multiple coders, you may need to include additional steps to ensure the consistency and reliability of the coding process.
With the process outlined above, here are a few practical examples illustrating a quantitative application of content analysis.
One common application of quantitative content analysis is in media studies. For instance, a researcher might use it to examine the representation of gender roles in a sample of popular movies. The researcher could define a set of categories reflecting different aspects of gender representation, such as the occupation, behaviors, or speech of male and female characters. By coding and quantifying these categories, the researcher could provide an empirical, data-driven analysis of gender representation in movies.
In political science, a researcher might use quantitative content analysis to analyze politicians' speeches. For example, they could examine the frequency of certain themes or keywords to gain insights into a politician's focus areas or ideological leanings. This approach allows for a systematic, objective assessment of political communication.
In health research, quantitative content analysis could be used to analyze patient reviews of healthcare providers. Categories could be developed to capture aspects like the quality of care, communication skills, waiting times, etc. By coding and quantifying these categories, the researcher could identify patterns and trends in patient satisfaction.
These examples illustrate the breadth of applications for quantitative content analysis. Whether you're exploring social issues, political discourses, customer reviews, or any other type of textual data, quantitative content analysis provides a method for systematically coding, categorizing, and quantifying your data. By offering a way to transform qualitative data into a form that can be statistically analyzed, it adds a valuable tool to your research toolkit.
ATLAS.ti is particularly useful to researchers who want to conduct content analysis from both quantitative and qualitative approaches . For research inquiries that rely more on interpretation to identify patterns and abundance in the data, then thematic analysis may be more appropriate for your study.
On the other hand, when you are relying on counting words or phrases to determine key insights, a quantitative approach to content analysis will be a useful component of your study's methodology. To facilitate your analysis, a number of tools in ATLAS.ti will provide you with the ability to conduct a quantitative inquiry.
Word Frequencies and Concepts
A word cloud is a common but meaningful visualization in qualitative research , as it shows what words appear more often than others. The greater the frequency of a word, the closer to the center of the cloud that word is placed. While a word cloud relies on statistics, it presents the analysis in a visual manner that allows your research audience to quickly grasp the meaning.
ATLAS.ti's Word Cloud tool determines the frequencies and creates the visualization quickly and easily. All the researcher needs to do is select the documents they want to analyze. They can then refine their word cloud by including or excluding certain classes of words, such as adverbs or determiners, or by setting a required minimum frequency for the word to appear in the cloud.
The Concepts tool works similarly to Word Clouds, except it relies on collocations of words to determine which phrases are more prevalent in your data than others.
Once the researcher selects the data they want to analyze, the words included in the most common concepts will appear in a visualization resembling a word cloud. Hovering over any of these words will show which phrases are relevant to that word and where those phrases can be found in the data. This allows the researcher to look at the phrase in context and add codes as necessary.
Text Search
Most people are familiar with a text search function in a word processor or a web browser. ATLAS.ti's Text Search tool has a similar search capability but also employs language models developed through machine learning to help you expand your search quickly and efficiently.
When entering a word to search, the researcher can also choose from a list of synonyms they can include in their search. In research on sustainability, for example, the words "preserve" and "save" might be similar enough to be included in one inquiry. As a result, ATLAS.ti allows the researcher to choose related words relevant to their search.
Searching for inflected forms is also important to a quantitative approach to content analysis. Given that "preserves," "preserving," and "preservation" all come from the word "preserve," it's only appropriate to include them in one search. The option in ATLAS.ti to search for inflected forms makes it easy to search the data for all possible versions of a word. And in Text Search, all results can be easily coded so those codes can be used in content analysis.
Insightful content analysis with ATLAS.ti
Download a free trial of ATLAS.ti to get the most out of your data.
- Search Menu
- Browse content in Arts and Humanities
- Browse content in Archaeology
- Anglo-Saxon and Medieval Archaeology
- Archaeological Methodology and Techniques
- Archaeology by Region
- Archaeology of Religion
- Archaeology of Trade and Exchange
- Biblical Archaeology
- Contemporary and Public Archaeology
- Environmental Archaeology
- Historical Archaeology
- History and Theory of Archaeology
- Industrial Archaeology
- Landscape Archaeology
- Mortuary Archaeology
- Prehistoric Archaeology
- Underwater Archaeology
- Urban Archaeology
- Zooarchaeology
- Browse content in Architecture
- Architectural Structure and Design
- History of Architecture
- Residential and Domestic Buildings
- Theory of Architecture
- Browse content in Art
- Art Subjects and Themes
- History of Art
- Industrial and Commercial Art
- Theory of Art
- Biographical Studies
- Byzantine Studies
- Browse content in Classical Studies
- Classical Literature
- Classical Reception
- Classical History
- Classical Philosophy
- Classical Mythology
- Classical Art and Architecture
- Classical Oratory and Rhetoric
- Greek and Roman Archaeology
- Greek and Roman Papyrology
- Greek and Roman Epigraphy
- Greek and Roman Law
- Late Antiquity
- Religion in the Ancient World
- Digital Humanities
- Browse content in History
- Colonialism and Imperialism
- Diplomatic History
- Environmental History
- Genealogy, Heraldry, Names, and Honours
- Genocide and Ethnic Cleansing
- Historical Geography
- History by Period
- History of Agriculture
- History of Education
- History of Emotions
- History of Gender and Sexuality
- Industrial History
- Intellectual History
- International History
- Labour History
- Legal and Constitutional History
- Local and Family History
- Maritime History
- Military History
- National Liberation and Post-Colonialism
- Oral History
- Political History
- Public History
- Regional and National History
- Revolutions and Rebellions
- Slavery and Abolition of Slavery
- Social and Cultural History
- Theory, Methods, and Historiography
- Urban History
- World History
- Browse content in Language Teaching and Learning
- Language Learning (Specific Skills)
- Language Teaching Theory and Methods
- Browse content in Linguistics
- Applied Linguistics
- Cognitive Linguistics
- Computational Linguistics
- Forensic Linguistics
- Grammar, Syntax and Morphology
- Historical and Diachronic Linguistics
- History of English
- Language Variation
- Language Families
- Language Evolution
- Language Reference
- Language Acquisition
- Lexicography
- Linguistic Theories
- Linguistic Typology
- Linguistic Anthropology
- Phonetics and Phonology
- Psycholinguistics
- Sociolinguistics
- Translation and Interpretation
- Writing Systems
- Browse content in Literature
- Bibliography
- Children's Literature Studies
- Literary Studies (Modernism)
- Literary Studies (Romanticism)
- Literary Studies (American)
- Literary Studies (Asian)
- Literary Studies (European)
- Literary Studies (Eco-criticism)
- Literary Studies - World
- Literary Studies (1500 to 1800)
- Literary Studies (19th Century)
- Literary Studies (20th Century onwards)
- Literary Studies (African American Literature)
- Literary Studies (British and Irish)
- Literary Studies (Early and Medieval)
- Literary Studies (Fiction, Novelists, and Prose Writers)
- Literary Studies (Gender Studies)
- Literary Studies (Graphic Novels)
- Literary Studies (History of the Book)
- Literary Studies (Plays and Playwrights)
- Literary Studies (Poetry and Poets)
- Literary Studies (Postcolonial Literature)
- Literary Studies (Queer Studies)
- Literary Studies (Science Fiction)
- Literary Studies (Travel Literature)
- Literary Studies (War Literature)
- Literary Studies (Women's Writing)
- Literary Theory and Cultural Studies
- Mythology and Folklore
- Shakespeare Studies and Criticism
- Browse content in Media Studies
- Browse content in Music
- Applied Music
- Dance and Music
- Ethics in Music
- Ethnomusicology
- Gender and Sexuality in Music
- Medicine and Music
- Music Cultures
- Music and Culture
- Music and Media
- Music and Religion
- Music Education and Pedagogy
- Music Theory and Analysis
- Musical Scores, Lyrics, and Libretti
- Musical Structures, Styles, and Techniques
- Musicology and Music History
- Performance Practice and Studies
- Race and Ethnicity in Music
- Sound Studies
- Browse content in Performing Arts
- Browse content in Philosophy
- Aesthetics and Philosophy of Art
- Epistemology
- Feminist Philosophy
- History of Western Philosophy
- Metaphysics
- Moral Philosophy
- Non-Western Philosophy
- Philosophy of Action
- Philosophy of Law
- Philosophy of Religion
- Philosophy of Language
- Philosophy of Mind
- Philosophy of Perception
- Philosophy of Science
- Philosophy of Mathematics and Logic
- Practical Ethics
- Social and Political Philosophy
- Browse content in Religion
- Biblical Studies
- Christianity
- East Asian Religions
- History of Religion
- Judaism and Jewish Studies
- Qumran Studies
- Religion and Education
- Religion and Health
- Religion and Politics
- Religion and Science
- Religion and Law
- Religion and Art, Literature, and Music
- Religious Studies
- Browse content in Society and Culture
- Cookery, Food, and Drink
- Cultural Studies
- Customs and Traditions
- Ethical Issues and Debates
- Hobbies, Games, Arts and Crafts
- Lifestyle, Home, and Garden
- Natural world, Country Life, and Pets
- Popular Beliefs and Controversial Knowledge
- Sports and Outdoor Recreation
- Technology and Society
- Travel and Holiday
- Visual Culture
- Browse content in Law
- Arbitration
- Browse content in Company and Commercial Law
- Commercial Law
- Company Law
- Browse content in Comparative Law
- Systems of Law
- Competition Law
- Browse content in Constitutional and Administrative Law
- Government Powers
- Judicial Review
- Local Government Law
- Military and Defence Law
- Parliamentary and Legislative Practice
- Construction Law
- Contract Law
- Browse content in Criminal Law
- Criminal Procedure
- Criminal Evidence Law
- Sentencing and Punishment
- Employment and Labour Law
- Environment and Energy Law
- Browse content in Financial Law
- Banking Law
- Insolvency Law
- History of Law
- Human Rights and Immigration
- Intellectual Property Law
- Browse content in International Law
- Private International Law and Conflict of Laws
- Public International Law
- IT and Communications Law
- Jurisprudence and Philosophy of Law
- Law and Society
- Law and Politics
- Browse content in Legal System and Practice
- Courts and Procedure
- Legal Skills and Practice
- Primary Sources of Law
- Regulation of Legal Profession
- Medical and Healthcare Law
- Browse content in Policing
- Criminal Investigation and Detection
- Police and Security Services
- Police Procedure and Law
- Police Regional Planning
- Browse content in Property Law
- Personal Property Law
- Study and Revision
- Terrorism and National Security Law
- Browse content in Trusts Law
- Wills and Probate or Succession
- Browse content in Medicine and Health
- Browse content in Allied Health Professions
- Arts Therapies
- Clinical Science
- Dietetics and Nutrition
- Occupational Therapy
- Operating Department Practice
- Physiotherapy
- Radiography
- Speech and Language Therapy
- Browse content in Anaesthetics
- General Anaesthesia
- Neuroanaesthesia
- Clinical Neuroscience
- Browse content in Clinical Medicine
- Acute Medicine
- Cardiovascular Medicine
- Clinical Genetics
- Clinical Pharmacology and Therapeutics
- Dermatology
- Endocrinology and Diabetes
- Gastroenterology
- Genito-urinary Medicine
- Geriatric Medicine
- Infectious Diseases
- Medical Oncology
- Medical Toxicology
- Pain Medicine
- Palliative Medicine
- Rehabilitation Medicine
- Respiratory Medicine and Pulmonology
- Rheumatology
- Sleep Medicine
- Sports and Exercise Medicine
- Community Medical Services
- Critical Care
- Emergency Medicine
- Forensic Medicine
- Haematology
- History of Medicine
- Medical Ethics
- Browse content in Medical Skills
- Clinical Skills
- Communication Skills
- Nursing Skills
- Surgical Skills
- Browse content in Medical Dentistry
- Oral and Maxillofacial Surgery
- Paediatric Dentistry
- Restorative Dentistry and Orthodontics
- Surgical Dentistry
- Medical Statistics and Methodology
- Browse content in Neurology
- Clinical Neurophysiology
- Neuropathology
- Nursing Studies
- Browse content in Obstetrics and Gynaecology
- Gynaecology
- Occupational Medicine
- Ophthalmology
- Otolaryngology (ENT)
- Browse content in Paediatrics
- Neonatology
- Browse content in Pathology
- Chemical Pathology
- Clinical Cytogenetics and Molecular Genetics
- Histopathology
- Medical Microbiology and Virology
- Patient Education and Information
- Browse content in Pharmacology
- Psychopharmacology
- Browse content in Popular Health
- Caring for Others
- Complementary and Alternative Medicine
- Self-help and Personal Development
- Browse content in Preclinical Medicine
- Cell Biology
- Molecular Biology and Genetics
- Reproduction, Growth and Development
- Primary Care
- Professional Development in Medicine
- Browse content in Psychiatry
- Addiction Medicine
- Child and Adolescent Psychiatry
- Forensic Psychiatry
- Learning Disabilities
- Old Age Psychiatry
- Psychotherapy
- Browse content in Public Health and Epidemiology
- Epidemiology
- Public Health
- Browse content in Radiology
- Clinical Radiology
- Interventional Radiology
- Nuclear Medicine
- Radiation Oncology
- Reproductive Medicine
- Browse content in Surgery
- Cardiothoracic Surgery
- Gastro-intestinal and Colorectal Surgery
- General Surgery
- Neurosurgery
- Paediatric Surgery
- Peri-operative Care
- Plastic and Reconstructive Surgery
- Surgical Oncology
- Transplant Surgery
- Trauma and Orthopaedic Surgery
- Vascular Surgery
- Browse content in Science and Mathematics
- Browse content in Biological Sciences
- Aquatic Biology
- Biochemistry
- Bioinformatics and Computational Biology
- Developmental Biology
- Ecology and Conservation
- Evolutionary Biology
- Genetics and Genomics
- Microbiology
- Molecular and Cell Biology
- Natural History
- Plant Sciences and Forestry
- Research Methods in Life Sciences
- Structural Biology
- Systems Biology
- Zoology and Animal Sciences
- Browse content in Chemistry
- Analytical Chemistry
- Computational Chemistry
- Crystallography
- Environmental Chemistry
- Industrial Chemistry
- Inorganic Chemistry
- Materials Chemistry
- Medicinal Chemistry
- Mineralogy and Gems
- Organic Chemistry
- Physical Chemistry
- Polymer Chemistry
- Study and Communication Skills in Chemistry
- Theoretical Chemistry
- Browse content in Computer Science
- Artificial Intelligence
- Computer Architecture and Logic Design
- Game Studies
- Human-Computer Interaction
- Mathematical Theory of Computation
- Programming Languages
- Software Engineering
- Systems Analysis and Design
- Virtual Reality
- Browse content in Computing
- Business Applications
- Computer Games
- Computer Security
- Computer Networking and Communications
- Digital Lifestyle
- Graphical and Digital Media Applications
- Operating Systems
- Browse content in Earth Sciences and Geography
- Atmospheric Sciences
- Environmental Geography
- Geology and the Lithosphere
- Maps and Map-making
- Meteorology and Climatology
- Oceanography and Hydrology
- Palaeontology
- Physical Geography and Topography
- Regional Geography
- Soil Science
- Urban Geography
- Browse content in Engineering and Technology
- Agriculture and Farming
- Biological Engineering
- Civil Engineering, Surveying, and Building
- Electronics and Communications Engineering
- Energy Technology
- Engineering (General)
- Environmental Science, Engineering, and Technology
- History of Engineering and Technology
- Mechanical Engineering and Materials
- Technology of Industrial Chemistry
- Transport Technology and Trades
- Browse content in Environmental Science
- Applied Ecology (Environmental Science)
- Conservation of the Environment (Environmental Science)
- Environmental Sustainability
- Environmentalist Thought and Ideology (Environmental Science)
- Management of Land and Natural Resources (Environmental Science)
- Natural Disasters (Environmental Science)
- Nuclear Issues (Environmental Science)
- Pollution and Threats to the Environment (Environmental Science)
- Social Impact of Environmental Issues (Environmental Science)
- History of Science and Technology
- Browse content in Materials Science
- Ceramics and Glasses
- Composite Materials
- Metals, Alloying, and Corrosion
- Nanotechnology
- Browse content in Mathematics
- Applied Mathematics
- Biomathematics and Statistics
- History of Mathematics
- Mathematical Education
- Mathematical Finance
- Mathematical Analysis
- Numerical and Computational Mathematics
- Probability and Statistics
- Pure Mathematics
- Browse content in Neuroscience
- Cognition and Behavioural Neuroscience
- Development of the Nervous System
- Disorders of the Nervous System
- History of Neuroscience
- Invertebrate Neurobiology
- Molecular and Cellular Systems
- Neuroendocrinology and Autonomic Nervous System
- Neuroscientific Techniques
- Sensory and Motor Systems
- Browse content in Physics
- Astronomy and Astrophysics
- Atomic, Molecular, and Optical Physics
- Biological and Medical Physics
- Classical Mechanics
- Computational Physics
- Condensed Matter Physics
- Electromagnetism, Optics, and Acoustics
- History of Physics
- Mathematical and Statistical Physics
- Measurement Science
- Nuclear Physics
- Particles and Fields
- Plasma Physics
- Quantum Physics
- Relativity and Gravitation
- Semiconductor and Mesoscopic Physics
- Browse content in Psychology
- Affective Sciences
- Clinical Psychology
- Cognitive Neuroscience
- Cognitive Psychology
- Criminal and Forensic Psychology
- Developmental Psychology
- Educational Psychology
- Evolutionary Psychology
- Health Psychology
- History and Systems in Psychology
- Music Psychology
- Neuropsychology
- Organizational Psychology
- Psychological Assessment and Testing
- Psychology of Human-Technology Interaction
- Psychology Professional Development and Training
- Research Methods in Psychology
- Social Psychology
- Browse content in Social Sciences
- Browse content in Anthropology
- Anthropology of Religion
- Human Evolution
- Medical Anthropology
- Physical Anthropology
- Regional Anthropology
- Social and Cultural Anthropology
- Theory and Practice of Anthropology
- Browse content in Business and Management
- Business History
- Business Ethics
- Business Strategy
- Business and Technology
- Business and Government
- Business and the Environment
- Comparative Management
- Corporate Governance
- Corporate Social Responsibility
- Entrepreneurship
- Health Management
- Human Resource Management
- Industrial and Employment Relations
- Industry Studies
- Information and Communication Technologies
- International Business
- Knowledge Management
- Management and Management Techniques
- Operations Management
- Organizational Theory and Behaviour
- Pensions and Pension Management
- Public and Nonprofit Management
- Strategic Management
- Supply Chain Management
- Browse content in Criminology and Criminal Justice
- Criminal Justice
- Criminology
- Forms of Crime
- International and Comparative Criminology
- Youth Violence and Juvenile Justice
- Development Studies
- Browse content in Economics
- Agricultural, Environmental, and Natural Resource Economics
- Asian Economics
- Behavioural Finance
- Behavioural Economics and Neuroeconomics
- Econometrics and Mathematical Economics
- Economic Methodology
- Economic History
- Economic Systems
- Economic Development and Growth
- Financial Markets
- Financial Institutions and Services
- General Economics and Teaching
- Health, Education, and Welfare
- History of Economic Thought
- International Economics
- Labour and Demographic Economics
- Law and Economics
- Macroeconomics and Monetary Economics
- Microeconomics
- Public Economics
- Urban, Rural, and Regional Economics
- Welfare Economics
- Browse content in Education
- Adult Education and Continuous Learning
- Care and Counselling of Students
- Early Childhood and Elementary Education
- Educational Equipment and Technology
- Educational Strategies and Policy
- Higher and Further Education
- Organization and Management of Education
- Philosophy and Theory of Education
- Schools Studies
- Secondary Education
- Teaching of a Specific Subject
- Teaching of Specific Groups and Special Educational Needs
- Teaching Skills and Techniques
- Browse content in Environment
- Applied Ecology (Social Science)
- Climate Change
- Conservation of the Environment (Social Science)
- Environmentalist Thought and Ideology (Social Science)
- Natural Disasters (Environment)
- Social Impact of Environmental Issues (Social Science)
- Browse content in Human Geography
- Cultural Geography
- Economic Geography
- Political Geography
- Browse content in Interdisciplinary Studies
- Communication Studies
- Museums, Libraries, and Information Sciences
- Browse content in Politics
- African Politics
- Asian Politics
- Chinese Politics
- Comparative Politics
- Conflict Politics
- Elections and Electoral Studies
- Environmental Politics
- European Union
- Foreign Policy
- Gender and Politics
- Human Rights and Politics
- Indian Politics
- International Relations
- International Organization (Politics)
- International Political Economy
- Irish Politics
- Latin American Politics
- Middle Eastern Politics
- Political Theory
- Political Behaviour
- Political Economy
- Political Institutions
- Political Methodology
- Political Communication
- Political Philosophy
- Political Sociology
- Politics and Law
- Public Policy
- Public Administration
- Quantitative Political Methodology
- Regional Political Studies
- Russian Politics
- Security Studies
- State and Local Government
- UK Politics
- US Politics
- Browse content in Regional and Area Studies
- African Studies
- Asian Studies
- East Asian Studies
- Japanese Studies
- Latin American Studies
- Middle Eastern Studies
- Native American Studies
- Scottish Studies
- Browse content in Research and Information
- Research Methods
- Browse content in Social Work
- Addictions and Substance Misuse
- Adoption and Fostering
- Care of the Elderly
- Child and Adolescent Social Work
- Couple and Family Social Work
- Developmental and Physical Disabilities Social Work
- Direct Practice and Clinical Social Work
- Emergency Services
- Human Behaviour and the Social Environment
- International and Global Issues in Social Work
- Mental and Behavioural Health
- Social Justice and Human Rights
- Social Policy and Advocacy
- Social Work and Crime and Justice
- Social Work Macro Practice
- Social Work Practice Settings
- Social Work Research and Evidence-based Practice
- Welfare and Benefit Systems
- Browse content in Sociology
- Childhood Studies
- Community Development
- Comparative and Historical Sociology
- Economic Sociology
- Gender and Sexuality
- Gerontology and Ageing
- Health, Illness, and Medicine
- Marriage and the Family
- Migration Studies
- Occupations, Professions, and Work
- Organizations
- Population and Demography
- Race and Ethnicity
- Social Theory
- Social Movements and Social Change
- Social Research and Statistics
- Social Stratification, Inequality, and Mobility
- Sociology of Religion
- Sociology of Education
- Sport and Leisure
- Urban and Rural Studies
- Browse content in Warfare and Defence
- Defence Strategy, Planning, and Research
- Land Forces and Warfare
- Military Administration
- Military Life and Institutions
- Naval Forces and Warfare
- Other Warfare and Defence Issues
- Peace Studies and Conflict Resolution
- Weapons and Equipment

A newer edition of this book is available.
- < Previous chapter
- Next chapter >

18 Content Analysis
Lindsay Prior, School of Sociology, Social Policy, and Social Work, Queen's University
- Published: 04 August 2014
- Cite Icon Cite
- Permissions Icon Permissions
In this chapter, the focus is on ways in which content analysis can be used to investigate and describe interview and textual data. The chapter opens with a contextualization of the method and then proceeds to an examination of the role of content analysis in relation to both quantitative and qualitative modes of social research. Following the introductory sections, four kinds of data are subjected to content analysis. These include data derived from a sample of qualitative interviews (N = 54), textual data derived from a sample of health policy documents (N = 6), data derived from a single interview relating to a “case” of traumatic brain injury, and data gathered from 54 abstracts of academic papers on the topic of “well-being.” Using a distinctive and somewhat novel style of content analysis that calls upon the notion of semantic networks, the chapter shows how the method can be used either independently or in conjunction with other forms of inquiry (including various styles of discourse analysis) to analyze data, and also how it can be used to verify and underpin claims that arise out of analysis. The chapter ends with an overview of the different ways in which the study of “content”—especially the study of document content—can be positioned in social scientific research projects.
What is Content Analysis?
In his 1952 text on the subject of content analysis, Bernard Berelson traces the origins of the method to communication research and then lists what he calls six distinguishing features of the approach. As one might expect, the six defining features reflect the concerns of social science as taught in the 1950s, an age in which the calls for an “objective,” “systematic,” and “quantitative” approach to the study of communication data were first heard. The reference to the field of “communication” was of course nothing less than a reflection of a substantive social scientific interest over the previous decades in what was called public opinion, and specifically attempts to understand why and how a potential of source of critical, rational judgement on political leaders (i.e., the views of the public) could be turned into something to be manipulated by dictators and demagogues. In such a context, it is perhaps not so surprising that in one of the more popular research methods texts of the decade, the terms content analysis and communication analysis are used interchangeably (see Goode & Hatt, 1952 :325).
Academic fashions and interests naturally change with available technology, and these days we are more likely to focus on the individualization of communications through Twitter and the like, rather than of mass newspaper readership or mass radio audiences, yet the prevailing discourse on content analysis has remained much the same as it was in Berleson’s day. Thus Neuendorf (2002 :1), for example, continues to define content analysis as “the systematic, objective, quantitative analysis of message characteristics.” Clearly the centrality of communication as a basis for understanding and using content analysis continues to hold, but in this article I will try to show that, rather than locate the use of content analysis in disembodied “messages” and distantiated “media,” we would do better to focus on the fact that communication is a building block of social life itself and not merely a system of messages that are transmitted—in whatever form—from sender to receiver. To put that statement in another guise, we need to note that communicative action (to use the phraseology of Habermas, 1987 ) rests at the very base of the lifeworld, and one very important way of coming to grips with that world is to study the content of what people say and write in the course of their everyday lives.
My aim is to demonstrate various ways in which content analysis (henceforth CTA) can be used and developed to analyze social scientific data as derived from interviews and documents. It is not my intention to cover the history of CTA or to venture into forms of literary analysis or to demonstrate each and every technique that has ever been deployed by content analysts. (Many of the standard textbooks deal with those kinds of issues much more fully than is possible here. See, for example, Babbie, 2013 ; Berelson, 1952 ; Bryman, 2008 , Krippendorf, 2004 ; Neuendorf, 2002 ; and Weber, 1990 ). Instead I seek to recontextualize the use of the method in a framework of network thinking and to link the use of CTA to specific problems of data analysis. As will become evident, my exposition of the method is grounded in real world problems. Those problems are drawn from my own research projects and tend to reflect my particular academic interests—which are almost entirely related to the analysis of the ways in which people talk and write about aspects of health, illness, and disease. However, lest the reader be deterred from going any further, I should emphasise that the substantive issues that I elect to examine are secondary if not tertiary to my main objective—which is to demonstrate how CTA can be integrated into a range of research designs and add depth and rigour to the analysis of interview and inscription data. To that end, in the next section I aim to clear our path to analysis by dealing with some issues that touch on the general position of CTA in the research armory, and especially its location in the schism that has developed between quantitative and qualitative modes of inquiry.
The Methodological Context of Content Analysis
Content analysis is usually associated with the study of inscription contained in published reports, newspapers, adverts, books, web pages, journals, and other forms of documentation. Hence, nearly all of Berelson’s (1952) illustrations and references to the method relate to the analysis of written records of some kind, and where speech is mentioned it is almost always in the form of broadcast and published political speeches (such as State of the Union addresses). This association of content analysis with text and documentation is further underlined in modern textbook discussions of the method. Thus Bryman (2008) for example, defines content analysis as “an approach to the analysis of documents and texts , that seek to quantify content in terms of pre-determined categories” (2008:274, emphasis in original), while Babbie (2013) states that content analysis is “the study of recorded human communications” (2013:295), and Weber refers to it as a method to make “valid inferences from text” (1990:9). It is clear then that CTA is viewed as a text-based method of analysis, though extensions of the method to other forms of inscriptional material are also referred to in some discussions. Thus Neuendorf (2002) , for example, rightly refers to analyses of film and television images as legitimate fields for the deployment of CTA, and by implication analyses of still—as well as moving—images such as photographs and billboard adverts. Oddly, in the traditional or standard paradigm of content analysis, the method is solely used to capture the “message” of a text or speech; it is not used for the analysis of a recipient’s response to or understanding of the message (which is normally accessed via interview data and analyzed in other and often less rigorous ways; see, e.g., Merton, 1968 ). So in this article I suggest that we can take things at least one small step further by using CTA to analyse speech (especially interview data) as well as text.
Standard textbook discussions of CTA usually refer to it as a “non-reactive” or “unobtrusive” method of investigation (see, e.g., Babbie, 2013 :294), and a large part of the reason for that designation is due to its focus on already existing text (i.e., text gathered without intrusion into a research setting). More importantly, however, (and to underline the obvious) CTA is primarily a method of analysis rather than of data collection. Its use therefore has to be integrated into wider frames of research design that embrace systematic forms of data collection as well as forms of data analysis. Thus routine strategies for sampling data are often required in designs that call upon CTA as a method of analysis. These latter can either be built around random sampling methods, or even techniques of “theoretical sampling” ( Glaser & Strauss, 1967 ) so as to identify as suitable range of materials for content analysis. CTA can also be linked to styles of ethnographic inquiry and to the use of various purposive or non-random sampling techniques. For an example, see Altheide (1987) .
Of course, the use of CTA in a research design does not preclude the use of other forms of analysis in the same study, for it is a technique that can be deployed in parallel with other methods or with other methods sequentially. For example, and as I will demonstrate in the following sections, one might use CTA as a preliminary analytical strategy to get a grip on the available data before moving into specific forms of discourse analysis. In this respect it can be as well to think of using CTA in, say, the frame of a priority/sequence model of research design as described by Morgan (1998) .
As I shall explain, there is a sense in which content analysis rests at the base of all forms of qualitative data analysis, yet the paradox is that the analysis of content is usually considered to be a quantitative (numerically based) method. In terms of the qualitative/quantitative divide, however, it is probably best to think of CTA as a hybrid method, and some writers have in the past argued that it is necessarily so ( Kracauer, 1952 ). That was probably easier to do in an age when many recognised the strictly drawn boundaries between qualitative and quantitative styles of research to be inappropriate. Thus in their widely used text on “ Methods in Social Research ,” Goode and Hatt (1952 :313), for example, asserted that, “[M]odern research must reject as a false dichotomy the separation between ‘qualitative’ and ‘quantitative’ studies, or between the ‘statistical’ and the ‘non-statistical’ approach.” It was a position advanced on the grounds that all good research must meet adequate standards of validity and reliability whatever its style, and it is a message well worth preserving. However, there is a more fundamental reason why it is nonsensical to draw a division between the qualitative and the quantitative. It is simply this: all acts of social observation depend on the deployment of qualitative categories—whether gender, class, race, or even age; there is no descriptive category in use in the social sciences that connects to a world of “natural kinds.” In short, all categories are made, and therefore when we seek to count “things” in the world, we are dependent on the existence of socially constructed divisions. How the categories take the shape that they do—how definitions are arrived at, how inclusion and exclusion criteria are decided upon, and how taxonomic principles are deployed—constitute interesting research questions in themselves. From our starting point, however, we need only note that “sorting things out” (to use a phrase from Bowker & Star, 1999 ) and acts of “counting”—whether it be of chromosomes or people ( Martin and Lynch, 2009 )—are activities that connect to the social world of organized interaction rather than to unsullied observation of the external world.
Of course, some writers deny the strict division between the qualitative and quantitative on grounds of empirical practice rather than of ontological reasoning. For example, Bryman (2008) argues that qualitative researchers also call upon quantitative thinking but tend to use somewhat vague, imprecise terms rather than numbers and percentages—referring to frequencies via the use of phrases such as “more than” and “less then.” Kracauer (1952) advanced various arguments against the view that CTA was strictly a quantitative method, suggesting that very often we wished to assess content as being negative or positive with respect to some political, social, or economic thesis and that such evaluations could never be merely statistical. He further argued that we often wished to study “underlying” messages or latent content of documentation and that in consequence we needed to interpret content as well as count items of content. Morgan (1993) has argued that, given the emphasis that is placed on “coding” in almost all forms of qualitative data analysis, the deployment of counting techniques is essential and that we ought therefore to think in terms of what he calls qualitative as well as quantitative content analysis. Naturally, some of these positions create more problems than they seemingly solve (as is the case with considerations of “latent content”), but given the twentieth-first-century predilection for “mixed-methods” research ( Creswell, 2007 ), it is clear that CTA has a role to play in integrating quantitative and qualitative modes of analysis in a systematic rather than merely an ad hoc and piecemeal fashion. In the sections that follow, I will provide some examples of the ways in which “qualitative” analysis can be combined with systematic modes of counting. First, however, we need to focus on what is analyzed in CTA.
Units of analysis
So what is the unit of analysis in CTA? A brief answer to that question is that analysis can be focused on words, sentences, grammatical structures, tenses, clauses, ratios (of say, nouns to verbs), or even “themes.” Berelson (1952) gives some examples of all of the above and also recommends a form of thematic analysis (c.f., Braun and Clarke, 2006 ) as a viable option. Other possibilities include counting column length (of speeches and newspaper articles), amounts of (advertising) space, or frequency of images. For our purposes, however, it might be useful to consider a specific (and somewhat traditional) example. Here it is. It is an extract from what has turned out to be one of the most important political speeches of the current century.
Iraq continues to flaunt its hostility toward America and to support terror. The Iraqi regime has plotted to develop anthrax and nerve gas and nuclear weapons for over a decade. This is a regime that has already used poison gas to murder thousands of its own citizens, leaving the bodies of mothers huddled over their dead children. This is a regime that agreed to international inspections then kicked out the inspectors. This is a regime that has something to hide from the civilized world. States like these, and their terrorist allies, constitute an axis of evil, arming to threaten the peace of the world. By seeking weapons of mass destruction, these regimes pose a grave and growing danger. They could provide these arms to terrorists, giving them the means to match their hatred. They could attack our allies or attempt to blackmail the United States. In any of these cases, the price of indifference would be catastrophic.” —George W. Bush, State of the Union address, January 29, 2002
A number of possibilities arise for analysing the content of a speech such as the one above. Clearly, words and sentences must play a part in any such analysis, but in addition to words there are structural features of the speech that could also figure. For example, the extract takes the form of a simple narrative—pointing to a past, a present, and an ominous future (catastrophe)—and could therefore be analysed as such. There are, in addition, a number of interesting oppositions in the speech (such as those between “regimes” and the “civilised” world), as well as a set of interconnected present participles such as “plotting,” “hiding,” “arming,” and “threatening” that are associated both with Iraq and with other states that “constitute an axis of evil.” Evidently, simple word counts would fail to capture the intricacies of a speech of this kind. Indeed, our example serves another purpose—to highlight the difficulty that often arises in dissociating content analysis from discourse analysis (of which narrative analysis and the analysis of rhetoric and trope are subspecies). So how might we deal with these problems?
One approach that can be adopted is to focus on what is referenced in text and speech. That is, to concentrate on the characters or elements that are recruited into the text and to examine the ways in which they are connected or co-associated. I shall provide some examples of this form of analysis shortly. Let us merely note for the time being that in the previous example we have a speech in which various “characters”—including weapons in general, specific weapons (such as nerve gas), threats, plots, hatred, evil and mass destruction—play a role. Be aware that we need not be concerned with the veracity of what is being said—whether it is true or false—but simply with what is in the speech and how what is in there is associated. (We may leave the task of assessing truth and falsity to the jurists). Be equally aware that it is a text that is before us and not an insight into the ex-President’s mind, nor his thinking, nor his beliefs, nor any other subjective property that he may have possessed.
In the introductory paragraph, I made brief reference to some ideas of the German philosopher Jűrgen Habermas (1987) . It is not my intention here to expand on the detailed twists and turns of his claims with respect to the role of language in the “lifeworld” at this point. However, I do intend to borrow what I regard as some particularly useful ideas from his work. The first, is his claim—influenced by a strong line of twentieth-century philosophical thinking—that language and culture are constitutive of the lifeworld (1987:125), and in that sense we might say that things (including individuals and societies) are made in language. That of course is a simple justification for focusing on what people say rather than what they “think” or “believe” or “feel” or “mean” (all of which have been suggested at one time or another as points of focus for social inquiry and especially qualitative forms of inquiry). Second, Habermas argues that speakers and therefore hearers (and one might add writers and therefore readers), in what he calls their speech acts, necessarily adopt a pragmatic relation to one of three worlds: entities in the objective world, things in the social world, and elements of a subjective world. In practice, Habermas (1987 :120) suggests all three worlds are implicated in any speech act but that there will be a predominant orientation to one of these. To rephrase this in a crude form, when speakers engage in communication, they refer to things and facts and observations relating to external nature, to aspects of interpersonal relations, and to aspects of private inner subjective worlds (thoughts, feelings, beliefs, etc.). One of the problems with locating CTA in “communication research” has been that the communications referred to are but a special and limited form of action (often what Habermas would call strategic acts). In other words, television, newspaper, video, and internet communications are just particular forms (with particular features) of action in general. Again we might note in passing that the adoption of the Habermassian perspective on speech acts implies that much of qualitative analysis in particular has tended to focus only on one dimension of communicative action—the subjective and private. In this respect, I would argue that it is much better to look at speeches such as George W Bush’s 2002 State of the Union address as an “account” and to examine what has been recruited into the account; and how what has been recruited is connected or co-associated rather than to use the data to form insights into his (or his adviser’s) thoughts, feelings, and beliefs.
In the sections that follow, and with an emphasis on the ideas that I have just expounded, I intend to demonstrate how CTA can be deployed to advantage in almost all forms of inquiry that call upon either interview (or speech-based) data or textual data. In my first example, I will show how CTA can be used to analyze a group of interviews. In the second example, I will show how it can be used to analyze a group of policy documents. In the third, I shall focus on a single interview (a “case”), and in the fourth and final example, I will show how CTA can be used to track the biography of a concept. In each instance, I shall briefly introduce the context of the “problem” on which the research was based, outline the methods of data collection, discuss how the data were analyzed and presented, and underline the ways in which content analysis has sharpened the analytical strategy.
Analyzing a Sample of Interviews: Looking at Concepts and Their Co-Associations in a Semantic Network
My first example of using CTA is based on a research study that was initially undertaken in the early 2000s. It was a project aimed at understanding why older people might reject the offer to be immunized against influenza (at no cost to them). The ultimate objective was to improve rates of immunization in the study area. The first phase of the research was based on interviews with 54 older people in South Wales. The sample included people who had never been immunized, some who had refused immunization, and some who had accepted immunization. Within each category, respondents were randomly selected from primary care physician patient lists, and the data were initially analyzed “thematically” and published accordingly ( Evans, Prout, Prior, et al., 2007 ). A few years later, however, I returned to the same data set to look at a different question—how (older) lay people talked about colds and flu, especially how they distinguished between the two illnesses and how they understood the causes of the two illnesses (see Prior, Evans, & Prout, 2011 ). Fortunately, in the original interview schedule, we had asked people about how they saw the “differences between cold and flu” and what caused flu, so it was possible to reanalyze the data with such questions in mind. In that frame, the example that follows demonstrates not only how CTA might be used on interview data, but also how it might be used to undertake a secondary analysis of a pre-existing data set ( Bryman, 2008 ).
As with all talk about illness, talk about colds and flu is routinely set within a mesh of concerns—about causes, symptoms, and consequences. Such talk comprises the base elements of what has at times been referred to as the “explanatory model” of an illness ( Kleinman, Eisenberg, & Good, 1978 ). In what follows, I shall focus almost entirely on issues of causation as understood from the viewpoint of older people; the analysis is based on the answers that respondents made in response to the question, “How do you think people catch flu?”
Semi-structured interviews of the kind undertaken for a study such as this are widely used and are often characterized as akin to “a conversation with a purpose” ( Kahn & Cannell, 1957 :97). One of the problems of analyzing the consequent data is that, although the interviewer holds to a planned schedule, the respondents often reflect in a somewhat unstructured way about the topic of investigation, so it is not always easy to unravel the web of talk about, say, “causes” that occurs in the interview data. In this example, causal agents of flu, inhibiting agents, and means of transmission were often conflated by the respondents. Nevertheless, in their talk people did answer the questions that were posed, and in the study referred to here, that talk made reference to things such as “bugs” (and “germs”) as well as viruses; but the most commonly referred to causes were “the air” and the “atmosphere.” The interview data also pointed toward means of transmission as “cause”—so coughs and sneezes and mixing in crowds figured in the causal mix. Most interesting perhaps was the fact that lay people made a nascent distinction between facilitating factors (such as bugs and viruses) and inhibiting factors (such as being resistant, immune, or healthy), so that in the presence of the latter, the former are seen to have very little effect. Here are some shorter examples of typical question-response pairs from the original interview data.
(R:32): “How do you catch it [the flu]? Well, I take it its through ingesting and inhaling bugs from the atmosphere. Not from sort of contact or touching things. Sort of airborne bugs. Is that right?” (R:3): “I suppose it’s [the cause of flu] in the air. I think I get more diseases going to the surgery than if I stayed home. Sometimes the waiting room is packed and you’ve got little kids coughing and spluttering and people sneezing, and air conditioning I think is a killer by and large I think air conditioning in lots of these offices”. (R:46): “I think you catch flu from other people. You know in enclosed environments in air conditioning which in my opinion is the biggest cause of transferring diseases is air conditioning. Worse thing that was ever invented that was. I think so, you know. It happens on aircraft exactly the same you know.”
Alternatively, it was clear that for some people being cold, wet, or damp could also serve as a direct cause of flu; thus:
Interviewer: “OK, good. How do you think you catch the flu?” (R:39): “Ah. The 65 dollar question. Well, I would catch it if I was out in the rain and I got soaked through. Then I would get the flu. I mean my neighbour up here was soaked through and he got pneumonia and he died. He was younger than me: well, 70. And he stayed in his wet clothes and that’s fatal. Got pneumonia and died, but like I said, if I get wet, especially if I get my head wet, then I can get a nasty head cold and it could develop into flu later.”
As I suggested earlier, despite the presence of bugs and germs, viruses, the air, and wetness or dampness, “catching” the flu is not a matter of simple exposure to causative agents. Thus some people hypothesized that within each person there is a measure of immunity or resistance or healthiness that comes into play and that is capable of counteracting the effects of external agents. For example, being “hardened” to germs and harsh weather can prevent a person getting colds and flu. Being “healthy” can itself negate the effects of any causative agents, and healthiness is often linked to aspects of “good” nutrition and diet and not smoking cigarettes. These mitigating and inhibiting factors can either mollify the effects of infection or prevent a person “catching” the flu entirely. Thus (R:45) argued that it was almost impossible for him to catch flu or cold “[c]os I got all this resistance.” Interestingly respondents often used possessive pronouns in their discussion of immunity and resistance (“my immunity” and “my resistance”)—and tended to view them as personal assets (or capital) that might be compromised by mixing with crowds.
By implication, having a weak immune system can heighten the risk of contracting cold and flu and might therefore spur one on to take preventive measures such as accepting a flu jab. There are some, of course, who believe that it is the flu jab that can cause the flu and other illnesses. An example of what might be called lay “epidemiology” ( Davison, Davey-Smith, & Frankel, 1991 ) is evident in the following extract.
(R:4): “Well, now it’s coincidental you know that [my brother] died after the jab, but another friend of mine, about 8 years ago, the same happened to her. She had the jab and about six months later, she died, so I know they’re both coincidental, but to me there’s a pattern.”
Normally, results from studies such as this are presented in exactly the same way as has just been set out. Thus the researcher highlights given themes that are said to have emerged out of the data and then provides appropriate extracts from the interviews to illustrate and substantiate the relevant themes. However, one very reasonable question that any critic might ask about the selected data extracts concerns the extent to which they are “representative” of the material in the data set as a whole. Maybe, for example, the author has been unduly selective in his or her use of both themes and quotations. Perhaps, as a consequence, the author has ignored or left out talk that does not fit their arguments or extracts that might be considered dull and uninteresting compared to more exotic material. And these kinds of issues and problems are certainly common to the reporting of almost all forms of qualitative research. However, the adoption of CTA techniques can help to mollify such problems. This is so because by using CTA we can indicate the extent to which we have used all or just some of the data, and we can provide a view of the content of the entire sample of interviews rather than just the content and flavor of merely one or two interviews. In this light, we need to consider Figure 18.1 . The figure is based on counting the number of references in the 54 interviews to the various “causes” of the flu, though references to the flu jab (i.e., inoculation) as a cause of flu have been ignored for the purpose of this discussion). The node sizes reflect the relative importance of each cause as determined by the concept count (frequency of occurrence). The links between nodes reflect the degree to which causes are co-associated in interview talk and are calculated according to a co-occurrence index (see, e.g., SPSS, 2007 :183).
Given this representation, we can immediately assess the relative importance of the different causes as referred to in the interview data. Thus we can see that such things as (poor) “hygiene” and “foreigners” were mentioned as a potential cause of flu—but mention of hygiene and foreigners was nowhere near so important as references to “the air” or to “crowds” or to “coughs and sneezes.” In addition, we can also determine the strength of the connections that interviewees made between one cause and another. Thus there are relatively strong links between “resistance” and “coughs and sneezes,” for example.
In fact, Figure 18.1 divides causes into the “external” and the “internal,” or the facilitating and the impeding (lighter and darker nodes). Among the former I have placed such things as crowds, coughs, sneezes, and the air while among the latter I have included “resistance,” “immunity,” and “health.” That division, of course, is a product of my conceptualizing and interpreting the data, but whichever way we organize the findings, it is evident that talk about the causes of flu belongs in a web or mesh of concerns that would be difficult to represent by the use of individual interview extracts alone. Indeed, it would be impossible to demonstrate how the semantics of causation belong to a culture (rather than to individuals) in any other way. In addition I would argue that the counting involved in the construction of the diagram functions as a kind of check on researcher interpretations and provides a source of visual support for claims that an author might make about, say, the relative importance of “damp” and “air” as perceived causes of disease. Finally, the use of CTA techniques allied with aspects of conceptualization and interpretation has enabled us to approach the interview data as a set and to consider the respondents as belonging to a community rather than regarding them merely as isolated and disconnected individuals, each with their own views. It has also enabled us to squeeze some new findings out of old data, and I would argue that it has done so with advantage. There are of course other advantages to using CTA to explore data sets, which I highlight in the next section.
What causes flu? A lay perspective. Factors listed as causes of colds and flu in 54 interviews. Node size is proportional to number of references “as causes.” Line thickness is proportional to co-occurrence of any two “causes” in the set of interviews.
Analyzing a Sample of Documents: Using Content Analysis to Verify Claims
Policy analysis is a difficult business. For a start, it is never entirely clear where (social, health, economic, environmental) policy actually is. Is it in documents (as published by governments, think tanks, and research centres), in action (what people actually do), or in speech (what people say)? Perhaps it rests in a mixture of all three realms. Yet wherever it may be, it is always possible, at the very least, to identify a range of policy texts and to focus on the conceptual or semantic webs in terms of which government officials and other agents (such as politicians) talk about the relevant policy issues. Furthermore, in so far as policy is recorded—in speeches, pamphlets, and reports—we may begin to speak of specific policies as having a history or a pedigree that unfolds through time (think, e.g., of US or UK health policies during the Clinton years or the Obama years). And in so far as we consider “policy” as having a biography or a history, we can also think of studying policy narratives.
Though firmly based in the world of literary theory, narrative method has been widely used for both the collection and the analysis of data concerning ways in which individuals come to perceive and understand various states of health, ill health, and disability ( Frank, 1995 ; “ Hydén, 1997 ). Narrative techniques have also been adapted for use in clinical contexts and allied to concepts of healing ( Charon, 2006 ). In both social scientific and clinical work, however, the focus is invariably on individuals and on how individuals “tell” stories of health and illness. Yet narratives can also belong to collectives—such as political parties and ethnic and religious groups—just as much as to individuals, and in the latter case there is a need to collect and analyse data that are dispersed across a much wider range of materials than can be obtained from the personal interview. In this context, Roe (1994) has demonstrated how narrative method can be applied to an analysis of national budgets, animal rights, and environmental policies.
An extension of the concept of narrative to policy discourse is undoubtedly useful ( Newman & Vidler, 2006 ), but how might such narratives be analyzed? What strategies can be used to unravel the form and content of a narrative, especially in circumstances where the narrative might be contained in multiple (policy) documents, authored by numerous individuals, and published across a span of time rather than in a single, unified text such as a novel? Roe (1994) , unfortunately, is not in any way specific about analytical procedures apart from offering the useful rule to “never stray too far from the data” (1994:xii). So in this example I will outline a strategy for tackling such complexities. In essence, it is a strategy that combines techniques of linguistically (rule) based content analysis with a theoretical and conceptual frame that enables us to unraveland identify the core features of a policy narrative. My substantive focus is on documents concerning health service delivery policies published 2000–2009 in the constituent countries of the UK (that is, England, Scotland, Wales, and Northern Ireland—all of which have different political administrations).
Narratives can be described and analyzed in various ways, but for our purposes we can say that they have three key features: they point to a chronology, they have a plot and they contain “characters.”
Chronology : All narratives have beginnings; they also have middles and endings, and these three stages are often seen as comprising the fundamental structure of narrative text. Indeed, in his masterly analysis of time and narrative, Ricoeur (1984) argues that it is in the unfolding chronological structure of a narrative that one finds its explanatory (and not merely descriptive) force. By implication, one of the simplest strategies for the examination of policy narratives is to locate and then divide a narrative into its three constituent parts—beginning, middle, and end.
Unfortunately, while it can sometimes be relatively easy to locate or choose a beginning to a narrative, it can be much more difficult to locate an end point. Thus in any illness narrative, a narrator might be quite capable of locating the start of an illness process (in an infection, accident, or other event) but unable to see how events will be resolved in an ongoing and constantly unfolding life. As a consequence, both narrators and researchers usually find themselves in the midst of an emergent present—a present without a known and determinate end (see, e.g., Frank, 1995 ). Similar considerations arise in the study of policy narratives where chronology is perhaps best approached in terms of (past) beginnings, (present) middles, and projected futures.
Plot : According to Ricoeur (1984) , our basic ideas about narrative are best derived from the work and thought of Aristotle who in his Poetics sought to establish “first principles” of composition. For Ricoeur, as for Aristotle, plot ties things together. It “brings together factors as heterogeneous as agents, goals, means, interactions, circumstances, unexpected results” (1984:65) into the narrative frame. For Aristotle, it is the ultimate untying or unraveling of the plot that releases the dramatic energy of the narrative.
Character : Characters are most commonly thought of as individuals, but they can be considered in much broader terms. Thus the French semiotician A. J. Greimas (1970) , for example, suggested that, rather than think of characters as people, it would be better to think in terms of what he called “actants” and of the functions that such actants fulfill within a story. In this sense geography, climate, and capitalism can be considered as characters every bit as much as aggressive wolves and Little Red Riding Hood. Further, he argued that the same character (actant) can be considered to fulfill many functions and the same function performed by many characters. Whatever else, the deployment of the term actant certainly helps us to think in terms of narratives as functioning and creative structures. It also serves to widen our understanding of the ways in which concepts, ideas, and institutions, as well “things” in the material world can influence the direction of unfolding events every bit as much as conscious human subjects. Thus, for example, the “American people,” “the nation,” “the constitution,” “ the West,” “tradition,” and “Washington” can all serve as characters in a policy story.
As I have already suggested, narratives can unfold across many media and in numerous arenas—speech and action, as well as text. Here, however, my focus is solely on official documents—all of which are UK government policy statements as listed in Table 18.1 . The question is how might CTA help us unravel the narrative frame?
It might be argued that a simple reading of any document should familiarize the researcher with elements of all three policy narrative components (plot, chronology, and character). However, in most policy research, we are rarely concerned with a single and unified text as is the case with a novel, but rather with multiple documents written at distinctly different times by multiple (usually anonymous) authors that notionally can range over a wide variety of issues and themes. In the full study, some 19 separate publications were analyzed across England, Wales, Scotland, and Northern Ireland.
Naturally, to list word frequencies—still less to identify co-occurrences and semantic webs in large data sets (covering hundreds of thousand of words and footnotes)—cannot be done manually but rather requires the deployment of complex algorithms and text-mining procedures. To this end I analyzed the 19 documents using “Text Mining for Clementine” ( SPSS, 2007 ).
Text-mining procedures begin by providing an initial list of concepts based on the lexicon of the text but which can be weighted according to word frequency and which take account of elementary word associations. For example, learning disability, mental health, and performance management indicate three concepts, not six words. Using such procedures on the aforementioned documents gives the researcher an initial grip on the most important concepts in the document set of each country. Note that this is much more than a straightforward concordance analysis of the text and is more akin to what Ryan & Bernard (2000) have referred to as “semantic analysis” and Carley (1993) has referred to as “concept” and “mapping” analysis.
So the first task was to identify and then extract the core concepts, thus identifying what might be called “key” characters or actants in each of the policy narratives. For example, in the Scottish documents such actants included “Scotland” and the “Scottish people,” as well as “health” and the “NHS,” among others; while in the Welsh documents it was “the people of Wales” and “Wales” that figured largely—thus emphasizing how national identity can play every bit as important a role in a health policy narrative as concepts such as “health,” “hospitals,” and “wellbeing.”
Having identified key concepts it was then possible to track concept clusters in which particular actants or characters are embedded. Such cluster analysis is dependent on the use of co-occurrence rules and the analysis of synonyms, whereby it is possible to get a grip on the strength of the relationships between the concepts, as well as the frequency with which the concepts appear in the collected texts. In Figure 18.2 , I provide an example of a concept cluster. The diagram indicates the nature of the conceptual and semantic web in which various actants are discussed. The diagrams further indicate strong (solid line) and weaker (dotted line) connections between the various elements in any specific mix, and the numbers indicate frequency counts for the individual concepts. Using Clementine , the researcher is unable to specify in advance which clusters will emerge from the data. One cannot, for example, choose to have an NHS cluster. In that respect, these diagrams not only provide an array in terms of which concepts are located, but also serve as a check on and to some extent validation of the interpretations of the researcher. Of course none of this tells us what the various narratives contained within the documents might be. They merely point to key characters and relationships both within and between the different narratives. So having indicated the techniques used to identify the essential parts of the four policy narratives, it is now time to sketch out their substantive form.
It may be useful to note that Aristotle recommended brevity in matters of narrative —deftly summarising the whole of the Odyssey in just seven lines. In what follows, I attempt—albeit somewhat weakly—to emulate that example by summarising a key narrative of English health services policy in just four paragraphs. The citations are of Department of Health publications (by year) as listed in Table 18.1 . Note how the narrative unfolds in relation to the dates of publication. In the English case (though not so much in the other UK countries), it is a narrative that is concerned to introduce market forces into what is and has been a state-managed health service. Market forces are justified in terms of improving opportunities for the consumer (i.e., the patients in the service), and the pivot of the newly envisaged system is something called “patient choice” or “choice.” This is how the story unfolds as told through the policy documents between 2000–2008 (see Table 18.1 ).
The advent of the NHS in 1948 was a “seminal event” (2000:8), but under successive Conservative administrations the NHS was seriously underfunded (2006:3). The (New Labour) government will invest (2000) or already has (2003:4) invested extensively in infrastructure and staff, and the NHS is now on a “journey of major improvement” (2004:2). But “more money is only a starting point” (2000:2), and the journey is far from finished. Continuation requires some fundamental changes of “culture” (2003:6). In particular, the NHS remains unresponsive to patient need, and “[a]ll too often, the individual needs and wishes are secondary to the convenience of the services that are available. This ‘one size fits all’ approach is neither responsive, equitable nor person-centred” (2003:17). In short, the NHS is a 1940s system operating in a twenty-first-century world (2000:26). Change is therefore needed across the “whole system” (2005:3) of care and treatment.
Above all, we have to recognize that we “live in a consumer age” (2000:26). People’s expectations have changed dramatically (2006:129), and people want more choice, more independence, and more control (2003:12) over their affairs. Patients are no longer, and should not be considered as, “passive recipients” of care (2003:62), but wish to be and should be (2006:81) actively “involved” in their treatments (2003:38, 2005:18)—indeed, engaged in a partnership (2003:22) of respect with their clinicians. Furthermore, most people want a personalized service “tailor made to their individual needs” (2000:17, 2003:15, 2004:1, 2006:83)—“[a] service which feels personal to each and every individual within a framework of equity and good use of public money” (2003:6).
To advance the necessary changes, “patient choice” needs to be and “will be strengthened” (2000:89). “Choice” must be made to “happen” (2003), and it must be “real” (2003:3, 2004:5, 2005:20, 2006:4). Indeed, it must be “underpinned” (2003:7) and “widened and deepened” (2003:6) throughout the entire system of care.
If “we” expand and underpin patient choice in appropriate ways and engage patients in their treatment systems, then levels of patient satisfaction will increase (2003:39), and their choices will lead to a more “efficient” (2003:5, 2004:2, 2006:16) and effective (2003:62, 2005:8) use of resources. Above all, the promotion of choice will help to drive up “standards” of care and treatment (2000:4, 2003:12, 2004:3, 2005:7, 2006:3). Furthermore, the expansion of choice will serve to negate the effects of the “inverse care law,” whereby those who need services most tend to get catered for the least (2000:107, 2003:5, 2006:63), and it will thereby help in moderating the extent of health inequalities in the society in which we live. “The overall aim of all our reforms,” therefore, “is to turn the NHS from a top down monolith into a responsive service that gives the patient the best possible experience. We need to develop an NHS that is both fair to all of us, and personal to each of us” (2003:5).
Concept cluster for “care” in six English policy documents, 2000–2007. Line thickness is proportional to the strength co-occurrence co-efficient. Node size reflects relative frequency of concept, and (numbers) refer to the frequency of concept. Solid lines indicate relationships between terms within the same cluster, and dotted lines indicate relationships between terms in different clusters.
We can see how most—though not all—of the elements of this story are represented in Figure 18.2 . In particular we can see strong (co-occurrence) links between “care” and “choice” and how partnership, performance, control, and improvement have a prominent profile. There are of course some elements of the web that have a strong profile (in terms of node size and links) but to which we have not referred; access, information, primary care, and waiting times are four. As anyone well versed in English health care policy would know, these have important roles to play in the wider, consumer-driven narrative. However, by rendering the excluded as well as included elements of that wider narrative visible, the concept web provides a degree of verification on the content of the policy story as told herein and on the scope of its “coverage.”
In following through on this example, we have of course moved from content analysis to a form of discourse analysis (in this instance narrative analysis). That shift underlines aspects of both the versatility of CTA and some of its weaknesses—versatility in the sense that CTA can be readily combined with other methods of analysis and in the way in which the results of the CTA help us to check and verify the claims of the researcher. The weakness of the diagram compared to the narrative is that CTA on its own is a somewhat one-dimensional and static form of analysis, and while it is possible to introduce time and chronology into the diagrams, the diagrams themselves remain lifeless in the absence of some form of discursive overview. (For a fuller analysis of these data see, Prior, Hughes, & Peckham, 2012 ).
Analyzing a Single Interview: The Role of Content Analysis in a Case Study
So far I have focused on using content analysis on a sample of interviews and on a sample of documents. In the first instance, I recommended CTA for its capacity to tell us something about what is seemingly central to interviewees and for demonstrating how what is said is linked (in terms of a concept network). In the second instance, I reaffirmed the virtues of co-occurrence and network relations, but this time in the context of a form of discourse analysis. I also suggested that CTA can serve an important role in the process of verification of a narrative and its academic interpretation. In this section, however, I am going to link the use of CTA to another style of research—case study—to show how CTA might be used to analyze a single “case.”
Case study is a term used in multiple and often ambiguous ways. However, Gerring (2004 :342) defines it as “an intensive study of a single unit for the purpose of understanding a larger class of (similar) units.” As Gerring points out, case study does not necessarily imply a focus on N = 1, although that is indeed the most logical number for case study research ( Ragin & Becker, 1992 ). Naturally, an N of 1 can be immensely informative, and whether we like it or not we often have only one N to study (think, e.g., of the 1986 Challenger shuttle disaster, or of the 9/11 attack on the World Trade Center). In the clinical sciences, of course, case studies are widely used to represent the “typical” features of a wider class of phenomena, and often used to define a kind or syndrome (as is in the field of clinical genetics). Indeed, at the risk of mouthing a tautology, one can say that the distinctive feature of case study is its focus on a case in all of its complexity—rather than on individual variables and their inter-relationships, which tends to be a point of focus for large N research.
There was a time when case study was central to the science of psychology. Breuer and Freud’s (2001) famous studies of “hysteria” (orig. 1895) provide an early and outstanding example of the genre in this respect, but as with many of the other styles of social science research, the influence of case studies waned with the rise of much more powerful investigative techniques—including experimental methods—driven by the deployment of new statistical technologies. Ideographic studies consequently gave way to the current fashion for statistically driven forms of analysis that focus on causes and cross-sectional associations between variables rather than ideographic complexity.
In the example that follows, we will look at the consequences of a traumatic brain injury (TBI) on just one individual. The analysis is based on an interview with a person suffering from such an injury, and it was one of 32 interviews carried out with people who had experienced a TBI. The objective of the original research was to develop an outcome measure for TBI that was sensitive to the sufferer’s (rather than the health professional’s) point of view. In our original study (see Morris, Prior, Deb et al., 2005 ), interviews were also undertaken with 27 carers of the injured with the intention of comparing their perceptions of TBI to those of the people for which they cared. A sample survey was also undertaken to elicit views about TBI from a much wider population of patients than was studied via interview.
In the introduction, I referred to Habermas and the concept of the “lifeworld.” Lifeworld ( Lebenswelt ) is a concept that first arose out of twentieth-century German philosophy. It constituted a specific focus for the work of Alfred Schutz (see, e.g., Schutz and Luckman, 1974 ). Schutz described the lifeworld as “that province of reality which the wide-awake and normal adult simply takes-for-granted in an attitude of common sense” (1974:3). Indeed, it was the routine and taken-for-granted quality of such a world that fascinated Schutz. As applied to the worlds of those with head injuries, the concept has particular resonance because head injuries often result in that taken-for-granted quality being disrupted and fragmented, ending in what Russian neuropsychologist A.R. Luria once described as “shattered” worlds ( Luria, 1975 ). As well as providing another excellent example of a case study, Luria’s work is also pertinent because he sometimes argued for a “romantic science” of brain injury—that is, a science that sought to grasp the world view of the injured patient by paying attention to an unfolding and detailed personal “story” of the head injured as well as to the neurological changes and deficits associated with the injury itself. In what follows, I shall attempt to demonstrate how CTA might be used to underpin such an approach.
In the original research, we began analysis by a straightforward reading of the interview transcripts. Unfortunately, a simple reading of a text or an interview can, strangely, mislead the reader into thinking that some issues or themes are actually more important than is warranted by the actual contents of the text. How that comes about is not always clear, but it probably has something to do with a desire to develop “findings” and our natural capacity to overlook the familiar in favor of the unusual. For that reason alone, it is always useful to subject any text to some kind of concordance analysis—that is, generating a simple frequency list of words used in an interview or text. Given the current state of technology, one might even speak these days of using text-mining procedures such as the aforementioned Clementine to undertake such a task. By using Clementine, and as we have seen, it is also possible to measure the strength of co-occurrence links between elements (i.e., words and concepts) in the entire data set (in this example, 32 interviews), though for a single interview these aims can just as easily be achieved using much simpler, low-tech strategies.
By putting all 32 interviews into the database, a number of common themes emerged. For example, it was clear that “time” entered into the semantic web in a prominent manner, and it was clearly linked to such things as “change,” “injury,” “the body,” and what can only be called the “I was.” Indeed, time runs through the 32 stories in many guises, and the centrality of time is of course a reflection of storytelling and narrative recounting in general—chronology, as we have noted, being a defining feature of all story telling ( Ricoeur, 1984 ). Thus sufferers recounted both the events surrounding their injury and provided accounts as to how the injuries affected their present life and future hopes. As to time present, much of the patient story circled around activities of daily living—walking, working, talking, looking, feeling, remembering, and so forth.
Understandably, the word and the concept of “injury” featured largely in the interviews, though it was a word most commonly associated with discussions of physical consequences of injury. There were many references in that respect to injured arms, legs, hands, and eyes. There were also references to “mind”—though with far lesser frequency than with references to the body and to body parts. Perhaps none of this is surprising. However, one of the most frequent concepts in the semantic mix was the “I was” (716 references). The statement “I was,” or “I used to” was in turn strongly connected to terms such as “the accident” and “change.” Interestingly, the “I was” overwhelmingly eclipsed the “I am” in the interview data (the latter with just 63 references). This focus on the “I was” appears in many guises. For example, it is often associated with the use of the passive voice: “I was struck by a car;” “I was put on the toilet;” “I was shipped from there then, transferred to [Cityville];” “I got told that I would never be able...;” “I was sat in a room,” and so forth. In short, the “I was” is often associated with things, people, and events acting upon the injured person. More importantly, however, the appearance of the “I was” is often used to preface statements signifying a state of loss or change in the person’s course of life—that is, as an indicator for talk about the patient’s shattered world. For example, Patient 7122 stated, “The main (effect) at the moment is I’m not actually with my children, I can’t really be their mum at the moment. I was a caring Mum, but I can’t sort of do the things that I want to be able to do like take them to school. I can’t really do a lot on my own. Like crossing the roads.”
Another patient stated, “Everything is completely changed. The way I was... I can’t really do anything at the moment. I mean my German, my English, everything’s gone. Job possibilities is out the window. Everything is just out of the window... I just think about it all the time actually every day you know. You know it has destroyed me anyway, but if I really think about what has happened I would just destroy myself.”
Each of these quotations in its own way serves to emphasize how life has changed and how the patient’s world has changed. In that respect, we can say that one of the major outcomes arising from TBI may be substantial “biographical disruption” ( Bury, 1982 ), whereupon key features of an individual’s life course are radically altered forever. Indeed, as Becker (1997 :37) argues in relation to a wide array of life events, “When their health is suddenly disrupted, people are thrown into chaos. Illness challenges one’s knowledge of one’s body. It defies orderliness. People experience the time before their illness and its aftermath as two separate entities.” Indeed, this notion of a cusp in personal biography is particularly well illustrated by Luria’s patient Zasetsky; the latter often refers to being a “newborn creature” ( Luria, 1975 :24, 88), a shadow of a former self (1975;25), and as having his past “wiped out” (1975: 116).
However, none of this tells us about how these factors come together in the life and experience of one individual. When we focus on an entire set of interviews, we necessarily lose the rich detail of personal experience and tend instead to rely on a conceptual rather than a graphic description of effects and consequences (to focus on, say, “memory loss,” rather than loss of memory about family life). The contents of Figure 18.3 attempt to correct that vision. It records all of the things that a particular respondent (Patient 7011 )used to do and liked doing. It records all of the things that he says that can no longer do (at one year after injury), and it records all of the consequences that he suffered from his head injury at the time of interview. Thus we see references to epilepsy (his “fits”), paranoia (the patient spoke of his suspicions concerning other people, people scheming behind his back, and his inability to trust others), deafness, depression, and so forth. Note that, although I have inserted a future tense into the web (“I will”), such a statement never appeared in the transcript. I have set it there for emphasis and to show how for this person the future fails to connect to any of the other features of his world except in a negative way. Thus he states at one point that he cannot think of the future because it makes him feel depressed (see Fig. 18.3). The line thickness of the arcs reflect the emphasis that the subject placed on the relevant “outcomes” in relation to the “I was” and the “now” during the interview. Thus we see that factors affecting his concentration and balance loom large but that he is also concerned about his being dependent on others, his epileptic fits, and his being unable to work and drive a vehicle. The schism in his life between what he used to do, what cannot now do, and his current state of being is nicely represented in the CTA diagram.
What have we gained from executing this kind of analysis? For a start, we have moved away from a focus on variables, frequencies, and causal connections (e.g., a focus on the proportion of people with TBI who suffer from memory problems or memory problems and speech problems) and refocused on how the multiple consequences of a TBI link together in one person. In short, instead of developing a narrative of acting variables, we have emphasized a narrative of an acting individual ( Abbott, 1992 :62). Second, it has enabled us to see how the consequences of a TBI connect to an actual lifeworld (and not simply an injured body). So the patient is not viewed just as having a series of discrete problems such as balancing, or staying awake, which is the usual way of assessing outcomes, but is seen as someone struggling to come to terms with an objective world of changed things, people, and activities (missing work is not, for example, routinely considered an “outcome” of head injury). Third, by focusing on what the patient was saying, we gain insight into something that is simply not visible by concentrating on single outcomes or symptoms alone—namely, the void that rests at the center of the interview, what I have called the “I was.” Fourth, we have contributed to understanding a type, for the case that we have read about is not simply a case of “John” or “Jane” but a case of TBI, and in that respect it can add to many other accounts of what it is like to experience head injury—including one of the most well documented of all TBI cases, that of Zatetsky. Finally, we have opened up the possibility of developing and comparing cognitive maps ( Carley, 1993 ) for different individuals, and thereby gained insight into how alternative cognitive frames of the world arise and operate.
The shattered world of patient 7011. Thickness of lines (arcs) are proportional to the frequency of reference to the “outcome” by the patient during interview.
Tracing the biography of a concept
In the previous sections, I emphasised the virtues of CTA for its capacity to link into a data set in its entirety—and how the use of CTA can counter any tendency of a researcher to be selective and partial in the presentation and interpretation of information contained in interviews and documents. However, that does not mean that we always have to take an entire document or interview as the data source. Indeed, it is possible to select (on rational and explicit grounds) sections of documentation and to conduct the CTA on the chosen portions. In the example that follows, I do just that. The sections that I chose to concentrate on are titles and abstracts of academic papers—rather than the full texts. The research on which the following is based is concerned with a biography of a concept and is being conducted in conjunction with a PhD student of mine, Joanne Wilson. Joanne thinks of this component of the study more in terms of a “scoping study” than of a biographical study, and that too is a useful framework for structuring the context in which CTA can be used. Scoping studies ( Arksey & O’Malley, 2005 ) are increasingly used in health related research to “map the field” and to get a sense of the range of work that has been conducted on a given topic. Such studies can also be used to refine research questions and research designs. In our investigation the scoping study was centred on the concept of “well-being.” During the past decade or so, “well-being” has emerged as an important research target for governments and corporations as well as for academics, yet it is far from clear to what the term refers. Given the ambiguity of meaning, it is clear that a scoping review, rather than either a systematic review or a narrative review of available literature, would be best suited to our goals.
The origins of the concept of well-being can be traced at least as far back as the fourth century B.C., when philosophers produced normative explanations of the good life (e.g., eudaimonia, hedonia, and harmony). However, contemporary interest in the concept seemed to have been regenerated by the concerns of economists and most recently psychologists. These days governments are equally concerned with measuring well-being to inform policy and conduct surveys of well-being to assess that state of the nation (see, e.g., Office for National Statistics [ONS], 2012 )—but what are they assessing?
We adopted a two-step process to address the research question, “What is the meaning of ‘well-being’ in the context of public policy?” First, we explored the existing thesauri of eight databases to establish those higher-order headings (if any) under which articles with relevance to well-being might be catalogued. Thus we searched the following databases: Cumulative Index of Nursing and Allied Health Literature [CINAHL], EconLit, Health Management Information Consortium [HMIC], MEDLINE, Philosopher’s Index, PsycINFO, Sociological Abstracts, and Worldwide Political Science Abstracts (WPSA). Each of these databases adopts keyword-controlled vocabularies. In other words, they use inbuilt statistical procedures to link core terms to a set lexis of phrases that depict the concepts contained in the database. Table 18.2 shows each database and its associated taxonomy. The contents of the table point toward a linguistic infrastructure in terms of which academic discourse is conducted, and our task was to extract from this infrastructure the semantic web wherein the concept of “well-being” is situated. We limited the thesaurus terms to “well-being” and its variants (i.e., wellbeing or well being). If the term was returned, it was then exploded to identify any associated terms.
CINAHL = Cumulative Index of Nursing and Allied Health Literature; HMIC = Health Management Information Consortium; WPSA = Worldwide Political Science Abstracts.
To develop the conceptual map, we conducted a free-text search for well-being and its variants within the context of public policy across the same databases. We orchestrated these searches across five separate timeframes: January 1990 to December 1994, January 1995 to December 1999, January 2000 to December 2004, January 2005 to December 2009, and January 2010 to October 2011. Naturally, different disciplines use different words to refer to well-being, each of which may wax and wane in usage over time. The searches thus sought to quantitatively capture any changes in the use and subsequent prevalence of well-being and any referenced terms (i.e., to trace a biography).
It is important to note that we did not intend to provide an exhaustive, systematic search of all the relevant literature. Rather we wanted to establish the prevalence of well-being and any referenced (i.e., allied) terms within the context of public policy. This has the advantage of ensuring that any identified words are grounded in the literature (i.e., they represent words actually used by researchers to talk and write about well-being in policy settings). The searches were limited to abstracts to increase specificity, albeit at some expense to sensitivity, with which we could identify relevant articles.
We also employed inclusion/exclusion criteria to facilitate the process by which we selected articles, thereby minimizing any potential bias arising from our subjective interpretations. We included independent, standalone investigations relevant to the study’s objectives (i.e., concerned with well-being in the context of public policy), which focused on well-being as a central outcome or process and which made explicit reference to “well-being” and “public policy” in either the title or the abstract. We excluded articles that were irrelevant to the study’s objectives, used noun adjuncts to focus on the well-being of specific populations (i.e., children, elderly, women) and contexts (e.g., retirement village), or that focused on deprivation or poverty unless poverty indices were used to understand well-being as opposed to social exclusion. We also excluded book reviews and abstracts describing a compendium of studies.
Using these criteria, Joanne Wilson conducted the review and recorded the results on a template developed specifically for the project, organized chronologically across each database and timeframe. Results were scrutinized by two other colleagues to ensure the validity of the search strategy and the findings. Any concerns regarding the eligibility of studies for inclusion were discussed amongst the research team. I then analyzed the co-occurrence of the key terms in the database. The resultant conceptual map is shown in Figure 18.4 .
The diagram can be interpreted as a visualization of a conceptual space. So when academics write about “well-being” in the context of public policy, they tend to connect the discussion to the other terms in the matrix. “Happiness,” “health,” “economic,” and “subjective,” for example, are relatively dominant terms in the matrix. The node size of these words suggest that references to such entities is only slightly less than reference to well-being itself. However, when we come to analyse how well-being is talked about in detail, we see specific connections come to the fore. Thus the data imply that talk of “subjective well-being” far outweighs discussion of “social well-being,” or “economic well-being.” Happiness tends to act as an independent node (there is only one occurrence of happiness and well-being), probably suggesting that “happiness” is acting as a synonym for wellbeing. Quality of life (QoL) is poorly represented in the abstracts, and its connection to most of the other concepts in the space is very weak—confirming, perhaps, that QoL is unrelated to contemporary discussions of well-being and happiness. The existence of “measures” points to a distinct concern to assess and to quantify expressions of happiness, well-being, economic growth, and gross domestic product. More important and underlying this detail, there are grounds for suggesting that there are in fact a number of tensions in the literature on well-being.
On one hand, the results point toward an understanding of well-being as a property of individuals—as something that they feel or experience. Such a discourse is reflected through the use of words like “happiness,” “subjective,” and “individual.” This individualistic and subjective frame has grown in influence over the past decade in particular, and one of the problems with it is that it tends toward a somewhat content-free conceptualisation of well-being. To feel a sense of well-being one merely states that one is in a state of well-being; to be happy, one merely proclaims that one is happy (cf. ONS, 2012 ). It is reminiscent of the conditions portrayed in Aldous Huxley’s Brave New World , wherein the rulers of a closely managed society gave their priority to maintaining order and ensuring the happiness of the greatest number—in the absence of attention to justice or freedom of thought or any sense of duty and obligation to others, many of whom were systematically bred in “the hatchery” as slaves.
The position of a concept in a network—a study of “wellbeing.” Node size is proportional to the frequency of terms in 54 selected abstracts. Line thickness is proportional to the co-occurrence of two terms in any phrase of three words (e.g., subjective well-being, economics of well-being, well-being and development).
On the other hand, there is some intimation in our web that the notion of well-being cannot be captured entirely by reference to individuals alone and that there are other dimensions to the concept—that well-being is the outcome or product of, say, access to reasonable incomes, to safe environments, to “development,” and to health and welfare. It is a vision hinted at by the inclusion of those very terms in the network. These different concepts necessarily give rise to important differences concerning how well-being is identified and measured and therefore what policies are most likely to advance well-being. In the first kind of conceptualization, we might improve well-being merely by dispensing what Huxley referred to as “soma” (a super drug that ensured feelings of happiness and elation); in the other case, however, we would need to invest in economic, human, and social capital as the infrastructure for well-being. In any event and even at this nascent level, we can see how content analysis can begin to tease out conceptual complexities and theoretical positions in what is otherwise routine textual data.
Putting the Content of Documents in Their Place
I suggested in my introduction that CTA was a method of analysis—not a method of data collection nor a form of research design. As such, it does not necessarily inveigle us into any specific forms of either design or of data collection, though designs and methods that rely on quantification are dominant. In this closing section, however, I want to raise the issue as to how we should position a study of content in our research strategies as a whole. For we need to keep in mind that documents and records always exist in a context, and that while what is “in” the document may be considered central, a good research plan can often encompass a variety of ways of looking at how content links to context. Hence in what follows I intend to outline how an analysis of content might be combined with other ways of looking at a record or text, and even how the analysis of content might even be positioned as secondary to an examination of a document or record. The discussion calls upon a much broader analysis as presented in Prior (2011) .
I have already stated that basic forms of CTA can serve as an important point of departure for many different types of data analysis—for example, as discourse analysis. Naturally, whenever “discourse” is invoked, there is at least some recognition of the notion that words might actually play a part in structuring the world rather than merely reporting on it or describing it (as is the case with the 2002 State of the Nation address that was quoted in Section “Units of Analysis”). Thus, for example, there is a considerable tradition within social studies of science and technology for examining the place of scientific rhetoric in structuring notions of “nature” and the position of human beings (especially as scientists) within nature (see, e.g., work by Bazerman, 1988 ); Gilbert & Mulkay, 1984 ; and Kay, 2000 ). Nevertheless, little if any of that scholarship situates documents as anything other than as inert objects, either constructed by or waiting patiently to be activated by scientists.
However, in the tradition of the ethnomethodologists ( Heritage, 1991 ) and some adherents of discourse analysis, it is also possible to argue that documents might be more fruitfully approached as a “topic” ( Zimmerman and Pollner; 1971 ) rather than a “resource” (to be scanned for content), in which case the focus would be on the ways in which any given document came to assume its present content and structure. In the field of documentation, these latter approaches are akin to what Foucault (1970) might have called an “archaeology of documentation” and are well represented in studies of such things as how crime, suicide, and other statistics and associated official reports and policy documents are routinely generated. That too is a legitimate point of research focus, and it can often be worth examining the genesis of, say, suicide statistics or statistics about the prevalence of mental disorder in a community as well as using such statistics as a basis for statistical modeling.
Unfortunately, the distinction between topic and resource is not always easy to maintain—especially in the hurly-burly of doing empirical research (see, e.g., Prior, 2003 ). Putting an emphasis on “topic,” however, can open up a further dimension of research, and that concerns the ways in which documents function in the everyday world. And as I have already hinted, when we focus on function, it becomes apparent that documents serve not merely as containers of content but very often as active agents in episodes of interaction and schemes of social organization. In this vein, one can begin to think of an ethnography of documentation. Therein, the key research questions revolve around the ways in which documents are used and integrated into specific kinds of organizational settings, as well as with how documents are exchanged and how they circulate within such settings. Clearly, documents carry content—words, images, plans, ideas, patterns, and so forth—but the manner in which such material is actually called upon and manipulated, and the way in which it functions, cannot be determined (though it may be constrained) by an analysis of content. Thus, Harper’s (1998) study of the use of economic reports inside the International Monetary Fund provides various examples of how “reports” can function to both differentiate and cohere work groups. In the same way. Henderson (1995) illustrates how engineering sketches and drawings can serve as what she calls conscription devices on the workshop floor.
Of course, documents constitute a form of what Latour (1986) would refer to as “immutable mobiles,” and with an eye on the mobility of documents, it is worth noting an emerging interest in histories of knowledge that seek to examine how the same documents have been received and absorbed quite differently by different cultural networks (see, e.g., Burke, 2000 ). A parallel concern has arisen with regard to the newly emergent “geographies of knowledge” (see, e.g., Livingstone, 2005 ). In the history of science, there has also been an expressed interest in the biography of scientific objects ( Latour, 1987 :262) or of “epistemic things” ( Rheinberger, 2000 )—tracing the history of objects independent of the “inventors” and “discoverers” to which such objects are conventionally attached. It is an approach that could be easily extended to the study of documents and is partly reflected in the earlier discussion concerning the meaning of the concept of well-being. Note how in all of these cases a key consideration is how words and documents as “things” circulate and translate from one culture to another; issues of content are secondary.
Clearly, studying how documents are used and how they circulate can constitute an important area of research in its own right. Yet even those who focus on document use can be overly anthropocentric and subsequently overemphasize the potency of human action in relation to written text. In that light, it is interesting to consider ways in which we might reverse that emphasis and instead to study the potency of text and the manner in which documents can influence organizational activities as well as reflect them. Thus Dorothy Winsor (1999) has, for example, examined the ways in which work orders drafted by engineers not only shape and fashion the practices and activities of engineering technicians but construct “two different worlds” on the workshop floor.
In light of this, I will suggest a typology (Table 18.3 ) of the ways in which documents have come to be and can be considered in social research.
While accepting that no form of categorical classification can capture the inherent fluidity of the world, its actors, and its objects, Table 18.3 aims to offer some understanding of the various ways in which documents have been dealt with by social researchers. Thus approaches that fit into cell 1 have been dominant in the history of social science generally. Therein documents (especially as text) have been analyzed and coded for what they contain in the way of descriptions, reports, images, representations, and accounts. In short, they have been scoured for evidence. Data-analysis strategies concentrate almost entirely on what is in the “text” (via various forms of content analysis). This emphasis on content is carried over into cell 2 type approaches with the key differences that analysis is concerned with how document content comes into being. The attention here is usually on the conceptual architecture and socio-technical procedures by means of which written reports, descriptions, statistical data, and so forth are generated. Various kinds of discourse analysis have been used to unravel the conceptual issues, while a focus on socio-technical and rule-based procedures by means of which clinical, police, social work, and other forms of records and reports are constructed has been well represented in the work of ethnomethodologists ( see Prior, 2011 ). In contrast, and in cell 3, the research focus is on the ways in which documents are called upon as a resource by various and different kinds of “user.” Here concerns with document content or how a document has come into being are marginal, and the analysis concentrates on the relationship between specific documents and their use or recruitment by identifiable human actors for purposeful ends. I have already pointed to some studies of the latter kind in earlier paragraphs (e.g., Henderson, 1995 ). Finally, the approaches that fit into cell 4 also position content as secondary. The emphasis here is on how documents as “things” function in schemes of social activity and with how such things can drive, rather than be driven by, human actors. In short, the spotlight is on the vita activa of documentation, and I have provided numerous example of documents as actors in other publications (see Prior, 2003 ; 2008 ; 2011 ).
Content analysis was a method originally developed to analyze mass media “messages” in an age of radio and newspaper print, and well before the digital age. Unfortunately, it struggles to break free of its origins and continues to be associated with the quantitative analysis of “communication.” Yet as I have argued, there is no rational reason why its use has to be restricted to such a narrow field, for it can be used to analyze printed text and interview data (as well as other forms of inscription) in various settings. What it cannot overcome is the fact that it is a method of analysis and not a method of data collection. However, as I have shown, it is an analytical strategy that can be integrated into a variety of research designs and approaches—cross-sectional and longitudinal survey designs, ethnography and other forms of qualitative design, and secondary analysis of pre-existing data sets. Even as a method of analysis it is flexible and can be used either independent of other methods or in conjunction with them. As we have seen, it is easily merged with various forms of discourse analysis and can be used as an exploratory method or as a means of verification. Above all, perhaps, it crosses the divide between “quantitative” and “qualitative” modes of inquiry in social research and offers a new dimension to the meaning of mixed-methods research. I recommend it.
Source : Prior (2008) .
Abbott, A. ( 1992 ). What do cases do? In C. C. Ragin , and H. S. Becker (Eds.). What is a case? Exploring the foundations of social inquiry . Cambridge: Cambridge University Press, 53–82.
Google Scholar
Google Preview
Altheide, D. L. ( 1987 ). Ethnographic Content Analysis. Qualitative Sociology , 10 (1): 65–77.
Arksey H , O’Malley L. ( 2005 ). Scoping studies: Towards a Methodological Framework. International Journal of Sociological Research Methodology , 8 : 19–32.
Babbie, E. ( 2013 ). The practice of social research. 13th ed . Belmont, CA: Wadsworth.
Bazerman, C. ( 1988 ). Shaping written knowledge. The genre and activity of the experimental article in science . Madison, WI: University of Wisconsin Press.
Becker, G. ( 1997 ). Disrupted lives. How people create meaning in a chaotic world . London: University of California Press.
Berelson, B. ( 1952 ). Content analysis in communication research . Glencoe, IL: Free Press.
Bowker, G. C. and Star, S. L. ( 1999 ). Sorting things out. Classification and its consequences . Cambridge, MA: MIT Press.
Braun, V. , Clarke, V. ( 2006 ). Using Thematic Analysis in Psychology. Qualitative Research in Psychology , 3 : 77–101.
Breuer, J. , Freud, S. ( 2001 ). Studies on Hysteria. In Strachey, L. (Ed.). The standard edition of the complete psychological works of Sigmund Freud . Vol. 2 . London: Vintage.
Bryman, A. ( 2008 ). Social research methods . 3rd Ed. Oxford: Oxford University Press.
Burke, P. ( 2000 ). A social history of knowledge. From Guttenberg to Diderot . Cambridge: Polity Press.
Bury, M. ( 1982 ). Chronic illness as biographical disruption. Sociology of Health and Illness , 4 : 167–182.
Carley, K. ( 1993 ). Coding choices for textual analysis. A comparison of content analysis and map analysis. Sociological Methodology , 23 : 75–126.
Charon, R. ( 2006 ). Narrative medicine. Honoring the stories of illness . New York: Oxford University Press.
Creswell, J. W. ( 2007 ). Designing and conducting mixed methods research . Thousand Oaks, CA: Sage.
Davison, C. , Davey-Smith, G. , Frankel, S. ( 1991 ). Lay epidemiology and the prevention paradox. Sociology of Health & Illness , 13 (1): 1–19.
Evans, M. , Prout, H. , Prior, L. , Tapper-Jones, L. , Butler, C. ( 2007 ). A qualitative Study of Lay Beliefs about Influenza, British Journal of General Practice , 57 :352–358.
Foucault, M. ( 1970 ). The Order of things. An archaeology of the human sciences . London: Tavistock.
Frank, A. ( 1995 ). The wounded storyteller: Body, illness, and ethics . Chicago: University of Chicago Press.
Gerring, J. ( 2004 ). What is a case study, and what is it good for? The American Political Science Review , 98 (2): 341–354.
Gilbert, G.N. , Mulkay, M. ( 1984 ). Opening Pandora’s box. A sociological analysis of scientists’ discourse . Cambridge: Cambridge University Press.
Glaser, B.G. , Strauss, A.L. ( 1967 ). The discovery of grounded theory. Strategies for qualitative research . New York: Aldine De Gruyter.
Goode, W. J. , Hatt, P. K. ( 1952 ). Methods in social research . New York: McGraw-Hill.
Greimas, A. J. ( 1970 ). Du Sens. Essays sémiotiques . Paris: Ėditions du Seuil.
Habermas, J. ( 1987 ). The theory of communicative action. Vol.2. A critique of functionalist reason . ( T. McCarthy , trans.). Cambridge: Polity Press.
Harper, R. ( 1998 ). Inside the IMF. An ethnography of documents, technology, and organizational action . London: Academic Press.
Henderson, K. ( 1995 ). The political career of a prototype. Visual representation in design engineering, Social Problems , 42 (2): 274–299.
Heritage, J. ( 1991 ). Garkfinkel and ethnomethodology . Cambridge. Polity Press.
Hydén, L-C. ( 1997 ). ‘ Illness and narrative ’, Sociology of Health & Illness , 19 (1): 48–69.
Kahn, R. , Cannell, C. ( 1957 ). The dynamics of interviewing. Theory, technique and cases . New York: Wiley.
Kay, L. E. ( 2000 ). Who wrote the book of life? A history of the genetic code . Stanford, CA: Stanford University Press.
Kleinman, A. , Eisenberg, L. , Good, B. ( 1978 ). Culture, illness & care, clinical lessons from anthropologic and cross-cultural research. Annals of Internal Medicine , 88 (2): 251–258.
Kracauer, S. ( 1952 ). The Challenge of Qualitative Content Analysis’, Public Opinion Quarterly, Special Issue on International Communications Research (1952–53) , 16 ( 4 ): 631–642.
Krippendorf, K. ( 2004 ). Content Analysis: An introduction to its methodology, 2nd ed . Thousand Oaks, CA: Sage Publications.
Latour, B. ( 1986 ). Visualization and Cognition: Thinking with Eyes and Hands, Knowledge and Society, Studies in Sociology of Culture, Past and Present , 6 : 1–40.
Latour, B. ( 1987 ). Science in Action. How to Follow Scientists and Engineers through Society . Milton Keynes: Open University Press.
Livingstone, D. N. ( 2005 ). Text, talk, and testimony: geographical reflections on scientific habits. An afterword, British Society for the History of Science . 38 (1): 93–100.
Luria, A.R. ( 1975 ). The man with the shattered world. A history of a brain wound . (Trans. L. Solotaroff ). Harmondsworth: Penguin.
Martin, A. , and Lynch, M. ( 2009 ). Counting things and counting people: The practices and politics of counting, Social Problems , 56 (2): 243–266.
Merton, R.K. ( 1968 ). Social theory and social structure . New York: Free Press.
Morgan, D. L. ( 1993 ). Qualitative content analysis. A guide to paths not taken, Qualitative Health Research , 2 : 112–121.
Morgan, D. L. ( 1998 ). Practical Strategies for combining qualitative and quantitative methods, Qualitative Health Research , 8 (3): 362–376.
Morris, P. G. , Prior, L. , Deb, S. , Lewis, G. , et al. ( 2005 ). Patients’ views on outcome following head injury: a qualitative study, BMC Family Practice , 6 :30.
Neuendorf, K. A. ( 2002 ). The content analysis guidebook . Thousand Oaks: CA: Sage.
Newman. J , and Vidler. E. ( 2006 ). Discriminating customers, responsible patients, empowered users: consumerism and the modernisation of health care, Journal of Social Policy , 35 (2): 193–210.
Office for National Statistics ( 2012 ) First ONS Annual Experimental Subjective Well-being Results . London: ONS. Available at: http://www.ons.gov.uk/ons/dcp171766_272294.pdf . Accessed July 2013.
Prior, L. ( 2003 ). Using documents in social research . London: Sage.
Prior, L. ( 2008 ). Repositioning Documents in Social Research. Sociology. Special Issue on Research Methods , 42 : 821–836.
Prior, L. ( 2011 ). Using documents and records in social research . 4 Vols . London: Sage.
Prior, L. Hughes, D. , Peckham, S. ( 2012 ) The discursive turn in policy analysis and the validation of policy stories, Journal of Social Policy , 41 (2): 271–289.
Prior, L. , Evans, M. , Prout, H. ( 2011 ). Talking about colds and flu: The lay diagnosis of two common illnesses among older British people, Social Science and Medicine , 73 : 922–928.
Ragin, C. C. , Becker, H. S. ( 1992 ). What is a case? Exploring the foundations of social inquiry . Cambridge: Cambridge University Press.
Rheinberger H.-J. , ( 2000 ). Cytoplasmic Particles. The Trajectory of a Scientific Object. In Daston, L. (Ed.). Biographies of scientific objects . Chicago: Chicago University Press, 270–294.
Ricoeur, P. ( 1984 ). Time and narrative . Vol. 1 . ( McLaughlin K. , Pellauer D. trans.) Chicago: University of Chicago Press.
Roe, E. ( 1994 ). Narrative policy analysis, theory and practice . Durham, NC: Duke University Press.
Ryan, G.W. , Bernard, H. R. ( 2000 ). Data management and analysis methods. In Denzin, N.K. , Lincoln, Y.S. (Eds.). Handbook of qualitative research . 2nd ed . Thousand Oaks, CA: Sage, 769–802.
Schutz, A. , Luckman, T. ( 1974 ). The structures of the life-world . ( Zaner, R. M. , Engelhardt, H.T. , trans.). London: Heinemann.
SPSS. ( 2007 ). Text Mining for Clementine . 12.0 User’s Guide. Chicago: SPSS.
Weber, R.P. ( 1990 ). Basic content analysis . Newbury Park: CA: Sage.
Winsor, D. ( 1999 ). Genre and activity systems. The role of documentation in maintaining and changing engineering activity systems. Written Communication , 16 (2): 200–224.
Zimmerman, D. H. , Pollner, M. ( 1971 ). The everyday world as a phenomenon. In Douglas, J. D. (Ed). Understanding everyday life . London: Routledge and Kegan Paul, 80–103.
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
- Technical Support
- Find My Rep
You are here
Qualitative Content Analysis Methods, Practice and Software
- Udo Kuckartz - Philipps-Universität Marburg, Germany
- Stefan Rädiker - Freelance Consultant
- Description
See what’s new to this edition by selecting the Features tab on this page. Should you need additional information or have questions regarding the HEOA information provided for this title, including what is new to this edition, please email [email protected] . Please include your name, contact information, and the name of the title for which you would like more information. For information on the HEOA, please go to http://ed.gov/policy/highered/leg/hea08/index.html .
For assistance with your order: Please email us at [email protected] or connect with your SAGE representative.
SAGE 2455 Teller Road Thousand Oaks, CA 91320 www.sagepub.com
The authors’ experience as teachers and practitioners of qualitative analysis methods shines throughout this clearly written, well-structured, and stimulating text. Written guidance, supported by an abundance of illustrative examples, provides a thorough foundation that supports strategies for systematically categorising and analysing qualitative data that build from simple description to complex typology development.
Udo Kuckartz and Stefan Rädiker, have authored an easy-to-understand text addressing qualitative research content analysis. This text has caused me to rethink qualitative data analysis and apply a category system to my own procedures. I applaud their logical approach, their detailed use of references, and their insight brought to qualitative research. This book will be seen for many years as a leading worldwide text on qualitative data analysis.
This book does a fantastic job of discussing the historical and theoretical foundations of QCA together with practical considerations for its use. The inclusion of real-world examples, advice for using qualitative data analysis software, and creative visual displays makes this revision a great resource for researchers analyzing qualitative data within qualitative and mixed methods approaches.
A clear guide for students in the social sciences wishing to engage with qualitative research; utilised for those on UG and PG studies.
Good range of examples
good resource and guide for students
A well structured and written text that aims to simplify the process of research and and particularly qualitative research. This text does not appear as daunting as some research methods texts, which do make some students recoil from accessing some research methods texts. A good and easy to read text, which is important for students attempting their first research project.
A well considered guide to various approaches to content analysis, with clear and helpful information for students and novice researchers.
Still working on it but hoping to adopt it to enhance ethnographic research programs
Preview this book
For instructors.
Please select a format:
Select a Purchasing Option
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What Is Qualitative Research? | Methods & Examples
What Is Qualitative Research? | Methods & Examples
Published on June 19, 2020 by Pritha Bhandari . Revised on June 22, 2023.
Qualitative research involves collecting and analyzing non-numerical data (e.g., text, video, or audio) to understand concepts, opinions, or experiences. It can be used to gather in-depth insights into a problem or generate new ideas for research.
Qualitative research is the opposite of quantitative research , which involves collecting and analyzing numerical data for statistical analysis.
Qualitative research is commonly used in the humanities and social sciences, in subjects such as anthropology, sociology, education, health sciences, history, etc.
- How does social media shape body image in teenagers?
- How do children and adults interpret healthy eating in the UK?
- What factors influence employee retention in a large organization?
- How is anxiety experienced around the world?
- How can teachers integrate social issues into science curriculums?
Table of contents
Approaches to qualitative research, qualitative research methods, qualitative data analysis, advantages of qualitative research, disadvantages of qualitative research, other interesting articles, frequently asked questions about qualitative research.
Qualitative research is used to understand how people experience the world. While there are many approaches to qualitative research, they tend to be flexible and focus on retaining rich meaning when interpreting data.
Common approaches include grounded theory, ethnography , action research , phenomenological research, and narrative research. They share some similarities, but emphasize different aims and perspectives.
Note that qualitative research is at risk for certain research biases including the Hawthorne effect , observer bias , recall bias , and social desirability bias . While not always totally avoidable, awareness of potential biases as you collect and analyze your data can prevent them from impacting your work too much.
Prevent plagiarism. Run a free check.
Each of the research approaches involve using one or more data collection methods . These are some of the most common qualitative methods:
- Observations: recording what you have seen, heard, or encountered in detailed field notes.
- Interviews: personally asking people questions in one-on-one conversations.
- Focus groups: asking questions and generating discussion among a group of people.
- Surveys : distributing questionnaires with open-ended questions.
- Secondary research: collecting existing data in the form of texts, images, audio or video recordings, etc.
- You take field notes with observations and reflect on your own experiences of the company culture.
- You distribute open-ended surveys to employees across all the company’s offices by email to find out if the culture varies across locations.
- You conduct in-depth interviews with employees in your office to learn about their experiences and perspectives in greater detail.
Qualitative researchers often consider themselves “instruments” in research because all observations, interpretations and analyses are filtered through their own personal lens.
For this reason, when writing up your methodology for qualitative research, it’s important to reflect on your approach and to thoroughly explain the choices you made in collecting and analyzing the data.
Qualitative data can take the form of texts, photos, videos and audio. For example, you might be working with interview transcripts, survey responses, fieldnotes, or recordings from natural settings.
Most types of qualitative data analysis share the same five steps:
- Prepare and organize your data. This may mean transcribing interviews or typing up fieldnotes.
- Review and explore your data. Examine the data for patterns or repeated ideas that emerge.
- Develop a data coding system. Based on your initial ideas, establish a set of codes that you can apply to categorize your data.
- Assign codes to the data. For example, in qualitative survey analysis, this may mean going through each participant’s responses and tagging them with codes in a spreadsheet. As you go through your data, you can create new codes to add to your system if necessary.
- Identify recurring themes. Link codes together into cohesive, overarching themes.
There are several specific approaches to analyzing qualitative data. Although these methods share similar processes, they emphasize different concepts.
Qualitative research often tries to preserve the voice and perspective of participants and can be adjusted as new research questions arise. Qualitative research is good for:
- Flexibility
The data collection and analysis process can be adapted as new ideas or patterns emerge. They are not rigidly decided beforehand.
- Natural settings
Data collection occurs in real-world contexts or in naturalistic ways.
- Meaningful insights
Detailed descriptions of people’s experiences, feelings and perceptions can be used in designing, testing or improving systems or products.
- Generation of new ideas
Open-ended responses mean that researchers can uncover novel problems or opportunities that they wouldn’t have thought of otherwise.
Researchers must consider practical and theoretical limitations in analyzing and interpreting their data. Qualitative research suffers from:
- Unreliability
The real-world setting often makes qualitative research unreliable because of uncontrolled factors that affect the data.
- Subjectivity
Due to the researcher’s primary role in analyzing and interpreting data, qualitative research cannot be replicated . The researcher decides what is important and what is irrelevant in data analysis, so interpretations of the same data can vary greatly.
- Limited generalizability
Small samples are often used to gather detailed data about specific contexts. Despite rigorous analysis procedures, it is difficult to draw generalizable conclusions because the data may be biased and unrepresentative of the wider population .
- Labor-intensive
Although software can be used to manage and record large amounts of text, data analysis often has to be checked or performed manually.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square goodness of fit test
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
There are five common approaches to qualitative research :
- Grounded theory involves collecting data in order to develop new theories.
- Ethnography involves immersing yourself in a group or organization to understand its culture.
- Narrative research involves interpreting stories to understand how people make sense of their experiences and perceptions.
- Phenomenological research involves investigating phenomena through people’s lived experiences.
- Action research links theory and practice in several cycles to drive innovative changes.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2023, June 22). What Is Qualitative Research? | Methods & Examples. Scribbr. Retrieved April 3, 2024, from https://www.scribbr.com/methodology/qualitative-research/
Is this article helpful?

Pritha Bhandari
Other students also liked, qualitative vs. quantitative research | differences, examples & methods, how to do thematic analysis | step-by-step guide & examples, unlimited academic ai-proofreading.
✔ Document error-free in 5minutes ✔ Unlimited document corrections ✔ Specialized in correcting academic texts
- Privacy Policy
Buy Me a Coffee
Home » Qualitative Research – Methods, Analysis Types and Guide
Qualitative Research – Methods, Analysis Types and Guide
Table of Contents

Qualitative Research
Qualitative research is a type of research methodology that focuses on exploring and understanding people’s beliefs, attitudes, behaviors, and experiences through the collection and analysis of non-numerical data. It seeks to answer research questions through the examination of subjective data, such as interviews, focus groups, observations, and textual analysis.
Qualitative research aims to uncover the meaning and significance of social phenomena, and it typically involves a more flexible and iterative approach to data collection and analysis compared to quantitative research. Qualitative research is often used in fields such as sociology, anthropology, psychology, and education.
Qualitative Research Methods

Qualitative Research Methods are as follows:
One-to-One Interview
This method involves conducting an interview with a single participant to gain a detailed understanding of their experiences, attitudes, and beliefs. One-to-one interviews can be conducted in-person, over the phone, or through video conferencing. The interviewer typically uses open-ended questions to encourage the participant to share their thoughts and feelings. One-to-one interviews are useful for gaining detailed insights into individual experiences.
Focus Groups
This method involves bringing together a group of people to discuss a specific topic in a structured setting. The focus group is led by a moderator who guides the discussion and encourages participants to share their thoughts and opinions. Focus groups are useful for generating ideas and insights, exploring social norms and attitudes, and understanding group dynamics.
Ethnographic Studies
This method involves immersing oneself in a culture or community to gain a deep understanding of its norms, beliefs, and practices. Ethnographic studies typically involve long-term fieldwork and observation, as well as interviews and document analysis. Ethnographic studies are useful for understanding the cultural context of social phenomena and for gaining a holistic understanding of complex social processes.
Text Analysis
This method involves analyzing written or spoken language to identify patterns and themes. Text analysis can be quantitative or qualitative. Qualitative text analysis involves close reading and interpretation of texts to identify recurring themes, concepts, and patterns. Text analysis is useful for understanding media messages, public discourse, and cultural trends.
This method involves an in-depth examination of a single person, group, or event to gain an understanding of complex phenomena. Case studies typically involve a combination of data collection methods, such as interviews, observations, and document analysis, to provide a comprehensive understanding of the case. Case studies are useful for exploring unique or rare cases, and for generating hypotheses for further research.
Process of Observation
This method involves systematically observing and recording behaviors and interactions in natural settings. The observer may take notes, use audio or video recordings, or use other methods to document what they see. Process of observation is useful for understanding social interactions, cultural practices, and the context in which behaviors occur.
Record Keeping
This method involves keeping detailed records of observations, interviews, and other data collected during the research process. Record keeping is essential for ensuring the accuracy and reliability of the data, and for providing a basis for analysis and interpretation.
This method involves collecting data from a large sample of participants through a structured questionnaire. Surveys can be conducted in person, over the phone, through mail, or online. Surveys are useful for collecting data on attitudes, beliefs, and behaviors, and for identifying patterns and trends in a population.
Qualitative data analysis is a process of turning unstructured data into meaningful insights. It involves extracting and organizing information from sources like interviews, focus groups, and surveys. The goal is to understand people’s attitudes, behaviors, and motivations
Qualitative Research Analysis Methods
Qualitative Research analysis methods involve a systematic approach to interpreting and making sense of the data collected in qualitative research. Here are some common qualitative data analysis methods:
Thematic Analysis
This method involves identifying patterns or themes in the data that are relevant to the research question. The researcher reviews the data, identifies keywords or phrases, and groups them into categories or themes. Thematic analysis is useful for identifying patterns across multiple data sources and for generating new insights into the research topic.
Content Analysis
This method involves analyzing the content of written or spoken language to identify key themes or concepts. Content analysis can be quantitative or qualitative. Qualitative content analysis involves close reading and interpretation of texts to identify recurring themes, concepts, and patterns. Content analysis is useful for identifying patterns in media messages, public discourse, and cultural trends.
Discourse Analysis
This method involves analyzing language to understand how it constructs meaning and shapes social interactions. Discourse analysis can involve a variety of methods, such as conversation analysis, critical discourse analysis, and narrative analysis. Discourse analysis is useful for understanding how language shapes social interactions, cultural norms, and power relationships.
Grounded Theory Analysis
This method involves developing a theory or explanation based on the data collected. Grounded theory analysis starts with the data and uses an iterative process of coding and analysis to identify patterns and themes in the data. The theory or explanation that emerges is grounded in the data, rather than preconceived hypotheses. Grounded theory analysis is useful for understanding complex social phenomena and for generating new theoretical insights.
Narrative Analysis
This method involves analyzing the stories or narratives that participants share to gain insights into their experiences, attitudes, and beliefs. Narrative analysis can involve a variety of methods, such as structural analysis, thematic analysis, and discourse analysis. Narrative analysis is useful for understanding how individuals construct their identities, make sense of their experiences, and communicate their values and beliefs.
Phenomenological Analysis
This method involves analyzing how individuals make sense of their experiences and the meanings they attach to them. Phenomenological analysis typically involves in-depth interviews with participants to explore their experiences in detail. Phenomenological analysis is useful for understanding subjective experiences and for developing a rich understanding of human consciousness.
Comparative Analysis
This method involves comparing and contrasting data across different cases or groups to identify similarities and differences. Comparative analysis can be used to identify patterns or themes that are common across multiple cases, as well as to identify unique or distinctive features of individual cases. Comparative analysis is useful for understanding how social phenomena vary across different contexts and groups.
Applications of Qualitative Research
Qualitative research has many applications across different fields and industries. Here are some examples of how qualitative research is used:
- Market Research: Qualitative research is often used in market research to understand consumer attitudes, behaviors, and preferences. Researchers conduct focus groups and one-on-one interviews with consumers to gather insights into their experiences and perceptions of products and services.
- Health Care: Qualitative research is used in health care to explore patient experiences and perspectives on health and illness. Researchers conduct in-depth interviews with patients and their families to gather information on their experiences with different health care providers and treatments.
- Education: Qualitative research is used in education to understand student experiences and to develop effective teaching strategies. Researchers conduct classroom observations and interviews with students and teachers to gather insights into classroom dynamics and instructional practices.
- Social Work : Qualitative research is used in social work to explore social problems and to develop interventions to address them. Researchers conduct in-depth interviews with individuals and families to understand their experiences with poverty, discrimination, and other social problems.
- Anthropology : Qualitative research is used in anthropology to understand different cultures and societies. Researchers conduct ethnographic studies and observe and interview members of different cultural groups to gain insights into their beliefs, practices, and social structures.
- Psychology : Qualitative research is used in psychology to understand human behavior and mental processes. Researchers conduct in-depth interviews with individuals to explore their thoughts, feelings, and experiences.
- Public Policy : Qualitative research is used in public policy to explore public attitudes and to inform policy decisions. Researchers conduct focus groups and one-on-one interviews with members of the public to gather insights into their perspectives on different policy issues.
How to Conduct Qualitative Research
Here are some general steps for conducting qualitative research:
- Identify your research question: Qualitative research starts with a research question or set of questions that you want to explore. This question should be focused and specific, but also broad enough to allow for exploration and discovery.
- Select your research design: There are different types of qualitative research designs, including ethnography, case study, grounded theory, and phenomenology. You should select a design that aligns with your research question and that will allow you to gather the data you need to answer your research question.
- Recruit participants: Once you have your research question and design, you need to recruit participants. The number of participants you need will depend on your research design and the scope of your research. You can recruit participants through advertisements, social media, or through personal networks.
- Collect data: There are different methods for collecting qualitative data, including interviews, focus groups, observation, and document analysis. You should select the method or methods that align with your research design and that will allow you to gather the data you need to answer your research question.
- Analyze data: Once you have collected your data, you need to analyze it. This involves reviewing your data, identifying patterns and themes, and developing codes to organize your data. You can use different software programs to help you analyze your data, or you can do it manually.
- Interpret data: Once you have analyzed your data, you need to interpret it. This involves making sense of the patterns and themes you have identified, and developing insights and conclusions that answer your research question. You should be guided by your research question and use your data to support your conclusions.
- Communicate results: Once you have interpreted your data, you need to communicate your results. This can be done through academic papers, presentations, or reports. You should be clear and concise in your communication, and use examples and quotes from your data to support your findings.
Examples of Qualitative Research
Here are some real-time examples of qualitative research:
- Customer Feedback: A company may conduct qualitative research to understand the feedback and experiences of its customers. This may involve conducting focus groups or one-on-one interviews with customers to gather insights into their attitudes, behaviors, and preferences.
- Healthcare : A healthcare provider may conduct qualitative research to explore patient experiences and perspectives on health and illness. This may involve conducting in-depth interviews with patients and their families to gather information on their experiences with different health care providers and treatments.
- Education : An educational institution may conduct qualitative research to understand student experiences and to develop effective teaching strategies. This may involve conducting classroom observations and interviews with students and teachers to gather insights into classroom dynamics and instructional practices.
- Social Work: A social worker may conduct qualitative research to explore social problems and to develop interventions to address them. This may involve conducting in-depth interviews with individuals and families to understand their experiences with poverty, discrimination, and other social problems.
- Anthropology : An anthropologist may conduct qualitative research to understand different cultures and societies. This may involve conducting ethnographic studies and observing and interviewing members of different cultural groups to gain insights into their beliefs, practices, and social structures.
- Psychology : A psychologist may conduct qualitative research to understand human behavior and mental processes. This may involve conducting in-depth interviews with individuals to explore their thoughts, feelings, and experiences.
- Public Policy: A government agency or non-profit organization may conduct qualitative research to explore public attitudes and to inform policy decisions. This may involve conducting focus groups and one-on-one interviews with members of the public to gather insights into their perspectives on different policy issues.
Purpose of Qualitative Research
The purpose of qualitative research is to explore and understand the subjective experiences, behaviors, and perspectives of individuals or groups in a particular context. Unlike quantitative research, which focuses on numerical data and statistical analysis, qualitative research aims to provide in-depth, descriptive information that can help researchers develop insights and theories about complex social phenomena.
Qualitative research can serve multiple purposes, including:
- Exploring new or emerging phenomena : Qualitative research can be useful for exploring new or emerging phenomena, such as new technologies or social trends. This type of research can help researchers develop a deeper understanding of these phenomena and identify potential areas for further study.
- Understanding complex social phenomena : Qualitative research can be useful for exploring complex social phenomena, such as cultural beliefs, social norms, or political processes. This type of research can help researchers develop a more nuanced understanding of these phenomena and identify factors that may influence them.
- Generating new theories or hypotheses: Qualitative research can be useful for generating new theories or hypotheses about social phenomena. By gathering rich, detailed data about individuals’ experiences and perspectives, researchers can develop insights that may challenge existing theories or lead to new lines of inquiry.
- Providing context for quantitative data: Qualitative research can be useful for providing context for quantitative data. By gathering qualitative data alongside quantitative data, researchers can develop a more complete understanding of complex social phenomena and identify potential explanations for quantitative findings.
When to use Qualitative Research
Here are some situations where qualitative research may be appropriate:
- Exploring a new area: If little is known about a particular topic, qualitative research can help to identify key issues, generate hypotheses, and develop new theories.
- Understanding complex phenomena: Qualitative research can be used to investigate complex social, cultural, or organizational phenomena that are difficult to measure quantitatively.
- Investigating subjective experiences: Qualitative research is particularly useful for investigating the subjective experiences of individuals or groups, such as their attitudes, beliefs, values, or emotions.
- Conducting formative research: Qualitative research can be used in the early stages of a research project to develop research questions, identify potential research participants, and refine research methods.
- Evaluating interventions or programs: Qualitative research can be used to evaluate the effectiveness of interventions or programs by collecting data on participants’ experiences, attitudes, and behaviors.
Characteristics of Qualitative Research
Qualitative research is characterized by several key features, including:
- Focus on subjective experience: Qualitative research is concerned with understanding the subjective experiences, beliefs, and perspectives of individuals or groups in a particular context. Researchers aim to explore the meanings that people attach to their experiences and to understand the social and cultural factors that shape these meanings.
- Use of open-ended questions: Qualitative research relies on open-ended questions that allow participants to provide detailed, in-depth responses. Researchers seek to elicit rich, descriptive data that can provide insights into participants’ experiences and perspectives.
- Sampling-based on purpose and diversity: Qualitative research often involves purposive sampling, in which participants are selected based on specific criteria related to the research question. Researchers may also seek to include participants with diverse experiences and perspectives to capture a range of viewpoints.
- Data collection through multiple methods: Qualitative research typically involves the use of multiple data collection methods, such as in-depth interviews, focus groups, and observation. This allows researchers to gather rich, detailed data from multiple sources, which can provide a more complete picture of participants’ experiences and perspectives.
- Inductive data analysis: Qualitative research relies on inductive data analysis, in which researchers develop theories and insights based on the data rather than testing pre-existing hypotheses. Researchers use coding and thematic analysis to identify patterns and themes in the data and to develop theories and explanations based on these patterns.
- Emphasis on researcher reflexivity: Qualitative research recognizes the importance of the researcher’s role in shaping the research process and outcomes. Researchers are encouraged to reflect on their own biases and assumptions and to be transparent about their role in the research process.
Advantages of Qualitative Research
Qualitative research offers several advantages over other research methods, including:
- Depth and detail: Qualitative research allows researchers to gather rich, detailed data that provides a deeper understanding of complex social phenomena. Through in-depth interviews, focus groups, and observation, researchers can gather detailed information about participants’ experiences and perspectives that may be missed by other research methods.
- Flexibility : Qualitative research is a flexible approach that allows researchers to adapt their methods to the research question and context. Researchers can adjust their research methods in real-time to gather more information or explore unexpected findings.
- Contextual understanding: Qualitative research is well-suited to exploring the social and cultural context in which individuals or groups are situated. Researchers can gather information about cultural norms, social structures, and historical events that may influence participants’ experiences and perspectives.
- Participant perspective : Qualitative research prioritizes the perspective of participants, allowing researchers to explore subjective experiences and understand the meanings that participants attach to their experiences.
- Theory development: Qualitative research can contribute to the development of new theories and insights about complex social phenomena. By gathering rich, detailed data and using inductive data analysis, researchers can develop new theories and explanations that may challenge existing understandings.
- Validity : Qualitative research can offer high validity by using multiple data collection methods, purposive and diverse sampling, and researcher reflexivity. This can help ensure that findings are credible and trustworthy.
Limitations of Qualitative Research
Qualitative research also has some limitations, including:
- Subjectivity : Qualitative research relies on the subjective interpretation of researchers, which can introduce bias into the research process. The researcher’s perspective, beliefs, and experiences can influence the way data is collected, analyzed, and interpreted.
- Limited generalizability: Qualitative research typically involves small, purposive samples that may not be representative of larger populations. This limits the generalizability of findings to other contexts or populations.
- Time-consuming: Qualitative research can be a time-consuming process, requiring significant resources for data collection, analysis, and interpretation.
- Resource-intensive: Qualitative research may require more resources than other research methods, including specialized training for researchers, specialized software for data analysis, and transcription services.
- Limited reliability: Qualitative research may be less reliable than quantitative research, as it relies on the subjective interpretation of researchers. This can make it difficult to replicate findings or compare results across different studies.
- Ethics and confidentiality: Qualitative research involves collecting sensitive information from participants, which raises ethical concerns about confidentiality and informed consent. Researchers must take care to protect the privacy and confidentiality of participants and obtain informed consent.
Also see Research Methods
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Case Study – Methods, Examples and Guide

Observational Research – Methods and Guide

Quantitative Research – Methods, Types and...

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide
- Open access
- Published: 28 March 2024
Using the consolidated Framework for Implementation Research to integrate innovation recipients’ perspectives into the implementation of a digital version of the spinal cord injury health maintenance tool: a qualitative analysis
- John A Bourke 1 , 2 , 3 ,
- K. Anne Sinnott Jerram 1 , 2 ,
- Mohit Arora 1 , 2 ,
- Ashley Craig 1 , 2 &
- James W Middleton 1 , 2 , 4 , 5
BMC Health Services Research volume 24 , Article number: 390 ( 2024 ) Cite this article
111 Accesses
Metrics details
Despite advances in managing secondary health complications after spinal cord injury (SCI), challenges remain in developing targeted community health strategies. In response, the SCI Health Maintenance Tool (SCI-HMT) was developed between 2018 and 2023 in NSW, Australia to support people with SCI and their general practitioners (GPs) to promote better community self-management. Successful implementation of innovations such as the SCI-HMT are determined by a range of contextual factors, including the perspectives of the innovation recipients for whom the innovation is intended to benefit, who are rarely included in the implementation process. During the digitizing of the booklet version of the SCI-HMT into a website and App, we used the Consolidated Framework for Implementation Research (CFIR) as a tool to guide collection and analysis of qualitative data from a range of innovation recipients to promote equity and to inform actionable findings designed to improve the implementation of the SCI-HMT.
Data from twenty-three innovation recipients in the development phase of the SCI-HMT were coded to the five CFIR domains to inform a semi-structured interview guide. This interview guide was used to prospectively explore the barriers and facilitators to planned implementation of the digital SCI-HMT with six health professionals and four people with SCI. A team including researchers and innovation recipients then interpreted these data to produce a reflective statement matched to each domain. Each reflective statement prefaced an actionable finding, defined as alterations that can be made to a program to improve its adoption into practice.
Five reflective statements synthesizing all participant data and linked to an actionable finding to improve the implementation plan were created. Using the CFIR to guide our research emphasized how partnership is the key theme connecting all implementation facilitators, for example ensuring that the tone, scope, content and presentation of the SCI-HMT balanced the needs of innovation recipients alongside the provision of evidence-based clinical information.
Conclusions
Understanding recipient perspectives is an essential contextual factor to consider when developing implementation strategies for healthcare innovations. The revised CFIR provided an effective, systematic method to understand, integrate and value recipient perspectives in the development of an implementation strategy for the SCI-HMT.
Trial registration
Peer Review reports
Injury to the spinal cord can occur through traumatic causes (e.g., falls or motor vehicle accidents) or from non-traumatic disease or disorder (e.g., tumours or infections) [ 1 ]. The onset of a spinal cord injury (SCI) is often sudden, yet the consequences are lifelong. The impact of a SCI is devastating, with effects on sensory and motor function, bladder and bowel function, sexual function, level of independence, community participation and quality of life [ 2 ]. In order to maintain good health, wellbeing and productivity in society, people with SCI must develop self-management skills and behaviours to manage their newly acquired chronic health condition [ 3 ]. Given the increasing emphasis on primary health care and community management of chronic health conditions, like SCI, there is a growing responsibility on all parties to promote good health practices and minimize the risks of common health complications in their communities.
To address this need, the Spinal Cord Injury Health Maintenance Tool (SCI-HMT) was co-designed between 2018 and 2023 with people living with SCI and their General Practitioners (GPs) in NSW, Australia [ 4 ] The aim of the SCI-HMT is to support self-management of the most common and arguably avoidable potentially life-threatening complications associated with SCI, such as mental health crises, autonomic dysreflexia, kidney infections and pressure injuries. The SCI-HMT provides comprehensible information with resources about the six highest priority health areas related to SCI (as indicated by people with SCI and GPs) and was developed over two phases. Phase 1 focused on developing a booklet version and Phase 2 focused on digitizing this content into a website and smartphone app [ 4 , 5 ].
Enabling the successful implementation of evidence-based innovations such as the SCI-HMT is inevitably influenced by contextual factors: those dynamic and diverse array of forces within real-world settings working for or against implementation efforts [ 6 ]. Contextual factors often include background environmental elements in which an intervention is situated, for example (but not limited to) demographics, clinical environments, organisational culture, legislation, and cultural norms [ 7 ]. Understanding the wider context is necessary to identify and potentially mitigate various challenges to the successful implementation of those innovations. Such work is the focus of determinant frameworks, which focus on categorising or classing groups of contextual determinants that are thought to predict or demonstrate an effect on implementation effectiveness to better understand factors that might influence implementation outcomes [ 8 ].
One of the most highly cited determinant frameworks is the Consolidated Framework for Implementation Research (CFIR) [ 9 ], which is often posited as an ideal framework for pre-implementation preparation. Originally published in 2009, the CFIR has recently been subject to an update by its original authors, which included a literature review, survey of users, and the creation of an outcome addendum [ 10 , 11 ]. A key contribution from this revision was the need for a greater focus on the place of innovation recipients, defined as the constituency for whom the innovation is being designed to benefit; for example, patients receiving treatment, students receiving a learning activity. Traditionally, innovation recipients are rarely positioned as key decision-makers or innovation implementers [ 8 ], and as a consequence, have not often been included in the application of research using frameworks, such as the CFIR [ 11 ].
Such power imbalances within the intersection of healthcare and research, particularly between those receiving and delivering such services and those designing such services, have been widely reported [ 12 , 13 ]. There are concerted efforts within health service development, health research and health research funding, to rectify this power imbalance [ 14 , 15 ]. Importantly, such efforts to promote increased equitable population impact are now being explicitly discussed within the implementation science literature. For example, Damschroder et al. [ 11 ] has recently argued for researchers to use the CFIR to collect data from innovation recipients, and that, ultimately, “equitable population impact is only possible when recipients are integrally involved in implementation and all key constituencies share power and make decisions together” (p. 7). Indeed, increased equity between key constituencies and partnering with innovation recipients promotes the likelihood of sustainable adoption of an innovation [ 4 , 12 , 14 ].
There is a paucity of work using the updated CFIR to include and understand innovation recipients’ perspectives. To address this gap, this paper reports on a process of using the CFIR to guide the collection of qualitative data from a range of innovation recipients within a wider co-design mixed methods study examining the development and implementation of SCI-HMT. The innovation recipients in our research are people living with SCI and GPs. Guided by the CFIR domains (shown in the supplementary material), we used reflexive thematic analysis [ 16 ]to summarize data into reflective summaries, which served to inform actionable findings designed to improve implementation of the SCI-HMT.
The procedure for this research is multi-stepped and is summarized in Fig. 1 . First, we mapped retrospective qualitative data collected during the development of the SCI-HMT [ 4 ] against the five domains of the CFIR in order to create a semi-structured interview guide (Step 1). Then, we used this interview guide to collect prospective data from health professionals and people with SCI during the development of the digital version of the SCI-HMT (Step 2) to identify implementation barriers and facilitators. This enabled us to interpret a reflective summary statement for each CFIR domain. Lastly, we developed an actionable finding for each domain summary. The first (RESP/18/212) and second phase (2019/ETH13961) of the project received ethical approval from The Northern Sydney Local Health District Human Research Ethics Committee. The reporting of this study was conducted in line with the consolidated Criteria for Reporting Qualitative Research (COREQ) guidelines [ 17 ]. All methods were performed in accordance with the relevant guidelines and regulations.

Procedure of synthesising datasets to inform reflective statements and actionable findings. a Two health professionals had a SCI (one being JAB); b Two co-design researchers had a SCI (one being JAB)
Step one: retrospective data collection and analysis
We began by retrospectively analyzing the data set (interview and focus group transcripts) from the previously reported qualitative study from the development phase of the SCI-HMT [ 4 ]. This analysis was undertaken by two team members (KASJ and MA). KASJ has a background in co-design research. Transcript data were uploaded into NVivo software (Version 12: QSR International Pty Ltd) and a directed content analysis approach [ 18 ] was applied to analyze categorized data a priori according to the original 2009 CFIR domains (intervention characteristics, outer setting, inner setting, characteristics of individuals, and process of implementation) described by Damschroder et al. [ 9 ]. This categorized data were summarized and informed the specific questions of a semi-structured interview guide. The final output of step one was an interview guide with context-specific questions arranged according to the CFIR domains (see supplementary file 1). The interview was tested with two people with SCI and one health professional.
Step two: prospective data collection and analysis
In the second step, semi-structured interviews were conducted by KASJ (with MA as observer) with consenting healthcare professionals who had previously contributed to the development of the SCI-HMT. Healthcare professionals included GPs, Nurse Consultants, Specialist Physiotherapists, along with Health Researchers (one being JAB). In addition, a focus group was conducted with consenting individuals with SCI who had contributed to the SCI-HMT design and development phase. The interview schedule designed in step one above guided data collection in all interviews and the focus group.
The focus group and interviews were conducted online, audio recorded, transcribed verbatim and uploaded to NVivo software (Version 12: QSR International Pty Ltd). All data were subject to reflexive, inductive and deductive thematic analysis [ 16 , 19 ] to better understand participants’ perspectives regarding the potential implementation of the SCI-HMT. First, one team member (KASJ) read transcripts and began a deductive analysis whereby data were organized into CFIR domains-specific dataset. Second, KASJ and JAB analyzed this domain-specific dataset to inductively interpret a reflective statement which served to summarise all participant responses to each domain. The final output of step two was a reflective summary statement for each CFIR domain.
Step three: data synthesis
In the third step we aimed to co-create an actionable finding (defined as tangible alteration that can be made to a program, in this case the SCI-HMT [ 20 ]) based on each domain-specific reflective statement. To achieve this, three codesign researchers (KAS and JAB with one person with SCI from Step 2 (deidentified)) focused on operationalising each reflective statement into a recommended modification for the digital version of the SCI-HMT. This was an iterative process guided by the specific CFIR domain and construct definitions, which we deemed salient and relevant to each reflective statement (see Table 2 for example). Data synthesis involved line by line analysis, group discussion, and repeated refinement of actionable findings. A draft synthesis was shared with SCI-HMT developers (JWM and MA) and refinement continued until consensus was agreed on. The final outputs of step three were an actionable finding related to each reflective statement for each CFIR domain.
The characteristics of both the retrospective and prospective study participants are shown in Table 1 . The retrospective data included data from a total of 23 people: 19 people with SCI and four GPs. Of the 19 people with SCI, 12 participated in semi-structured interviews, seven participated in the first focus group, and four returned to the second focus group. In step 2, four people with SCI participated in a focus group and six healthcare professionals participated in one-on-one semi-structured interviews. Two of the healthcare professionals (a GP and a registrar) had lived experience of SCI, as did one researcher (JAB). All interviews and focus groups were conducted either online or in-person and ranged in length between 60 and 120 min.
In our overall synthesis, we actively interpreted five reflective statements based on the updated CFIR domain and construct definitions by Damschroder et al. [ 11 ]. Table 2 provides a summary of how we linked the updated CFIR domain and construct definitions to the reflective statements. We demonstrate this process of co-creation below, including illustrative quotes from participants. Importantly, we guide readers to the actionable findings related to each reflective statement in Table 2 . Each actionable statement represents an alteration that can be made to a program to improve its adoption into practice.
Participants acknowledged that self-management is a major undertaking and very demanding, as one person with SCI said, “ we need to be informed without being terrified and overwhelmed”. Participants felt the HMT could indeed be adapted, tailored, refined, or reinvented to meet local needs. For example, another person with SCI remarked:
“Education needs to be from the get-go but in bite sized pieces from all quarters when readiness is most apparent… at all time points , [not just as a] a newbie tool or for people with [long-term impairment] ” (person with SCI_02).
Therefore, the SCI-HMT had to balance complexity of content while still being accessible and engaging, and required input from both experts in the field and those with lived experience of SCI, for example, a clinical nurse specialist suggested:
“it’s essential [the SCI-HMT] is written by experts in the field as well as with collaboration with people who have had a, you know, the lived experience of SCI” (healthcare professional_03).
Furthermore, the points of contact with healthcare for a person with SCI can be challenging to navigate and the SCI-HMT has the potential to facilitate a smoother engagement process and improve communication between people with SCI and healthcare services. As a GP suggested:
“we need a tool like this to link to that pathway model in primary health care , [the SCI-HMT] it’s a great tool, something that everyone can read and everyone’s reading the same thing” (healthcare professional_05).
Participants highlighted that the ability of the SCI-HMT to facilitate effective communication was very much dependent on the delivery format. The idea of digitizing the SCI-HMT garnered equal support from people with SCI and health care professionals, with one participant with SCI deeming it to be “ essential” ( person with SCI_01) and a health professional suggesting a “digitalized version will be an advantage for most people” (healthcare professional_02).
Outer setting
There was strong interest expressed by both people with SCI and healthcare professionals in using the SCI-HMT. The fundamental premise was that knowledge is power and the SCI-HMT would have strong utility in post-acute rehabilitation services, as well as primary care. As a person with SCI said,
“ we need to leave the [spinal unit] to return to the community with sufficient knowledge, and to know the value of that knowledge and then need to ensure primary healthcare provider [s] are best informed” (person with SCI_04).
The value of the SCI-HMT in facilitating clear and effective communication and shared decision-making between healthcare professionals and people with SCI was also highlighted, as shown by the remarks of an acute nurse specialist:
“I think this tool is really helpful for the consumer and the GP to work together to prioritize particular tests that a patient might need and what the regularity of that is” (healthcare professional_03).
Engaging with SCI peer support networks to promote the SCI-HMT was considered crucial, as one person with SCI emphasized when asked how the SCI-HMT might be best executed in the community, “…peers, peers and peers” (person with SCI_01). Furthermore, the layering of content made possible in the digitalized version will allow for the issue of approachability in terms of readiness for change, as another person with SCI said:
“[putting content into a digital format] is essential and required and there is a need to put summarized content in an App with links to further web-based information… it’s not likely to be accessed otherwise” (person with SCI_02).
Inner setting
Participants acknowledged that self-management of health and well-being is substantial and demanding. It was suggested that the scope, tone, and complexity of the SCI-HMT, while necessary, could potentially be resisted by people with SCI if they felt overwhelmed, as one person with SCI described:
“a manual that is really long and wordy, like, it’s [a] health metric… they maybe lack the health literacy to, to consume the content then yes, it would impede their readiness for [self-management]” (person with SCI_02).
Having support from their GPs was considered essential, and the HMT could enable GP’s, who are under time pressure, to provide more effective health and advice to their patients, as one GP said:
“We GP’s are time poor, if you realize then when you’re time poor you look quickly to say oh this is a patient tool - how can I best use this?” (healthcare professional_05).
Furthermore, health professional skills may be best used with the synthesis of self-reported symptoms, behaviors, or observations. A particular strength of a digitized version would be its ability to facilitate more streamlined communication between a person with SCI and their primary healthcare providers developing healthcare plans, as an acute nurse specialist reflected, “ I think that a digitalized version is essential with links to primary healthcare plans” (healthcare professional_03).
Efficient communication with thorough assessment is essential to ensure serious health issues are not missed, as findings reinforce that the SCI-HMT is an educational tool, not a replacement for healthcare services, as a clinical nurse specialist commented, “ remember, things will go wrong– people end up very sick and in acute care “ (healthcare professional_02).
The SCI-HMT has the potential to provide a pathway to a ‘hope for better than now’ , a hope to ‘remain well’ and a hope to ‘be happy’ , as the informant with SCI (04) declared, “self-management is a long game, if you’re keeping well, you’ve got that possibility of a good life… of happiness”. Participants with SCI felt the tool needed to be genuine and
“acknowledge the huge amount of adjustment required, recognizing that dealing with SCI issues is required to survive and live a good life” (person with SCI_04).
However, there is a risk that an individual is completely overwhelmed by the scale of the SCI-HMT content and the requirement for lifelong vigilance. Careful attention and planning were paid to layering the information accordingly to support self-management as a ‘long game’, which one person with SCI reflected in following:
“the first 2–3 year [period] is probably the toughest to get your head around the learning stuff, because you’ve got to a stage where you’re levelling out, and you’ve kind of made these promises to yourself and then you realize that there’s no quick fix” (person with SCI_01).
It was decided that this could be achieved by providing concrete examples and anecdotes from people with SCI illustrating that a meaningful, healthy life is possible, and that good health is the bedrock of a good life with SCI.
There was universal agreement that the SCI-HMT is aspirational and that it has the potential to improve knowledge and understanding for people with SCI, their families, community workers/carers and primary healthcare professionals, as a GP remarked:
“[different groups] could just read it and realize, ‘Ahh, OK that’s what that means… when you’re doing catheters. That’s what you mean when you’re talking about bladder and bowel function or skin care” (healthcare professional_04).
Despite the SCI-HMT providing an abundance of information and resources to support self-management, participants identified four gaps: (i) the priority issue of sexuality, including pleasure and identity, as one person with SCI remarked:
“ sexuality is one of the biggest issues that people with SCI often might not speak about that often cause you know it’s awkward for them. So yeah, I think that’s a that’s a serious issue” (person with SCI_03).
(ii) consideration of the taboo nature of bladder and bowel topics for indigenous people, (iii) urgent need to ensure links for SCI-HMT care plans are compatible with patient management systems, and (iv) exercise and leisure as a standalone topic taking account of effects of physical activity, including impact on mental health and wellbeing but more especially for fun.
To ensure longevity of the SCI-HMT, maintaining a partnership between people with SCI, SCI community groups and both primary and tertiary health services is required for liaison with the relevant professional bodies, care agencies, funders, policy makers and tertiary care settings to ensure ongoing education and promotion of SCI-HMT is maintained. For example, delivery of ongoing training of healthcare professionals to both increase the knowledge base of primary healthcare providers in relation to SCI, and to promote use of the tools and resources through health communities. As a community nurse specialist suggested:
“ improving knowledge in the health community… would require digital links to clinical/health management platforms” (healthcare professional_02).
In a similar vein, a GP suggested:
“ our common GP body would have continuing education requirements… especially if it’s online, in particular for the rural, rural doctors who you know, might find it hard to get into the city” (healthcare professional_04).
The successful implementation of evidence-based innovations into practice is dependent on a wide array of dynamic and active contextual factors, including the perspectives of the recipients who are destined to use such innovations. Indeed, the recently updated CFIR has called for innovation recipient perspectives to be a priority when considering contextual factors [ 10 , 11 ]. Understanding and including the perspectives of those the innovation is being designed to benefit can promote increased equity and validation of recipient populations, and potentially increase the adoption and sustainability of innovations.
In this paper, we have presented research using the recently updated CFIR to guide the collection of innovation recipients’ perspectives (including people with SCI and GPs working in the community) regarding the potential implementation barriers and facilitators of the digital version of the SCI-HMT. Collected data were synthesized to inform actionable findings– tangible ways in which the SCI-HMT could be modified according of the domains of the CFIR (e.g., see Keith et al. [ 20 ]). It is important to note that we conducted this research using the original domains of the CFIR [ 9 ] prior to Damschroder et al. publishing the updated CFIR [ 11 ]. However, in our analysis we were able to align our findings to the revised CFIR domains and constructs, as Damschroder [ 11 ] suggests, constructs can “be mapped back to the original CFIR to ensure longitudinal consistency” (p. 13).
One of the most poignant findings from our analyses was the need to ensure the content of the SCI-HMT balanced scientific evidence and clinical expertise with lived experience knowledge. This balance of clinical and experiential knowledge demonstrated genuine regard for lived experience knowledge, and created a more accessible, engaging, useable platform. For example, in the innovation and individual domains, the need to include lived experience quotes was immediately apparent once the perspective of people with SCI was included. It was highlighted that while the SCI-HMT will prove useful to many parties at various stages along the continuum of care following onset of SCI, there will be those individuals that are overwhelmed by the scale of the content. That said, the layering of information facilitated by the digitalized version is intended to provide an ease of navigation through the SCI-HMT and enable a far greater sense of control over personal health and wellbeing. Further, despite concerns regarding e-literacy the digitalized version of the SCI-HMT is seen as imperative for accessibility given the wide geographic diversity and recent COVID pandemic [ 21 ]. While there will be people who are challenged by the technology, the universally acceptable use of the internet is seen as less of a barrier than printed material.
The concept of partnership was also apparent within the data analysis focusing on the outer and inner setting domains. In the outer setting domain, our findings emphasized the importance of engaging with SCI community groups, as well as primary and tertiary care providers to maximize uptake at all points in time from the phase of subacute rehabilitation onwards. While the SCI-HMT is intended for use across the continuum of care from post-acute rehabilitation onwards, it may be that certain modules are more relevant at different times, and could serve as key resources during the hand over between acute care, inpatient rehabilitation and community reintegration.
Likewise, findings regarding the inner setting highlighted the necessity of a productive partnership between GPs and individuals with SCI to address the substantial demands of long-term self-management of health and well-being following SCI. Indeed, support is crucial, especially when self-management is the focus. This is particularly so in individuals living with complex disability following survival after illness or injury [ 22 ], where health literacy has been found to be a primary determinant of successful health and wellbeing outcomes [ 23 ]. For people with SCI, this tool potentially holds the most appeal when an individual is ready and has strong partnerships and supportive communication. This can enable potential red flags to be recognized earlier allowing timely intervention to avert health crises, promoting individual well-being, and reducing unnecessary demands on health services.
While the SCI-HMT is an educational tool and not meant to replace health services, findings suggest the current structure would lead nicely to having the conversation with a range of likely support people, including SCI peers, friends and family, GP, community nurses, carers or via on-line support services. The findings within the process domain underscored the importance of ongoing partnership between innovation implementers and a broad array of innovation recipients (e.g., individuals with SCI, healthcare professionals, family, funding agencies and policy-makers). This emphasis on partnership also addresses recent discussions regarding equity and the CFIR. For example, Damschroder et al. [ 11 ] suggests that innovation recipients are too often not included in the CFIR process, as the CFIR is primarily seen as a tool intended “to collect data from individuals who have power and/or influence over implementation outcomes” (p. 5).
Finally, we feel that our inclusion of innovation recipients’ perspectives presented in this article begins to address the notion of equity in implementation, whereby the inclusion of recipient perspectives in research using the CFIR both validates, and increases, the likelihood of sustainable adoption of evidence-based innovations, such as the SCI-HMT. We have used the CFIR in a pragmatic way with an emphasis on meaningful engagement between the innovation recipients and the research team, heeding the call from Damschroder et al. [ 11 ], who recently argued for researchers to use the CFIR to collect data from innovation recipients. Adopting this approach enabled us to give voice to innovation recipient perspectives and subsequently ensure that the tone, scope, content and presentation of the SCI-HMT balanced the needs of innovation recipients alongside the provision of evidence-based clinical information.
Our research is not without limitations. While our study was successful in identifying a number of potential barriers and facilitators to the implementation of the SCI-HMT, we did not test any implementation strategies to impact determinants, mechanisms, or outcomes. This will be the focus of future research on this project, which will investigate the impact of implementation strategies on outcomes. Focus will be given to the context-mechanism configurations which give rise to particular outcomes for different groups in certain circumstances [ 7 , 24 ]. A second potential concern is the relatively small sample size of participants that may not allow for saturation and generalizability of the findings. However, both the significant impact of secondary health complications for people with SCI and the desire for a health maintenance tool have been established in Australia [ 2 , 4 ]. The aim our study reported in this article was to achieve context-specific knowledge of a small sample that shares a particular mutual experience and represents a perspective, rather than a population [ 25 , 26 ]. We feel our findings can stimulate discussion and debate regarding participant-informed approaches to implementation of the SCI-HMT, which can then be subject to larger-sample studies to determine their generalisability, that is, their external validity. Notably, future research could examine the interaction between certain demographic differences (e.g., gender) of people with SCI and potential barriers and facilitators to the implementation of the SCI-HMT. Future research could also include the perspectives of other allied health professionals working in the community, such as occupational therapists. Lastly, while our research gave significant priority to recipient viewpoints, research in this space would benefit for ensuring innovation recipients are engaged as genuine partners throughout the entire research process from conceptualization to implementation.
Employing the CFIR provided an effective, systematic method for identifying recipient perspectives regarding the implementation of a digital health maintenance tool for people living with SCI. Findings emphasized the need to balance clinical and lived experience perspectives when designing an implementation strategy and facilitating strong partnerships with necessary stakeholders to maximise the uptake of SCI-HMT into practice. Ongoing testing will monitor the uptake and implementation of this innovation, specifically focusing on how the SCI-HMT works for different users, in different contexts, at different stages and times of the rehabilitation journey.
Data availability
The datasets supporting the conclusions of this article are available available upon request and with permission gained from the project Steering Committee.
Abbreviations
spinal cord injury
HMT-Spinal Cord Injury Health Maintenance Tool
Consolidated Framework for Implementation Research
Kirshblum S, Vernon WL. Spinal Cord Medicine, Third Edition. New York: Springer Publishing Company; 2018.
Middleton JW, Arora M, Kifley A, Clark J, Borg SJ, Tran Y, et al. Australian arm of the International spinal cord Injury (Aus-InSCI) Community Survey: 2. Understanding the lived experience in people with spinal cord injury. Spinal Cord. 2022;60(12):1069–79.
Article PubMed PubMed Central Google Scholar
Craig A, Nicholson Perry K, Guest R, Tran Y, Middleton J. Adjustment following chronic spinal cord injury: determining factors that contribute to social participation. Br J Health Psychol. 2015;20(4):807–23.
Article PubMed Google Scholar
Middleton JW, Arora M, Jerram KAS, Bourke J, McCormick M, O’Leary D, et al. Co-design of the Spinal Cord Injury Health Maintenance Tool to support Self-Management: a mixed-methods Approach. Top Spinal Cord Injury Rehabilitation. 2024;30(1):59–73.
Article Google Scholar
Middleton JW, Arora M, McCormick M, O’Leary D. Health maintenance Tool: how to stay healthy and well with a spinal cord injury. A tool for consumers by consumers. 1st ed. Sydney, NSW Australia: Royal Rehab and The University of Sydney; 2020.
Google Scholar
Nilsen P, Bernhardsson S. Context matters in implementation science: a scoping review of determinant frameworks that describe contextual determinants for implementation outcomes. BMC Health Serv Res. 2019;19(1):189.
Jagosh J. Realist synthesis for Public Health: building an Ontologically Deep understanding of how Programs Work, for whom, and in which contexts. Annu Rev Public Health. 2019;40(1):361–72.
Nilsen P. Making sense of implementation theories, models and frameworks. Implement Sci. 2015;10(1):53.
Damschroder LJ, Aron DC, Keith RE, Kirsh SR, Alexander JA, Lowery JC. Fostering implementation of health services research findings into practice: a consolidated framework for advancing implementation science. Implement Sci. 2009;4(1):50.
Damschroder LJ, Reardon CM, Opra Widerquist MA, Lowery JC. Conceptualizing outcomes for use with the Consolidated Framework for Implementation Research (CFIR): the CFIR outcomes Addendum. Implement Sci. 2022;17(1):7.
Damschroder LJ, Reardon CM, Widerquist MAO, Lowery JC. The updated Consolidated Framework for Implementation Research based on user feedback. Implement Sci. 2022;17(1):75.
Plamondon K, Ndumbe-Eyoh S, Shahram S. 2.2 Equity, Power, and Transformative Research Coproduction. Research Co-Production in Healthcare2022. p. 34–53.
Verville L, Cancelliere C, Connell G, Lee J, Munce S, Mior S, et al. Exploring clinicians’ experiences and perceptions of end-user roles in knowledge development: a qualitative study. BMC Health Serv Res. 2021;21(1):926.
Gainforth HL, Hoekstra F, McKay R, McBride CB, Sweet SN, Martin Ginis KA, et al. Integrated Knowledge Translation Guiding principles for conducting and Disseminating Spinal Cord Injury Research in Partnership. Arch Phys Med Rehabil. 2021;102(4):656–63.
Langley J, Knowles SE, Ward V. Conducting a Research Coproduction Project. Research Co-Production in Healthcare2022. p. 112– 28.
Braun V, Clarke V. One size fits all? What counts as quality practice in (reflexive) thematic analysis? Qualitative Research in Psychology. 2020:1–25.
Tong A, Sainsbury p, Craig J. Consolidated criteria for reporting qulaitative research (COREQ): a 32-item checklist for interviews and focus groups. Int J Qual Health Care. 2007;19(6):349–57.
Bengtsson M. How to plan and perform a qualitative study using content analysis. NursingPlus Open. 2016;2:8–14.
Braun V, Clarke V. Using thematic analysis in psychology. Qualitative Res Psychol. 2006;3(2):77–101.
Keith RE, Crosson JC, O’Malley AS, Cromp D, Taylor EF. Using the Consolidated Framework for Implementation Research (CFIR) to produce actionable findings: a rapid-cycle evaluation approach to improving implementation. Implement Science: IS. 2017;12(1):15.
Choukou M-A, Sanchez-Ramirez DC, Pol M, Uddin M, Monnin C, Syed-Abdul S. COVID-19 infodemic and digital health literacy in vulnerable populations: a scoping review. Digit HEALTH. 2022;8:20552076221076927.
PubMed PubMed Central Google Scholar
Daniels N. Just Health: Meeting Health needs fairly. Cambridge University Press; 2007. p. 397.
Parker SM, Stocks N, Nutbeam D, Thomas L, Denney-Wilson E, Zwar N, et al. Preventing chronic disease in patients with low health literacy using eHealth and teamwork in primary healthcare: protocol for a cluster randomised controlled trial. BMJ Open. 2018;8(6):e023239–e.
Salter KL, Kothari A. Using realist evaluation to open the black box of knowledge translation: a state-of-the-art review. Implement Sci. 2014;9(1):115.
Sebele-Mpofu FY. The Sampling Conundrum in qualitative research: can Saturation help alleviate the controversy and alleged subjectivity in Sampling? Int’l J Soc Sci Stud. 2021;9:11.
Malterud K, Siersma VD, Guassora AD. Sample size in qualitative interview studies: guided by Information Power. Qual Health Res. 2015;26(13):1753–60.
Download references
Acknowledgements
Authors of this study would like to thank all the consumers with SCI and healthcare professionals for their invaluable contribution to this project. Their participation and insights have been instrumental in shaping the development of the SCI-HMT. The team also acknowledges the support and guidance provided by the members of the Project Steering Committee, as well as the partner organisations, including NSW Agency for Clinical Innovation, and icare NSW. Author would also like to acknowledge the informant group with lived experience, whose perspectives have enriched our understanding and informed the development of SCI-HMT.
The SCI Wellness project was a collaborative project between John Walsh Centre for Rehabilitation Research at The University of Sydney and Royal Rehab. Both organizations provided in-kind support to the project. Additionally, the University of Sydney and Royal Rehab received research funding from Insurance and Care NSW (icare NSW) to undertake the SCI Wellness Project. icare NSW do not take direct responsibility for any of the following: study design, data collection, drafting of the manuscript, or decision to publish.
Author information
Authors and affiliations.
John Walsh Centre for Rehabilitation Research, Northern Sydney Local Health District, St Leonards, NSW, Australia
John A Bourke, K. Anne Sinnott Jerram, Mohit Arora, Ashley Craig & James W Middleton
The Kolling Institute, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia
Burwood Academy Trust, Burwood Hospital, Christchurch, New Zealand
John A Bourke
Royal Rehab, Ryde, NSW, Australia
James W Middleton
State Spinal Cord Injury Service, NSW Agency for Clinical Innovation, St Leonards, NSW, Australia
You can also search for this author in PubMed Google Scholar
Contributions
Project conceptualization: KASJ, MA, JWM; project methodology: JWM, MA, KASJ, JAB; data collection: KASJ and MA; data analysis: KASJ, JAB, MA, JWM; writing—original draft preparation: JAB; writing—review and editing: JAB, KASJ, JWM, MA, AC; funding acquisition: JWM, MA. All authors contributed to the revision of the paper and approved the final submitted version.
Corresponding author
Correspondence to John A Bourke .
Ethics declarations
Ethics approval and consent to participate.
The first (RESP/18/212) and second phase (2019/ETH13961) of the project received ethical approval from The Northern Sydney Local Health District Human Research Ethics Committee. All participants provided informed, written consent. All data were to be retained for 7 years (23rd May 2030).
Consent for publication
Not applicable.
Competing interests
MA part salary (from Dec 2018 to Dec 2023), KASJ part salary (July 2021 to Dec 2023) and JAB part salary (Jan 2022 to Aug 2022) was paid from the grant monies. Other authors declare no conflicts of interest.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Bourke, J.A., Jerram, K.A.S., Arora, M. et al. Using the consolidated Framework for Implementation Research to integrate innovation recipients’ perspectives into the implementation of a digital version of the spinal cord injury health maintenance tool: a qualitative analysis. BMC Health Serv Res 24 , 390 (2024). https://doi.org/10.1186/s12913-024-10847-x
Download citation
Received : 14 August 2023
Accepted : 11 March 2024
Published : 28 March 2024
DOI : https://doi.org/10.1186/s12913-024-10847-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Spinal Cord injury
- Self-management
- Innovation recipients
- Secondary health conditions
- Primary health care
- Evidence-based innovations
- Actionable findings
- Consolidated Framework for implementation research
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
- Study Protocol
- Open access
- Published: 26 March 2024
The effect of a midwifery continuity of care program on clinical competence of midwifery students and delivery outcomes: a mixed-methods protocol
- Fatemeh Razavinia ORCID: orcid.org/0000-0002-6827-509X 1 , 2 ,
- Parvin Abedi ORCID: orcid.org/0000-0002-6980-0693 3 ,
- Mina Iravani ORCID: orcid.org/0000-0002-8854-1738 4 ,
- Eesa Mohammadi ORCID: orcid.org/0000-0001-6169-9829 5 ,
- Bahman Cheraghian ORCID: orcid.org/0000-0001-5446-6998 6 ,
- Shayesteh Jahanfar ORCID: orcid.org/0000-0001-6149-1067 7 &
- Mahin Najafian ORCID: orcid.org/0000-0002-6649-3931 8
BMC Medical Education volume 24 , Article number: 338 ( 2024 ) Cite this article
134 Accesses
Metrics details
The midwifery continuity of care model is one of the care models that have not been evaluated well in some countries including Iran. We aimed to assess the effect of a program based on this model on the clinical competence of midwifery students and delivery outcomes in Ahvaz, Iran.
This sequential embedded mixed-methods study will include a quantitative and a qualitative phase. In the first stage, based on the Iranian midwifery curriculum and review of seminal midwifery texts, a questionnaire will be developed to assess midwifery students’ clinical competence. Then, in the second stage, the quantitative phase (randomized clinical trial) will be conducted to see the effect of continuity of care provided by students on maternal and neonatal outcomes. In the third stage, a qualitative study (conventional content analysis) will be carried out to investigate the students’ and mothers’ perception of continuity of care. Finally, the results of the quantitative and qualitative phases will be integrated.
According to the nature of the study, the findings of this research can be effectively used in providing conventional midwifery services in public centers and in midwifery education.
Trial registration
This study was approved by the Ethics Committee of Ahvaz Jundishapur University of Medical Sciences (IR.AJUMS.REC.1401.460). Also, the study protocol was registered in the Iranian Registry for Randomized Controlled Trials (IRCT20221227056938N1).
Peer Review reports
Providing quality services to pregnant women has been recommended to all countries to achieve the Millennium Development Goals (MDGs) (Goals 3, 4 and 5) [ 1 ]. There are different care methods to maintain maternal and neonatal health during pregnancy and postpartum [ 1 ]. One of these care models is continuity of care that can be provided by a midwife or an obstetrician.
Midwifery continuity of care is a relationship-based care provided by a midwife who can be supported by one to three more midwives. They provide planned care for a woman during pregnancy, labor, birth, and the early postpartum period up to 6 weeks after delivery [ 2 ].
Continuity of midwifery care has become a global effort to enable women to have access to high-quality maternity care and delivery services [ 3 ]. As a result, many service providers today are transitioning to a continuous care model [ 4 ], and they have considered continuous care to be necessary for realizing women's rights [ 5 ]. Also, continuous midwifery care is known as the gold standard in maternity care to achieve excellent results for women [ 5 , 6 ]. In order to strengthen midwifery services to achieve global health goals in 2015, the World Health Organization (WHO) proposed a midwife-led continuous care model [ 7 ].
Countries use different midwifery care models. In Iran, for example, primary health services that are specific to pregnant mothers are provided in public health centers by midwives working in the network system and in compliance with the level of services and the referral system [ 8 ].
In general, midwifery continuous care not only has an important impact on a wide range of health and clinical outcomes for mothers and neonates but also brings about economic consequences for the health system [ 2 , 9 ]. This care model is useful for healthcare professionals as well [ 10 ], and it has improved the job satisfaction of midwives [ 11 ]. The midwife is the main guide in planning, organizing and providing care to a woman from the beginning of pregnancy to the postpartum period [ 12 ]. In 2011, in order to increase job motivation and satisfaction, promote retention of the midwifery workforce [ 13 ], and alleviate the shortage of workforce at the international level [ 14 ], the Nursing and Midwifery Advisory Center recommended using midwifery students (at the bedside and to perform midwifery work) to overcome this problem.
Providing high quality care requires enhancing the clinical competence of the professionals [ 4 ]. There is a close relationship between the concept of patient care quality and clinical competence. Therefore, clinical competence is of unique importance in midwifery practice [ 15 ]. As a result, in order to achieve quality patient care, midwifery professionals need to train students to become workforce with clinical competence in order to provide quality care in the health system. WHO defined clinical competence as a level of performance that demonstrates the effective application of knowledge, skills, and judgment [ 16 ].
A previous study showed that clinical competence of midwives plays an important role in managing the process of providing care, achieving care goals, and improving the quality of midwifery services [ 17 ]. In other words, the graduates of this field must have an acceptable level of clinical and professional skills in performing midwifery duties so that the health of mothers, children, and ultimately the community can be improved.
In Iran, prenatal care and the care during labor, delivery and postpartum are not continuous, and a new health provider may take the responsibility of care at any stage. This fragmented care may negatively affect the pregnancy outcomes and increase the rate of cesarean section [ 18 ]. Furthermore, the results of some studies in Iran indicate that the clinical competence obtained by midwifery students is far from optimal and that they do not acquire the necessary skills and abilities at the end of their studies [ 19 ]. Farrokhi et al. showed that the performance quality of 70% of midwives is average, and only 18.5% of them have good quality performance [ 20 ]. Several factors play a role in acquiring, maintaining and improving clinical competence [ 21 ]. There are a number of solutions that can increase the clinical competence of midwifery students, and one is the use of different care models such as the continuity of care model. The continuity of care model allows students to develop their midwifery knowledge, skills, and values individually [ 22 ]. Despite the strong foundation of midwifery in Iran, midwifery care models have not yet been tested. Some studies have reported that the quality of services provided during pregnancy, delivery and after delivery in Iran is poor to moderate. Also, these studies emphasize the necessity of a paradigm shift for better quality care and greater satisfaction of mothers, and they consider lack of continuity of care as the reason for the increase in unnecessary cesarean sections [ 23 , 24 , 25 ]. Moreover, the lack of qualified and experienced workforce has led to low quality health services, including midwifery care, and an increase in the economic burden of health. In Iran, no study has yet been conducted to investigate the effect of the midwifery continuity of care model on the students’ clinical competence and pregnancy outcomes. Given the importance of this topic, using a mixed-methods study design, we aimed to assess the effect of a midwifery continuity of care program on the clinical competence of midwifery students and pregnancy outcomes in Ahvaz, Iran.
Specific objectives
To determine the effect of midwifery continuity of care program on the clinical competence of midwifery students.
To determine the effect of a midwifery continuity of care program provided by midwifery students on pregnancy outcomes.
To explain the perception of midwifery students and mothers about the use of the midwifery continuity of care program provided by midwifery students.
Methods/design
Study design.
This sequential embedded mixed-methods study will include a quantitative phase and a qualitative one. A mixed (embedded) experimental design involves the collection and analysis of quantitative and qualitative data by the researcher and the integration of the information into an experimental study or intervention trial. This design adds qualitative data to an experiment or intervention to integrate the personal experience of research participants. Therefore, the qualitative data are converted into a secondary source of data embedded before and after the test. Qualitative data is added to the experiment in differrent ways, including: before the experiment, during the experiment, or after the experiment [ 26 , 27 ]. Embedded mixed-methods studies that are qualitative followed by quantitative are used to understand the rationale for the results and receive feedback from participants (to confirm and support the findings of the quantitative studies) [ 27 ]. In the first stage of this study, a questionnaire for assessing midwifery students’ clinical competence will be created based on the midwifery curriculum of Iran and a review of seminal texts of midwifery. Then, the effect of continuity of care provided by midwifery students on maternal and neonatal outcomes will be assessed in a randomized clinical trial. In the third stage, a qualitative study will be carried out to investigate the perception of students and mothers. Finally, the results of the quantitative and qualitative phases will be integrated (Fig. 1 ).

Sequential and embedded mixed-methods design
First stage: questionnaire development
This questionnaire will be developed based on midwifery curriculum and a comprehensive and systematic search (with no time limit) in English and Persian databases (Web of Science, Embase, Scopus, ProQuest, Google scholar, Magiran, SID).
Tool design
There are four steps in tool development:
Choosing a conceptual model to show aspects of clinical competence in the measurement process
Explaining the purpose of the tool
Designing the route map
Developing the tool (use of methods, classification of objects, rules and procedures for scoring tools) [ 28 ].
Answer to the objects
A 1 to 4-point Likert scale will be used for scoring [ 29 ].
Content validity
To ensure the selection of the most important and correct content (necessity of the case), the content validity will be assessed. Also, to ensure that the instrument items are designed in the best way to measure the content, the content validity index will be calculated [ 30 ].
Reliability
Reliability will be evaluated using internal consistency (Cronbach's alpha coefficient ≥ 0.7) and stability (test-re-test ≥ 0.74) by piloting the questionnaire on 20 midwifery students [ 31 ].
Second stage: quantitative phase
A randomized controlled clinical trial will be conducted in this phase of research to examine the effect of the continuous care program of midwifery students on their clinical competence and pregnancy outcomes.
Sample size
According to the study objective and previous study results [ 32 ] with α = 0.01, β = 0.1, p 1 = 0.51 and p 2 = 0.021, the sample size will be n = 23. Considering a 20% dropout rate, the final sample size will be 58 women (29 women in each group).
Data collection
This phase of the randomized clinical trial will be conducted with the participation of 58 undergraduate midwifery students at their 7th and 8th semesters. The students will be divided randomly to intervention (continuous care) and control (routine care) groups providing care to 58 pregnant women in six health centers and two hospitals (Sina and Razi) in Ahvaz city, southwest of Iran.
The study will begin after receiving the approval of the Ethics Committee of Ahvaz University of Medical Sciences and registering the study in the Iranian Registry for Randomized Clinical Trials. Inclusion criteria will be willingness to participate in the study.
Randomization
To implement the intervention, the students will be divided into two intervention (providing continuous care for pregnant women) and control (providing standard care for pregnant women) groups. Allocating students will be done using permuted block randomization technique with a block size of four and an allocation ratio of 1:1. Five blocks of 4 pieces and 3 blocks of 3 pieces will be extracted randomly using WIN PEPI software. In each block of 4, 2 students will be in control and 2 will be in intervention group. Also, in each block of 3 students, 1 student will be in control and 2 will be in intervention group, and the arrangement of each person is random. To prevent contamination, first the control group will provide routine care, and then the intervention group will conduct continuity of care for pregnant women. Mothers are randomly selected based on the hospital where they will give birth. As a result, Razi Hospital will be the control group and Sina Hospital will be the intervention group.
Intervention
Women who meet the inclusion criteria will be recruited in the study using a non-probability convenience sampling method. Women in the intervention group will be included in the study after their first pregnancy visit (6–10 weeks of gestation) and will receive continuous care by midwifery students. Women in the control group will receive the usual and routine care, and will be included in the study at the time of delivery. They will have a gestational age of more than 37 weeks based on the inclusion criteria of the study. Their delivery will be performed by midwifery students who will follow them up until six weeks after delivery.
At first, the necessary training will be given by the lead researcher (FR) to the students in orientation sessions held for both groups separately. In the intervention group, each midwifery student as the main midwife will be responsible for taking care of two or three pregnant women and will be the back-up midwife for two other pregnant women (under the supervision of other students). The lead researcher will create a group in WhatsApp with the participation of students in the intervention group, and they can communicate with each other and the researcher. Also, the midwifery students will be directly and indirectly under the supervision of a qualified person (lead researcher). Another WhatsApp group will be created for the women of the intervention and control groups (to facilitate communication between the researcher and the women). Two midwifery students will be introduced to each pregnant woman in the intervention group (as a main midwife and a backup midwife). If the main midwife is not available, the woman will be in contact with the backup midwife. The backup student will meet the woman at least once and will be introduced to her.
Instruments
All students and pregnant women participating in this study will complete a demographic questionnaire. A checklist will be provided for collecting data during prenatal care, labor, and delivery.
Also, the midwifery students will complete the clinical competency questionnaire at the beginning and end of the study.
Care will be provided and recorded by the main student according to the pregnancy care protocol. Also, danger signs will be taught to the students according to the national protocol, and emergencies will be handled by the midwifery student under the supervision of the lead researcher. Admission to hospital will be arranged by the student, and all information will be recorded. Pregnancy, labour and delivery, postpartum, and newborn checklist will be completed. Students will complete a demographic and obstetric questionnaire that includes questions about age, education, occupation, gravidity, parity, abortions, live and dead children, last contraceptive method, intended and unintended pregnancies, last menstrual period (LMP), gestational age, date of birth, body mass index (BMI), previous pregnancy and childbirth records, high-risk behavior of the mother and father, current history of special care, test and ultrasound results, and participation in childbirth preparation class. Also, the following data will be recorded in the labor and delivery and post-partum checklist: checking the conditions of labor according to the partograph, length of labor, need for induction and the method used type of delivery, examination of perineal trauma, postpartum bleeding, and examination of the condition of the mother up to 6 weeks after delivery. In addition, the amount of bleeding will be checked visually and by measuring the level of hemoglobin and hematocrit. Apgar score of the newborn will be recorded (in infant checklist) in minutes 1 and 5. Also, the newborn’s hospitalization status, breastfeeding and anthropometric indices will be recorded.
The students in the intervention group will start prenatal care < 20 weeks of gestation. At least five round of prenatal care will be provided by each student according to national guidelines for each pregnant woman. Pregnant women can communicate with their in-charge students in non-emergency cases from 8:00 a.m. to 23:00 p.m. and in emergency cases 24 h a day, all days a week. All reports will be recorded by the students. During labor and delivery, the student and the lead researcher will be present at the mother's bedside. In case of natural vaginal delivery (NVD), delivery will be done by a student midwife under the supervision of the researcher. In case of cesarean delivery (CS), a student will be present at the patient's bedside. Postpartum care will be provided by midwifery students in both groups (intervention and control). Each student will be at the mother's bedside for two hours after delivery. The conditions of labor, delivery, and the neonate will be recorded by the student in the relevant form. Also, the mother will be followed up by telephone for up to 6 weeks after delivery (postpartum). The clinical competency questionnaire will be completed by students before and after the intervention.
Inclusion criteria
Inclusion criteria for midwifery students will be: studying at the seventh and eighth semester and willingness to participate in the study.
Inclusion criteria for service recipients (pregnant women) will be: age 18 – 40 years, Iranian nationality, singleton pregnancy, low risk pregnancy, and gestational age < 20 wks.
Exclusion criteria
Exclusion criteria will be: history of psychiatric disorders, previous caesarean section, use of alcohol and tobacco, or having a disease that requires prenatal care by a specialist.
Primary outcome
Clinical competence of midwifery students.
Secondary outcome
Mode of delivery, length of labor stages, the need to induction, postpartum bleeding first and fifth minute Apgar score, admission of neonate to the neonatal intensive care unit, breastfeeding initiation, and exclusive breastfeeding up to 6 weeks postpartum.
Data analysis
Statistical analyses will be done using SPSS version 26.0 (SPSS, Inc., Chicago, IL, USA). The independent t-test and Chi-square tests will be used for continuous data and categorical data, respectively. ANCOVA test will be used to eliminate the influence of confounding variables. The effect size will be calculated. A 95% confidence interval (CI) and p values will be reported. P -values less than 0.5 will be considered statistically significant.
Third step of research: qualitative study
This phase will be a qualitative study using conventional content analysis.
Purposeful sampling will be used in this study [ 33 ]. Sampling will continue until data saturation [ 34 ], i.e., no new information or data about a class or relationships between classes is revealed.
This phase of the study is a conventional qualitative content analysis [ 35 ] aimed at examining the perceptions of midwifery students and mothers receiving continuous care. The researcher will conduct in-depth, semi-structured interviews with open-ended questions with students and mothers in the group of the continuous care program. All interviews will be done by the lead researcher who is qualified in qualitative research method. The interview will start with a general and open question such as: “Please tell me about your experiences or feelings about participating in the continuous midwifery care program. How did you feel about participating in this program?” Then, in-depth exploratory questions will be asked based on their answers (e.g., what do you mean? Why? Can you elaborate on that? Can you give me an example so I can understand what you mean?). All interviews will be recorded with the participants' consent. Paralinguistic features, such as mood and features of the participants, including tone of voice, facial expressions, and their posture, will be recorded by the researcher during the interview [ 35 ].
The data will be analyzed based on Granheim and Lundman's 2004 content analysis approach [ 36 ].
Interviews will be transcribed at the end of each interview. Data analysis begins with a careful study of all data so that the researcher can immerse herself in the data and gain an overview. Interviews will be transcribed verbatim. Key concepts will be highlighted and codes will be extracted. Then the first interpretations will be made and analyzed. Labels emerge for codes that represent more than one key concept and are usually taken directly from the text and become the initial coding map. Then the codes are placed in the category based on their similarity. Then, definitions will be created for each category, subcategory and code. When reporting findings, examples of each code and data category will be provided [ 35 ].
Inclusion criteria for midwifery students will be: studying at the seventh or eighth semester, willingness to participate in the study.
Inclusion criteria for service recipients (pregnant women) will be: receiving continuous care provided by the student, willingness to participate in the study, and being able to communicate.
The qualitative study and interview data will be analyzed based on the content analysis approach of Granheim and Lundman 2004 [ 36 ] as follows:
Reading and re-reading the interviews after completion of each interview
Selection of the unit of analysis
Determination of semantic units
Classification
Extraction of information content
In the first step, the data is converted into text format. As soon as possible after the interview, the interview will be typed verbatim. Then the whole text will be read several times to get a general understanding of the content of interview. Each meaning unit will be converted into condensed meaning units and then coded. The Codes will be classified into subcategories and categories based on their common characteristics. Finally, the content of the categories will be revealed, taking into account their hidden meaning [ 36 ].
Trustworthiness
Five criteria of will be used to increase data trustworthiness according to Lincoln & Guba [ 37 ]. These include: 1. Credibility, 2. Dependability, 3. Confirmability, 4. Transferability, 5. Authenticity.
Credibility of the data will be ensured by continuous engagement of the researchers with the subject, member checks, and external checks. Dependability will be ensured by relying on the insight of external observers. In order to increase the confirmability, data will be accurately recorded and reported. Also, transferability will be ensured by presenting the research process accurately, clearly and purposefully, which includes purposive sampling and presenting the research results to a number of people with the same profile of the participants who did not participate in the research. Finally, authenticity will be guaranteed by continuous reflection on information, long-term presence of the researcher, interview recording, writing, and reporting of findings.
Combining qualitative and quantitative phases
Data combination will be done using data integration strategies. The integration or combination of data starts from quantitative data analysis. Then qualitative data is collected by interview. In fact, the qualitative study is a secondary source of embedded data in the collection of experimental test data (continuous care) after the quantitative study. In this research, in order to understand the results of the RCT, the views of the participants will be unified in order to get a correct understanding of the intervention (implementation of the continuity of care model by the students) from the mothers' and students' point of view (Fig. 2 ).

Study diagram
Study status
The development of the evaluation tools was made. Also, sampling the quantitative phase of the study and the basic of the program are in process (Table 1 ).
This is the first mixed-methods study to be conducted in Iran investigating the effect of a midwifery continuity of care program on clinical competence of midwifery students and pregnancy outcomes. According to the recommendations of the WHO, midwifery continuity of care should be adopted in order to increase the quality of pregnancy care as well as the satisfaction of pregnant women and service providers [ 7 ]. Contrary to the recommendation of WHO, the continuous care program is neither implemented in Iran's health system nor included in the midwifery curriculum. The results of this study can help health planners and policy makers to implement high quality midwifery care program based on global recommendations.
The study has several strengths. The use of a mixed-methods study design (combination of quantitative and qualitative approaches) in contrast to the separate use of quantitative and qualitative studies provides a better understanding of the research questions [ 38 ]. In embedded design, one type of data collection (quantitative or qualitative) plays a supporting and essential role for another type. As a result, the embedded mixed-methods technique in the qualitative phase after designing the intervention will be used to receive feedback from the participants to confirm and support the findings of quantitative phase [ 39 ]. Also, interviews with mothers and midwifery students in the intervention group can reflect their positive and negative experiences of this program. Considering that Iran's healthcare system lacks continuous midwifery care, the findings of this research can be effectively used in providing conventional midwifery services in public centers and in midwifery education.
Considering that this care model will be implemented for the first time in Iran's midwifery education and healthcare system, there may be two possible limitations in this study: lack of infrastructure and interference with other educational programs.
Availability of data and materials
All the data that will be obtained will be published in the next article after the implementation of the study.
Abbreviations
Body mass index
Cesarean section
Last menstrual period
Millennium Development Goals
Natural vaginal delivery
World Health Organization
Bagheri A, Simbar M, Samimi M, Nahidi F, Majd HA. Exploring the concept of continuous midwifery-led care and its dimensions in the prenatal, perinatal, and postnatal periods in Iran (Kashan). Midwifery. 2017;51:44–52.
Article Google Scholar
Cummins A, Coddington R, Fox D, Symon A. Exploring the qualities of midwifery-led continuity of care in Australia (MiLCCA) using the quality maternal and newborn care framework. Women Birth. 2020;33(2):125–34.
Choudhary S, Jelly P, Mahala P. Models of maternity care: a continuity of midwifery care. Int J Reprod Contracept Obstet Gynecol. 2020;9(6):2666–70.
Bradford BF, Wilson AN, Portela A, McConville F, Fernandez Turienzo C, Homer CS. Midwifery continuity of care: a scoping review of where, how, by whom and for whom? PLOS Global Public Health. 2022;2(10):e0000935.
Lettink A, Chaibekava K, Smits L, Langenveld J, van de Laar R, Peeters B, et al. CCT: continuous care trial-a randomized controlled trial of the provision of continuous care during labor by maternity care assistants in the Netherlands. BMC Pregnancy Childbirth. 2020;20(1):1–6.
Chaibekava KV, Scheenen AJ, Lettink A, Smits LJ, Langenveld J, Van De Laar R, et al. Continuous care during labor by maternity care assistants in the Netherlands vs care-as-usual: a randomized controlled trial. Am J Obstet Gynecol MFM. 2023;5(11):101168.
Michel-Schuldt M, McFadden A, Renfrew M, Homer C. The provision of midwife-led care in low-and middle-income countries: an integrative review. Midwifery. 2020;84:102659.
Khosravi S, Babaey F, Abedi P, Kalahroodi ZM, Hajimirzaie SS. Strategies to improve the quality of midwifery care and developing midwife-centered care in Iran: analyzing the attitudes of midwifery experts. BMC Pregnancy Childbirth. 2022;22(1):40.
Donnellan Fernandez R, Scarf V, Devane D, Healey A. Is Midwifery Continuity of Care Cost Effective? Midwifery Continuity of Care. Elsevier; 2019. p. 137–56.
Aune I, Tysland T, Amalie VS. Norwegian midwives’ experiences of relational continuity of midwifery care in the primary healthcare service: a qualitative descriptive study. Nordic J Nurs Res. 2021;41(1):5–13.
Hanley A, Davis D, Kurz E. Job satisfaction and sustainability of midwives working in caseload models of care: an integrative literature review. Women Birth. 2022;35(4):e397–407.
Grylka-Baeschlin S, Iglesias C, Erdin R, Pehlke-Milde J. Evaluation of a midwifery network to guarantee outpatient postpartum care: a mixed methods study. BMC Health Serv Res. 2020;20:1–12.
Evans J, Taylor J, Browne J, Ferguson S, Atchan M, Maher P, et al. The future in their hands: graduating student midwives’ plans, job satisfaction and the desire to work in midwifery continuity of care. Women Birth. 2020;33(1):e59–66.
Carter J, Sidebotham M, Dietsch E. Prepared and motivated to work in midwifery continuity of care? A descriptive analysis of midwifery students’ perspectives. Women Birth. 2022;35(2):160–71.
Inoue N, Nakao Y, Yoshidome A. Development and validity of an intrapartum self-assessment scale aimed at instilling midwife-led care competencies used at freestanding midwifery units. Int J Environ Res Public Health. 2023;20(3):1859.
Vázquez-Sánchez C, Gigirey L, editors. Design of a scoring rubric for the assessment of clinical competencies in the subject of optometry IV of the degree of optics and optometry-USC. INTED2023 Proceedings. Valencia: IATED; 2023. p. 2224–30. https://doi.org/10.21125/inted.2023.0613 .
Kubota S, Ando M, Murray J, Khambounheuang S, Theppanya K, Nanthavong P, et al. A regulatory gap analysis of midwifery to deliver essential reproductive, maternal, newborn, child and adolescent health services in Lao People’s Democratic Republic. Lancet Reg Health West Pac. 2024;43:1–10. https://doi.org/10.1016/j.lanwpc.2023.100959 .
Pazandeh F, Moridi M, Safari K. Labouring women perspectives on mistreatment during childbirth: a qualitative study. Nursing Ethics. 2023;30(4):513–25. https://doi.org/10.1177/09697330231158732 .
Abbasi A, Bazghaleh M, FadaeeAghdam N, Basirinezhad MH, Tanhan A, Montazeri R, et al. Efficacy of simulated video on test anxiety in objective structured clinical examination among nursing and midwifery students: a quasi-experimental study. Nurs Open. 2023;10(1):165–71.
Farokhi F. Quality assessment of midwives performance in prenatal cares in urban health centers in Mashhad, Iran. Payesh (Health Monitor). 2008;7(3):0.
Google Scholar
Moradali MR, Hajian S, Majd HA, Rahbar M, Entezarmahdi R. Job Satisfaction and its Related Factors in Midwives Working in the Health Services System in Iran: A Systematic Review. J Midwifery Reprod Health. 2023;11(2):3650–63. https://doi.org/10.22038/jmrh.2023.64824.1890 .
Hainsworth N, Cummins A, Newnham E, Foureur M. Learning through relationships: the transformative learning experience of midwifery continuity of care for students: a qualitative study. Women Birth. 2023;36(4):385–92.
Lazar J. Exploring the experiences of midwives facilitating group antenatal care: City, University of London; 2023.
Adelson P, Fleet J-A, McKellar L. Evaluation of a regional midwifery caseload model of care integrated across five birthing sites in South Australia: women’s experiences and birth outcomes. Women Birth. 2023;36(1):80–8.
Prussing E, Browne G, Dowse E, Hartz D, Cummins A. Implementing midwifery continuity of care models in regional Australia: a constructivist grounded theory study. Women Birth. 2023;36(1):99–107.
Pintubatu J. keterampilan proses sains pada pembelajaran ipas berorientasi outdoor learning siswa SMK Negeri 1 Lolak. Charm Sains: Jurnal Pendidikan Fisika. 2023;4(1):7–12.
Creswell JW. Controversies in mixed methods research. Sage Handbook Qual Res. 2011;4(1):269–84.
Kristensen SB, Clausen A, Skjødt MK, Søndergaard J, Abrahamsen B, Möller S, et al. An enhanced version of FREM (Fracture Risk Evaluation Model) using national administrative health data: analysis protocol for development and validation of a multivariable prediction model. Diagn Progn Res. 2023;7(1):19.
Alabi AT, Jelili MO. Clarifying likert scale misconceptions for improved application in urban studies. Qual Quant. 2023;57(2):1337–50.
Roopashree MR. A pragmatic approach for the calculation content validity indices: a study on validation of training tool for pre and post-test questionnaire for the health care sector. QAI J Healthc Qual Patient Saf. 2023;4(1):17–23.
Martyushev NV, Malozyomov BV, Sorokova SN, Efremenkov EA, Valuev DV, Qi M. Review models and methods for determining and predicting the reliability of technical systems and transport. Mathematics. 2023;11(15):3317.
Hildingsson I, Karlström A, Haines H, Johansson M. Swedish women’s interest in models of midwifery care–Time to consider the system? A prospective longitudinal survey. Sex Reprod Healthc. 2016;7:27–32.
Creswell JW, Creswell JD. Research design: Qualitative, quantitative, and mixed methods approaches. 3rd ed. SAGE Publications Inc.; 2017.
Obilor EI. Convenience and purposive sampling techniques: are they the same. Int J Innov Soc Sci Educ Res. 2023;11(1):1–7.
Serafini F, Reid SF. Multimodal content analysis: expanding analytical approaches to content analysis. Vis Commun. 2023;22(4):623–49.
Graneheim UH, Lundman B. Qualitative content analysis in nursing research: concepts, procedures and measures to achieve trustworthiness. Nurse Educ Today. 2004;24(2):105–12.
Lincoln YS, Guba EG. Naturalistic inquiry. SAGE Publications; 1985.
Matović N, Ovesni K. Interaction of quantitative and qualitative methodology in mixed methods research: integration and/or combination. Int J Social Res Methodol. 2023;26(1):51–65.
Creswell JW, Clark VLP. Designing and conducting mixed methods research. SAGE Publication, Inc; 2017.
Download references
The study was funded by Ahvaz Jundishapur University of Medical Sciences.
Author information
Authors and affiliations.
Midwifery Department, Reproductive Health Promotion Research Center, Ahvaz Jundishapur University of Medical Sciences, Ahvaz, Iran
Fatemeh Razavinia
Midwifery Department, Menopause Andropause Research Center, Ahvaz Jundishapur University of Medical Sciences, Ahvaz, Iran
Midwifery Department, Menopause Andropause Research Center, Ahvaz Jundisahpur University of Medical Sciences, Golestan BLvd, Ahvaz, Iran
Parvin Abedi
Reproductive Health Promotion Research Center, Midwifery Department, Nursing and Midwifery School, Ahvaz Jundishapur University of Medical Sciences, Ahvaz, Iran
Mina Iravani
Department of Nursing, Faculty of Medical Sciences, Tarbiat Modares University, Tehran, Iran
Eesa Mohammadi
Alimentary Tract Research Center, Clinical Sciences Research Institute, Department of Biostatistics and Epidemiology, School of Public Health, Ahvaz Jundishapur University of Medical Sciences, Ahvaz, Iran
Bahman Cheraghian
MPH Program, Department of Public Health and Community Medicine, Tufts University School of Medicine, Boston, USA
Shayesteh Jahanfar
Department of Obstetrics and Gynecology, School of Medicine, Ahvaz Jundishapur University of Medical Sciences, Ahvaz, Iran
Mahin Najafian
You can also search for this author in PubMed Google Scholar
Contributions
FR, PA, MI, EM, BCh, ShJ and MN conceptualized the study. FR will collect the data. FR drafted the protocol. PA revised the manuscript. The authors read and approved the final manuscript.
Corresponding author
Correspondence to Parvin Abedi .
Ethics declarations
Ethics approval and consent to participate.
This study was approved by the Ethics Committee of Ahvaz Jundishapur University of Medical Sciences (IR.AJUMS.REC.1401.460). Also, the study protocol was registered in the Iranian Registry for Randomized Controlled Trials (IRCT20221227056938N1). Informed consent will be obtained from all participants. The study’s findings will be shared via the publishing of peer-reviewed articles, talks at scientific conferences and meetings with related teams.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Razavinia, F., Abedi, P., Iravani, M. et al. The effect of a midwifery continuity of care program on clinical competence of midwifery students and delivery outcomes: a mixed-methods protocol. BMC Med Educ 24 , 338 (2024). https://doi.org/10.1186/s12909-024-05321-5
Download citation
Received : 28 October 2023
Accepted : 15 March 2024
Published : 26 March 2024
DOI : https://doi.org/10.1186/s12909-024-05321-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Continuity of care
- Clinical competence
- Mixed-methods
- Midwifery students
- Pregnancy outcomes
BMC Medical Education
ISSN: 1472-6920
- Submission enquiries: [email protected]
- General enquiries: [email protected]
ORIGINAL RESEARCH article
Public perception of media social responsibility in developing countries: a case study of albania provisionally accepted.

- 1 Aleksandër Moisiu University, Albania
The final, formatted version of the article will be published soon.
This study delves into public perceptions of media social responsibility within the contemporary Albanian media landscape. Through a comprehensive analysis of various factors, the study identifies the prevailing principles that the public deems crucial for the media's social responsibility and how these principles can enhance the media's contribution to society. A structured questionnaire was used to capture a wide range of public perceptions, with 1,321 questionnaires filled out. These questionnaires were distributed using a face-to-face method across five major urban centers in Albania, ensuring a comprehensive and representative sample of public viewpoints. The distribution method employed a stratified sampling approach to ensure diverse representation across different demographic groups. Additionally, employing a mixed-methods approach, the research includes qualitative interviews with 20 influential stakeholders, including media directors, professors, analysts, and media researchers. Purposive sampling was utilized to select stakeholders representing various sectors of the media landscape. Rigorous measures were taken to mitigate data pollution, including thorough interviewer training and constant monitoring of data quality. An overarching thematic analysis was conducted to identify common themes and patterns across the qualitative interviews, complementing the quantitative findings. To gain further insights, we purposefully selected and conducted a focus group with 28 journalists from various media platforms. The sampling method for the focus group involved purposive sampling to ensure representation from diverse media backgrounds and experiences. Data collected from the focus group underwent thematic analysis to identify common themes and patterns, contributing to an overarching qualitative analysis. The empirical findings reveal that the media's social responsibility in Albania does not fully adhere to the expected standards encompassing all relevant principles. Internal dynamics within media organizations and external forces from politics, economics, and society collectively influence this shortfall. The study highlights the importance of considering public perceptions and expectations in shaping media's social responsibility, emphasizing the need for substantial improvements. In conclusion, this research not only provides practical insights for media practitioners but also offers valuable perspectives for policymakers.
Keywords: media social responsibility, public perception, contemporary media landscape, transparency and accountability, Media ethics
Received: 14 Nov 2023; Accepted: 03 Apr 2024.
Copyright: © 2024 Skana and Gjerazi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
* Correspondence: Dr. Blerina Gjerazi, Aleksandër Moisiu University, Durrës, 3001-3006, Albania
People also looked at
COMMENTS
Qualitative content analysis is a research method used to analyze and interpret the content of textual data, such as written documents, interview transcripts, or other forms of communication. This guide introduces qualitative content analysis, explains the different types of qualitative content analysis, and provides a step-by-step guide for ...
Content analysis is a research method used to analyze and interpret the characteristics of various forms of communication, such as text, images, or audio. It involves systematically analyzing the content of these materials, identifying patterns, themes, and other relevant features, and drawing inferences or conclusions based on the findings.
Content analysis is a qualitative analysis method that focuses on recorded human artefacts such as manuscripts, voice recordings and journals. Content analysis investigates these written, spoken and visual artefacts without explicitly extracting data from participants - this is called unobtrusive research. In other words, with content ...
Content analysis is a research method used to identify patterns in recorded communication. To conduct content analysis, you systematically collect data from a set of texts, which can be written, oral, or visual: Books, newspapers and magazines. Speeches and interviews. Web content and social media posts. Photographs and films.
Many articles and books are available that describe qualitative research methods and provide overviews of content analysis procedures , , , , , ... The objective in qualitative content analysis is to systematically transform a large amount of text into a highly organised and concise summary of key results.
Content analyses often include counting as part of the interpretive (qualitative) process. In your own study, you may not need or want to look at all of the elements listed in table 17.1. Even in our imagined example, some are more useful than others. For example, "strategies and tactics" is a bit of a stretch here.
QDA Method #1: Qualitative Content Analysis. Content analysis is possibly the most common and straightforward QDA method. At the simplest level, content analysis is used to evaluate patterns within a piece of content (for example, words, phrases or images) or across multiple pieces of content or sources of communication. For example, a collection of newspaper articles or political speeches.
Step 1: Select the content you will analyse. Based on your research question, choose the texts that you will analyse. You need to decide: The medium (e.g., newspapers, speeches, or websites) and genre (e.g., opinion pieces, political campaign speeches, or marketing copy)
The application of qualitative methods means that a researcher is interested in studying people's experiences and perspectives in a specific social context. Content analysis is a useful qualitative analysis method due to its content-sensitive nature and ability to analyse many kinds of open data sets.
Content analysis is a research tool used to determine the presence of certain words, themes, or concepts within some given qualitative data (i.e. text). Using content analysis, researchers can quantify and analyze the presence, meanings, and relationships of such certain words, themes, or concepts.
Qualitative content analysis is a specific type of content analysis that primarily focuses on the interpretation and understanding of textual data. While it shares some similarities with its quantitative counterpart—such as the use of systematic and replicable methods—qualitative content analysis tends to dive deeper into the nuances ...
Abstract. This entry focuses on qualitative content analysis as a rule-guided method for describing and conceptualizing the meaning of qualitative data. Following a brief introduction to core characteristics of the method, the history of the method is described, including its origins in the quantitative version of the method as well as the ...
It is a flexible research method ( Anastas, 1999 ). Qualitative content analysis may use either newly collected data, existing texts and materials, or a combination of both. It may be used in exploratory, descriptive, comparative, or explanatory research designs, though its primary use is descriptive.
Qualitative, Multimethod, and Mixed Methods Research. Philipp A.E. Mayring, in International Encyclopedia of Education(Fourth Edition), 2023 Final remarks. Qualitative Content Analysis enables a systematic analysis of textual material especially important for educational research. Transcripts from open ended data collection methods present insights in inner processes of learning and development.
The types of qualitative research included: 24 case studies, 19 generic qualitative studies, and eight phenomenological studies. Notably, about half of the articles reported analyzing their qualitative data via content analysis and a constant comparative method, which was also commonly referred to as a grounded theory approach and/or inductive ...
The different qualitative content analysis methods available are not seen as distinct from other methods such as thematic analysis (Braun & Clarke, 2021a; Schreier, 2012; Vaismoradi et al., 2013). Some authors have even suggested that qualitative content analysis is only semantically different from thematic analysis (e.g., Kuckartz, 2019). This ...
Content analysis is a widely used qualitative research technique. Rather than being a single method, current applications of content analysis show three distinct approaches: conventional, directed, or summative. All three approaches are used to interpret meaning from the content of text data and, hence, adhere to the naturalistic paradigm.
Abstract. In this chapter, the focus is on ways in which content analysis can be used to investigate and describe interview and textual data. The chapter opens with a contextualization of the method and then proceeds to an examination of the role of content analysis in relation to both quantitative and qualitative modes of social research.
Step 1: Prepare the Data. Qualitative content analysis can be used to analyze various types of data, but generally the data need to be transformed into written text before analysis can start. If the data come from existing texts, the choice of the content must be justified by what you want to know (Patton, 2002).
Using qualitative interviews as an example, the book provides a clear structure for approaching your analysis that can be adapted for your research project. Explaining how qualitative content analysis differs from quantitative methods, the book provides you with: •a solid understanding of the principles behind QCA
Qualitative research involves collecting and analyzing non-numerical data (e.g., text, video, or audio) to understand concepts, opinions, or experiences. It can be used to gather in-depth insights into a problem or generate new ideas for research. Qualitative research is the opposite of quantitative research, which involves collecting and ...
Qualitative Research. Qualitative research is a type of research methodology that focuses on exploring and understanding people's beliefs, attitudes, behaviors, and experiences through the collection and analysis of non-numerical data. It seeks to answer research questions through the examination of subjective data, such as interviews, focus ...
A common starting point for qualitative content analysis is often transcribed interview texts. The objective in qualitative content analysis is to systematically transform a large amount of text into a highly organised and concise summary of key results. Analysis of the raw data from verbatim transcribed interviews to form categories or themes ...
Procedure. The procedure for this research is multi-stepped and is summarized in Fig. 1.First, we mapped retrospective qualitative data collected during the development of the SCI-HMT [] against the five domains of the CFIR in order to create a semi-structured interview guide (Step 1).Then, we used this interview guide to collect prospective data from health professionals and people with SCI ...
Third step of research: qualitative study. This phase will be a qualitative study using conventional content analysis. Sample size. Purposeful sampling will be used in this study . Sampling will continue until data saturation , i.e., no new information or data about a class or relationships between classes is revealed. Data collection
Deductive qualitative analysis (DQA; Gilgun, 2005) is a specific approach to deductive qualitative research intended to systematically test, refine, or refute theory by integrating deductive and inductive strands of inquiry.The purpose of the present paper is to provide a primer on the basic principles and practices of DQA and to exemplify the methodology using two studies that were conducted ...
The distribution method employed a stratified sampling approach to ensure diverse representation across different demographic groups. Additionally, employing a mixed-methods approach, the research includes qualitative interviews with 20 influential stakeholders, including media directors, professors, analysts, and media researchers.